Sql script replace and rearrange numbers
-
Hi everyone.
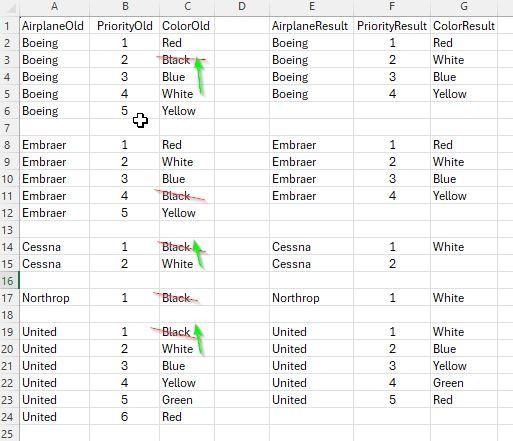
I have this table and this information. (left side of the image)

I need to replace Black with White and rearrange the numbers of the priorities. After the replacement, the numbers should be rearranged. (right side of the image)
CREATE TABLE [dbo].[Priorities](
[Airplane] [nvarchar](50) NULL,
[Priority] [int] NULL,
[Color] [nvarchar](50) NULL
) ON [PRIMARY]
GO
INSERT INTO [dbo].[Priorities]([Airplane],[Priority],[Color]) VALUES ('Boeing',1,'Red'), ('Boeing',2,'Black'), ('Boeing',3,'Blue'), ('Boeing',4,'White'), ('Boeing',5,'Yellow')
INSERT INTO [dbo].[Priorities]([Airplane],[Priority],[Color]) VALUES ('Embraer',1,'Red'), ('Embraer',2,'White'), ('Embraer',3,'Blue'), ('Embraer',4,'Black'), ('Embraer',5,'Yellow')
INSERT INTO [dbo].[Priorities]([Airplane],[Priority],[Color]) VALUES ('Cessna',1,'Black'), ('Cessna',2,'White')
INSERT INTO [dbo].[Priorities]([Airplane],[Priority],[Color]) VALUES ('Northrop',1,'Black')
INSERT INTO [dbo].[Priorities]([Airplane],[Priority],[Color]) VALUES ('United',1,'Black'), ('United',2,'White'), ('United',3,'Blue'), ('United',4,'Yellow'), ('United',5,'Green'), ('United',6,'Red')
Could anybody help me with how to achieve this rearrangement?
I really appreciate any help you can provide.
-
This gives you close to what you have asked for (but using a temp table, for convenience):
DROP TABLE IF EXISTS #Priority;
CREATE TABLE #Priority (Airplane NVARCHAR(50) NULL, Priority INT NULL, Color NVARCHAR(50) NULL);
INSERT #Priority (Airplane, Priority, Color)
VALUES
('Boeing', 1, 'Red')
,('Boeing', 2, 'Black')
,('Boeing', 3, 'Blue')
,('Boeing', 4, 'White')
,('Boeing', 5, 'Yellow')
,('Embraer', 1, 'Red')
,('Embraer', 2, 'White')
,('Embraer', 3, 'Blue')
,('Embraer', 4, 'Black')
,('Embraer', 5, 'Yellow')
,('Cessna', 1, 'Black')
,('Cessna', 2, 'White')
,('Northrop', 1, 'Black')
,('United', 1, 'Black')
,('United', 2, 'White')
,('United', 3, 'Blue')
,('United', 4, 'Yellow')
,('United', 5, 'Green')
,('United', 6, 'Red');
WITH replaced
AS
(SELECT
p.Airplane
, Priority = p.Priority
, ColorResult = REPLACE (p.Color, 'Black', 'White')
FROM #Priority p)
SELECT
r.Airplane
, PriorityResult = ROW_NUMBER () OVER (PARTITION BY r.Airplane ORDER BY MIN (r.Priority))
, r.ColorResult
FROM replaced r
GROUP BY r.Airplane
, r.ColorResult
ORDER BY r.Airplane
, PriorityResult; -
Hi Phil.
Great 🙂
Thank you. It is exactly what I need. But could you help me to persist the data? I mean not select but insert, update and get the data persisted?
-
Sure. This method creates a temp table containing the desired results & then modifies the main table via a DELETE followed by an INSERT.
If there are millions of rows in your main table, this is likely to be quite a slow process.
DROP TABLE IF EXISTS #Priority;
CREATE TABLE #Priority (Airplane NVARCHAR(50) NULL, Priority INT NULL, Color NVARCHAR(50) NULL);
INSERT INTO #Priority (Airplane, Priority, Color)
VALUES
('Boeing', 1, 'Red')
,('Boeing', 2, 'Black')
,('Boeing', 3, 'Blue')
,('Boeing', 4, 'White')
,('Boeing', 5, 'Yellow')
,('Embraer', 1, 'Red')
,('Embraer', 2, 'White')
,('Embraer', 3, 'Blue')
,('Embraer', 4, 'Black')
,('Embraer', 5, 'Yellow')
,('Cessna', 1, 'Black')
,('Cessna', 2, 'White')
,('Northrop', 1, 'Black')
,('United', 1, 'Black')
,('United', 2, 'White')
,('United', 3, 'Blue')
,('United', 4, 'Yellow')
,('United', 5, 'Green')
,('United', 6, 'Red');
DROP TABLE IF EXISTS #PriorityNew;
WITH replaced
AS
(SELECT
p.Airplane
, Priority = p.Priority
, ColorResult = REPLACE (p.Color, 'Black', 'White')
FROM #Priority p)
SELECT
r.Airplane
, PriorityResult = ROW_NUMBER () OVER (PARTITION BY r.Airplane ORDER BY MIN (r.Priority))
, r.ColorResult
INTO #PriorityNew
FROM replaced r
GROUP BY r.Airplane
, r.ColorResult;
--Remove any rows in main table which do not exist in results
DELETE trg
FROM #Priority trg
WHERE NOT EXISTS
(
SELECT 1
FROM #PriorityNew src
WHERE src.Airplane = trg.Airplane
AND src.PriorityResult = trg.Priority
AND src.ColorResult = trg.Color
);
-- Now insert missing rows to main table
INSERT #Priority (Airplane, Priority, Color)
SELECT
pn.Airplane
, pn.PriorityResult
, pn.ColorResult
FROM #PriorityNew pn
WHERE NOT EXISTS
(
SELECT 1
FROM #Priority p
WHERE p.Airplane = pn.Airplane
AND p.Priority = pn.PriorityResult
AND p.Color = pn.ColorResult
);
SELECT *
FROM #Priority p
ORDER BY p.Airplane
, p.Priority; -
Great master, thank you very much :).
I have been dealing with it a long time. You did it in a very short time. Impressive
- diegodeveloper wrote:
Great master, thank you very much :).
I have been dealing with it a long time. You did it in a very short time. Impressive
Thank you. While I may have solved this quite quickly, I have been writing SQL a very long time!
And now I am waiting for others on this forum to post even better solutions.
-
Happy Holidays to SSC! Nicely done Phil. Hmm... an issue which could potentially screw up the solution is the lack of constraint(s) on the input table. Why are all of these columns nullable? Could there be an Airplane without any Priority and/or Color? Or a Color without an Airplane? Or a Priority without an Airplane and/or Color? Also, duplicates could be problematic imo and afaik
If the input table contained non-nullable columns for which (Airplane, [Priority], Color) is a unique row key, then maybe something like this
NOTE: As per the post below the code posted was incorrect
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Instead of 3 statements: "UPDATE Color, DELETE Color='White', UPDATE Priority", these 2 statements seem equivalent and simpler: "DELETE Color='White', UPDATE Color, Priority"
NOTE: As per the post below the code posted was incorrect
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Hi Steve. Thank you for your help.
The script lack contraints because the original tables in my work are very complex, full of indexes, columns, data, constraints, and the final result comes from many joins, etc. I wrote this example to explain easier what I need and it has been very useful as I struggled a lot withot the over partition command which I was not familiar with.
I tried your example but for the Embraer brand I got a different result. Red, Blue, White, Yellow. It should be Red, White, Blue, Yellow
-
Sorry, sorry my apologies. I didn't catch the inconsistency. The green arrows in the image you posted only point up! Afaik that's the part I missed. Once there's an accepted solution I start throwing the kitchen sink at the problem 🙂 I'll put notes in my previous posts.
There are some usages of OVER PARTITION BY which I struggle with also. Some members of this site make use of a "smear" technique which I'm not fully grasping yet. There's also a (1, -1) interval combining technique which I haven't been able to get working in any solution as of yet. It's a process
Not giving up tho. Afaik this code agrees with Phil's
-- delete every 'White' row for which a 'Black' row w/higher priority exists
delete p
from #Priority p
where p.Color='White'
and exists(select 1
from #Priority pp
where pp.Airplane=p.Airplane
and pp.[Priority]<p.[Priority]
and pp.Color='Black');
-- delete every 'Black' row for which a 'White' row w/higher priority exists
delete p
from #Priority p
where p.Color='Black'
and exists(select 1
from #Priority pp
where pp.Airplane=p.Airplane
and pp.[Priority]<p.[Priority]
and pp.Color='White');
-- Fix the sequence and change remaining 'Black' rows to 'White'
with seq_cte as (
select *, row_number () over (partition by Airplane order by [Priority]) seq
from #Priority)
update seq_cte
set Color = replace(Color, 'Black', 'White'),
[Priority]=seq
where [Priority]<>seq
or Color='Black';
select * from #Priority
order by Airplane, [Priority];Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Hi Steve. Your solution works perfectly too 🙂 I am using your script and also Phil's script to implement the solution in my work database. I have been learning about over partition command and it has helped me a lot after both of you helped me with this script.
Thank you for your help. I really apreciate it.
- Steve Collins wrote:
Sorry, sorry my apologies. I didn't catch the inconsistency. The green arrows in the image you posted only point up! Afaik that's the part I missed. Once there's an accepted solution I start throwing the kitchen sink at the problem 🙂 I'll put notes in my previous posts.
There are some usages of OVER PARTITION BY which I struggle with also. Some members of this site make use of a "smear" technique which I'm not fully grasping yet. There's also a (1, -1) interval combining technique which I haven't been able to get working in any solution as of yet. It's a process
Not giving up tho. Afaik this code agrees with Phil's
-- delete every 'White' row for which a 'Black' row w/higher priority exists
delete p
from #Priority p
where p.Color='White'
and exists(select 1
from #Priority pp
where pp.Airplane=p.Airplane
and pp.[Priority]<p.[Priority]
and pp.Color='Black');
-- delete every 'Black' row for which a 'White' row w/higher priority exists
delete p
from #Priority p
where p.Color='Black'
and exists(select 1
from #Priority pp
where pp.Airplane=p.Airplane
and pp.[Priority]<p.[Priority]
and pp.Color='White');
-- Fix the sequence and change remaining 'Black' rows to 'White'
with seq_cte as (
select *, row_number () over (partition by Airplane order by [Priority]) seq
from #Priority)
update seq_cte
set Color = replace(Color, 'Black', 'White'),
[Priority]=seq
where [Priority]<>seq
or Color='Black';
select * from #Priority
order by Airplane, [Priority];You can combine the two deletes into a single delete.
WITH Combine_Colors AS
(
SELECT *, ROW_NUMBER() OVER(PARTITION BY p.Airplane ORDER BY p.[Priority]) AS rn
FROM #Priority AS p
WHERE p.Color IN ('Black', 'White')
)
DELETE Combine_Colors
WHERE rn > 1;Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - drew.allen wrote:
You can combine the two deletes into a single delete.
WITH Combine_Colors AS
(
SELECT *, ROW_NUMBER() OVER(PARTITION BY p.Airplane ORDER BY p.[Priority]) AS rn
FROM #Priority AS p
WHERE p.Color IN ('Black', 'White')
)
DELETE Combine_Colors
WHERE rn > 1;Drew
Yeah that seems like an appropriate approach. In trying to combine the two statements I had come up with this code:
delete p
from #Priority p
where p.Color in('White', 'Black')
and exists(select 1
from #Priority pp
where pp.Airplane=p.Airplane
and pp.[Priority]<p.[Priority]
and pp.Color in('White', 'Black'));Which also works but ROW_NUMBER is more generalized
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply