Speed up join
- Sergiy wrote:Jonathan AC Roberts wrote:
Well that didn't demonstrate any performance improvement from using group by.
It explained where the performance improvement comes from.
If you want to see it - just rewrite any of your DISTINCT queries running against a significant dataset to use GROUP BY instead of DISTINCT. You may not even need to set STATISTICS ON to notice the difference.
I have tried that before and not found group by to be faster.
- Scott745618 wrote:
The table does not have an index that I can use to speed up the join
This is why I previously posted what I did. There are sometimes "tricks" that can be done to speed things up with existing indexes but we don't have a prayer of helping because we don't know what indexes ARE available and we know nothing about the table, especially the datatypes of the columns involved nor even what the blasted PK of the table is. 😉
Of course, it could still end up with no resolution but, right now, the answer is a sure "NO" because we don't actually know a thing about the table except that it's fairly large.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jonathan AC Roberts wrote:Sergiy wrote:Jonathan AC Roberts wrote:
Well that didn't demonstrate any performance improvement from using group by.
It explained where the performance improvement comes from.
If you want to see it - just rewrite any of your DISTINCT queries running against a significant dataset to use GROUP BY instead of DISTINCT. You may not even need to set STATISTICS ON to notice the difference.
I have tried that before and not found group by to be faster.
Sure. And the earth is flat, as I've been told recently - with pretty much the same level of confidence.
Here is a simple script for you to execute:
CREATE TABLE #Test (N int)
CREATE INDEX TestN ON #Test(N)
INSERT INTO #Test
select N%10
FROM service.dbo.TallyGenerator (1, 10000000, null, default)
SET STATISTICS TIME ON
select distinct str(N, 9,2)
FROM #Test
SELECT str(N, 9,2)
FROM #Test
group by N
SET STATISTICS TIME OFF
DROP TABLE #TestCompare CPU times for both of the queries.
On my machine DISTINCT costs from 8 to 10 times more than GROUP BY.
What about yours?
_____________
Code for TallyGenerator - Sergiy wrote:Jonathan AC Roberts wrote:Sergiy wrote:Jonathan AC Roberts wrote:
Well that didn't demonstrate any performance improvement from using group by.
It explained where the performance improvement comes from.
If you want to see it - just rewrite any of your DISTINCT queries running against a significant dataset to use GROUP BY instead of DISTINCT. You may not even need to set STATISTICS ON to notice the difference.
I have tried that before and not found group by to be faster.
Sure. And the earth is flat, as I've been told recently - with pretty much the same level of confidence.
Here is a simple script for you to execute:
CREATE TABLE #Test (N int)
CREATE INDEX TestN ON #Test(N)
INSERT INTO #Test
select N%10
FROM service.dbo.TallyGenerator (1, 10000000, null, default)
SET STATISTICS TIME ON
select distinct str(N, 9,2)
FROM #Test
SELECT str(N, 9,2)
FROM #Test
group by N
SET STATISTICS TIME OFF
DROP TABLE #TestCompare CPU times for both of the queries.
On my machine DISTINCT costs from 8 to 10 times more than GROUP BY.
What about yours?
Yes, since your previous reply I did a bit of research and found this article by Aaron Bertrand: https://sqlperformance.com/2017/01/t-sql-queries/surprises-assumptions-group-by-distinct
It wasn't 8 to 10 times faster but 6 times more CPU and about double the elapsed time.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 2 ms.
(10 rows affected)
SQL Server Execution Times:
CPU time = 561 ms, elapsed time = 166 ms.
(10 rows affected)
SQL Server Execution Times:
CPU time = 94 ms, elapsed time = 90 ms.The solution you gave won't work as you have group by LEFT(p.plan) which isn't valid SQL:
group by p.acct, p.processdate,
m.product + m.productcode, LEFT(p.plan)You should be grouping by this:
group by p.acct, p.processdate, m.product + m.productcode,
CASE WHEN LEFT(p.plan_id,1) = 'C' then 'cash'
WHEN LEFT(p.plan_id,1) = 'B' then 'BT'
ELSE p.plan_id
ENDI tried with an example that's more similar to the OP's SQL
select N%10 N,left(convert(varchar(36),NEWID()),3) x
INTO #Test
FROM service.dbo.TallyGenerator (1, 10000000, null, default)
CREATE INDEX TestN ON #Test(N)
SET STATISTICS TIME ON
GO
SELECT DISTINCT
N,
CASE WHEN LEFT(x,1) = 'C' then 'cash'
WHEN LEFT(x,1) = 'B' then 'BT'
ELSE x
END AS balancetype
INTO #x
FROM #Test
GO
SELECT N,
CASE WHEN LEFT(x,1) = 'C' then 'cash'
WHEN LEFT(x,1) = 'B' then 'BT'
ELSE x
END AS balancetype
INTO #y
FROM #Test
GROUP BY N,CASE WHEN LEFT(x,1) = 'C' then 'cash'
WHEN LEFT(x,1) = 'B' then 'BT'
ELSE x
END
GO
SET STATISTICS TIME OFF
go
DROP TABLE #Test
DROP TABLE #x
DROP TABLE #yThere is no difference in the execution time in this case.
- Jonathan AC Roberts wrote:
There is no difference in the execution time in this case.
In this case - yes.
Because GROUP BY is applied to the output of the SELECT - making it equal to DISTINCT.
But your claim was :
I have tried that before and not found group by to be faster.
without specifying it's for some particular cases only.
My code proved that at least in some cases your claim is wrong.
So, my call would be - always choose GROUP BY before DISTINCT.
In worst case GROUP BY will be equally fast (or equally slow) as DISTINCT, in all other cases it will be significantly faster.
Would you argue that?
_____________
Code for TallyGenerator - Sergiy wrote:Jonathan AC Roberts wrote:
There is no difference in the execution time in this case.
In this case - yes. Because GROUP BY is applied to the output of the SELECT - making it equal to DISTINCT.
But your claim was :
I have tried that before and not found group by to be faster.
without specifying it's for some particular cases only.
My code proved that at least in some cases your claim is wrong.
So, my call would be - always choose GROUP BY before DISTINCT. In worst case GROUP BY will be equally fast (or equally slow) as DISTINCT, in all other cases it will be significantly faster.
Would you argue that?
Yes, it is a bit surprising (to me anyway) that group by is sometimes more efficient than distinct.
For group by to be more efficient than distinct you need a calculation on a column that would be performed many times on distinct and fewer on group by, for this to be true the calculation on the column would not have to be in the group by clause. For example, in the code you provided if you changed:
SELECT str(N, 9,2)
FROM #Test
group by Nto
SELECT str(N, 9,2)
FROM #Test
group by str(N, 9,2)Then the performance is the same as:
SELECT DISTINCT str(N, 9,2)
FROM #TestIn most SQL statements the calculated columns would be put in the group by. So your code is longer and less self-documenting than just using distinct. So I wouldn't always choose GROUP BY before DISTINCT, but each to his own.
-
For the much more straightforward approach:
SELECT DISTINCT N
vs
SELECT N
...
GROUP BY N
my machine shows a slight edge for DISTINCT. That's what I've seen in normal usage, too. For a straight list of columns, DISTINCT is usually better, but often only slightly.
For more complex expressions / lists, GROUP BY is often better.
There's no "one rule fits every query" here.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
That's what I've seen in normal usage, too
In my years working on SQL Server I extremely rarely saw a database where I could not improve performance for at least 10 times fold. Usually, the rate of improvement would by 50..100 times or more.
Would it be something we could name a "normal usage"?
Well, the statistics suggest it's pretty normal.
Should we stick with such "normality"? Well, I definitely don't want to follow that pattern.
If you're thinking in the paradigm of distinct values SELECTed by a query - your GROUP BY will not faster than DISTINCT.
But if you start thinking what records from what source you need to group together than things might become quite different. You might even think of aggregating records from a big table before joining them to another big table - I bet the machine(s) would really appreciate it. They might even spare your life after the uprising. Think about it. 🙂
_____________
Code for TallyGenerator -
Came across an actual query which gave me an idea about another version of the test script for DISTINCT vs. GROUP BY.
create table #BalanceType (
id int identity(1,1) primary key nonclustered,
TypeName nvarchar(50) UNIQUE CLUSTERED )
insert into #BalanceType(TypeName)
select 'C' union select 'B' union select 'other' union select 'D' union select 'E'
select *, convert(binary(2), NEWID()), convert(int, convert(binary(2), NEWID())), convert(int, convert(binary(2), NEWID())) % 5 + 1
from #BalanceType BT
inner join service.dbo.TallyGenerator (1, 1000, null, default) T ON BT.id = N % 5 + 1
select N%10 N, N % 5 + 1 TypeID
INTO #Accountbalance
FROM service.dbo.TallyGenerator (1, 10000000, null, default) T
inner join #BalanceType BT on BT.id = N % 5 + 1
CREATE INDEX TestN ON #Accountbalance(N)
SET STATISTICS TIME ON
GO
SELECT DISTINCT
N, balancetype
FROM #Accountbalance AB
inner join (select id,
CASE WHEN LEFT(TypeName,1) = 'C' then 'cash'
WHEN LEFT(TypeName,1) = 'B' then 'BT'
ELSE TypeName
END AS balancetype
from #BalanceType) BT ON BT.id = AB.TypeID
GO
SELECT N, balancetype
FROM #Accountbalance AB
inner join (select id,
CASE WHEN LEFT(TypeName,1) = 'C' then 'cash'
WHEN LEFT(TypeName,1) = 'B' then 'BT'
ELSE TypeName
END AS balancetype
from #BalanceType) BT ON BT.id = AB.TypeID
GROUP BY N, balancetype
GO
SET STATISTICS TIME OFF
go
DROP TABLE #Accountbalance
DROP table #BalanceTypeGROUP BY is times faster on my laptop.
_____________
Code for TallyGenerator -
If you do not know the composition of the (clustered) indexes of the huge table, how can you suggest any significant performance improvement? It will do a full table scan anyway if you are not using at least the first part(s) of one of the (clustered) indexes in your search conditions.
Gregory Liénard
If the statistics are boring, you’ve got the wrong numbers.
Microsoft Data Engineer
https://seopageoptimizer.com/: analyses billions of webpages
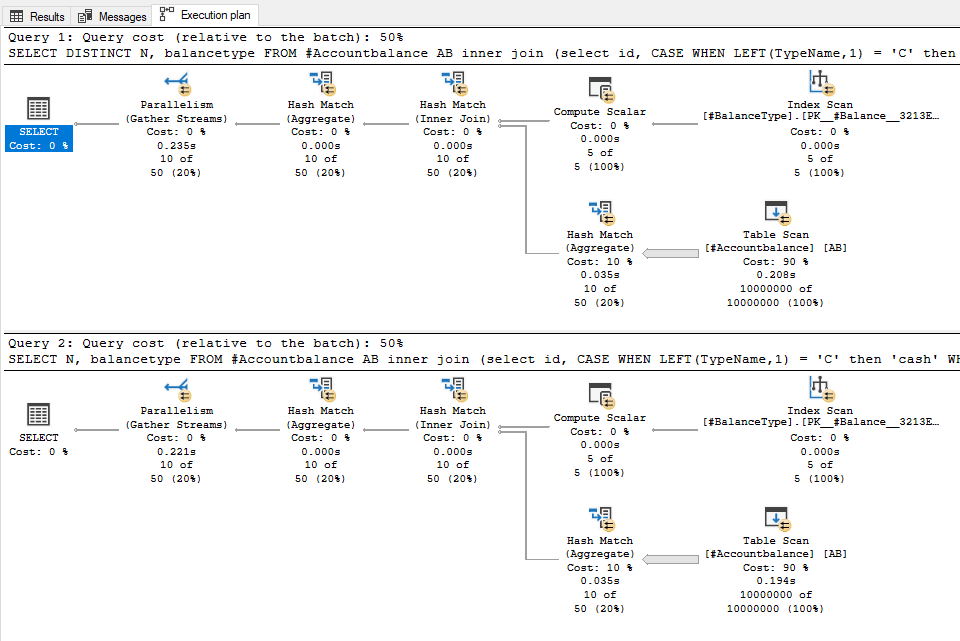
https://keyboost.com/: analyses trillions of links - Sergiy wrote:
Came across an actual query which gave me an idea about another version of the test script for DISTINCT vs. GROUP BY.
I tried it and they were about the same:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(10 rows affected)
SQL Server Execution Times:
CPU time = 750 ms, elapsed time = 244 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(10 rows affected)
SQL Server Execution Times:
CPU time = 812 ms, elapsed time = 219 ms.With the same execution plan:

- Sergiy wrote:
Came across an actual query which gave me an idea about another version of the test script for DISTINCT vs. GROUP BY.
create table #BalanceType (
id int identity(1,1) primary key nonclustered,
TypeName nvarchar(50) UNIQUE CLUSTERED )
insert into #BalanceType(TypeName)
select 'C' union select 'B' union select 'other' union select 'D' union select 'E'
select *, convert(binary(2), NEWID()), convert(int, convert(binary(2), NEWID())), convert(int, convert(binary(2), NEWID())) % 5 + 1
from #BalanceType BT
inner join service.dbo.TallyGenerator (1, 1000, null, default) T ON BT.id = N % 5 + 1
select N%10 N, N % 5 + 1 TypeID
INTO #Accountbalance
FROM service.dbo.TallyGenerator (1, 10000000, null, default) T
inner join #BalanceType BT on BT.id = N % 5 + 1
CREATE INDEX TestN ON #Accountbalance(N)
SET STATISTICS TIME ON
GO
SELECT DISTINCT
N, balancetype
FROM #Accountbalance AB
inner join (select id,
CASE WHEN LEFT(TypeName,1) = 'C' then 'cash'
WHEN LEFT(TypeName,1) = 'B' then 'BT'
ELSE TypeName
END AS balancetype
from #BalanceType) BT ON BT.id = AB.TypeID
GO
SELECT N, balancetype
FROM #Accountbalance AB
inner join (select id,
CASE WHEN LEFT(TypeName,1) = 'C' then 'cash'
WHEN LEFT(TypeName,1) = 'B' then 'BT'
ELSE TypeName
END AS balancetype
from #BalanceType) BT ON BT.id = AB.TypeID
GROUP BY N, balancetype
GO
SET STATISTICS TIME OFF
go
DROP TABLE #Accountbalance
DROP table #BalanceTypeGROUP BY is times faster on my laptop.
It's not SQL's fault if you write sloppy code. It's extremely inefficient/wasteful to create a nonclus index on #Accountbalance, which SQL can't use anyway. Therefore, I changed it to clus. After that, I get identical plans with much more efficient MERGE joins than the joins in the original plans.
Even if you don't want to / can't correct the indexes, you should add a DISTINCT to let SQL know it can remove dup rows earlier:
SELECT N, balancetype
FROM #Accountbalance AB
inner join (select distinct id, --<<-- add DISTINCT here yourself
CASE WHEN LEFT(TypeName,1) = 'C' then 'cash'
WHEN LEFT(TypeName,1) = 'B' then 'BT'
ELSE TypeName
END AS balancetype
from #BalanceType) BT ON BT.id = AB.TypeID
GROUP BY N, balancetypeSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 12 posts - 16 through 27 (of 27 total)
You must be logged in to reply to this topic. Login to reply