sp_executesql with multiple parameters
-
I'm trying to write a stored procedure that will select the entire table if all parameters are null, otherwise select the table filtered by the non-null parameters using an AND condition.
Here is some skeleton code:
DECLARE @ProjectID VARCHAR(100) = 300;
DECLARE @ProjectName VARCHAR(100) = 'Some project name';
DECLARE @sql NVARCHAR(4000) = ''
SET @sql += '
SELECT *
FROM oper.vOPERATIONAL
WHERE 1=1
@ProjectID
@ProjectName
'
SET @ProjectID='AND ProjectID='+@ProjectID;
SET @ProjectName='AND ProjectName LIKE '''+@ProjectName+'%'''
PRINT @ProjectID
PRINT @ProjectName
PRINT @sql
EXEC sp_executesql @sql, N'@ProjectID VARCHAR(100), @ProjectName VARCHAR(100)', @ProjectID, @ProjectNameAny tips on getting this to work?
Otherwise I can easily do this:
DECLARE @ProjectID VARCHAR(100) = 300;
DECLARE @ProjectName VARCHAR(100) = 'Monitoring and evaluation';
DECLARE @sql NVARCHAR(4000) = ''
SET @sql += '
SELECT *
FROM oper.vOPERATIONAL
WHERE 1=1
'
IF @ProjectID IS NOT NULL
SET @sql += 'AND ProjectID='+@ProjectID;
IF @ProjectName IS NOT NULL
SET @sql += 'AND ProjectName LIKE '''+@ProjectName+'%'' COLLATE Latin1_General_100_CI_AS'
PRINT @sql
EXEC sp_executesql @sqlor this:
DECLARE @ProjectID VARCHAR(100) = 300;
DECLARE @ProjectName VARCHAR(100) = 'Monitoring and evaluation';
DECLARE @sql NVARCHAR(4000) = ''
SET @sql += '
SELECT *
FROM oper.vOPERATIONAL
WHERE 1=1
{ProjectID}
{ProjectName}
'
SET @sql=REPLACE(@sql,'{ProjectID}',IIF(@ProjectID IS NULL,'','AND ProjectID='+@ProjectID))
SET @sql=REPLACE(@sql,'{ProjectName}',IIF(@ProjectName IS NULL,'','AND ProjectName LIKE '''+@ProjectName+'%'' COLLATE Latin1_General_100_CI_AS'))
PRINT @sql
EXEC sp_executesql @sqlBut AFAIK this isn't best practice.
Comments:
- The table is tiny (~ 1000 rows) - I'm not worried about query caching or optimization.
- It's an internal SP - I'm not worried about injection attacks. The end users could delete the entire table if they wanted.
Still, I'm happy to follow best practice if I can get the first approach to work.
-
There are only 4 input scenarios? If so it's just as easy to not use dynamic sql. This proc allows null inputs and filters in 4 ways (including no filter):
drop table if exists test_table;
go
create table test_table(
projectidvarchar(100),
projectnamevarchar(100));
go
insert test_table(projectid, projectname) values ('xxx','xxy'), ('xxx','zzy'), ('yyy','xxy'), ('yyx','yzz');
go
drop proc if exists dbo.proc_test;
go
create proc dbo.proc_test
@projectidvarchar(100)=null,
@projectnamevarchar(100)=null
as
set nocount on;
if @projectid is null
begin
if @projectname is null
select * from test_table;
else
select * from test_table where projectname like '%'+@projectname+'%';
end
else
begin
if @projectname is null
select * from test_table where projectid=@projectid;
else
select * from test_table where projectid=@projectid and projectname like '%'+@projectname+'%';
end
go
exec dbo.proc_test;
exec dbo.proc_test null, 'z';
exec dbo.proc_test 'yyx', 'x';
exec dbo.proc_test 'yyx', null;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
This is how I handle variable inputs
DECLARE @ProjectID int = 300;
DECLARE @ProjectName varchar(100) = 'Some project name';
DECLARE @sql nvarchar(4000) = N'';
SET @sql += N'
SELECT *
FROM oper.vOPERATIONAL
WHERE 1=1';
IF ( @ProjectID ) IS NOT NULL
BEGIN
SET @sql += ' AND ProjectID = @ProjectID';
END;
IF ( @ProjectName ) IS NOT NULL
BEGIN
SET @ProjectName += '%';
SET @sql += ' AND ProjectID LIKE @ProjectID';
END;
PRINT @sql;
EXEC sys.sp_executesql @stmt = @sql
, @params = N'@ProjectID int, @ProjectName VARCHAR(100)'
, @ProjectID = @ProjectID
, @ProjectName = @ProjectName; -
Going over to scdecade's solution and doing a bit of tweaking to it, would this not work:
DROP TABLE IF EXISTS test_table;
GO
CREATE TABLE [test_table]
(
[projectid] VARCHAR(100)
, [projectname] VARCHAR(100)
);
GO
INSERT [test_table]
(
[projectid]
, [projectname]
)
VALUES
(
'xxx'
, 'xxy'
)
, (
'xxx'
, 'zzy'
)
, (
'yyy'
, 'xxy'
)
, (
'yyx'
, 'yzz'
);
GO
DROP PROC IF EXISTS dbo.proc_test;
GO
CREATE PROC [dbo].[proc_test]
@projectid VARCHAR(100) = NULL
, @projectname VARCHAR(100) = NULL
AS
SET NOCOUNT ON;
SELECT
[projectid]
, [projectname]
FROM [test_table]
WHERE [projectname] LIKE '%' + ISNULL( @projectname
, [projectname]
) + '%'
AND [projectid] = ISNULL( @projectid
, [projectid]
);
EXEC [dbo].[proc_test];
EXEC [dbo].[proc_test]
NULL
, 'z';
EXEC [dbo].[proc_test]
'yyx'
, 'x';
EXEC [dbo].[proc_test]
'yyx'
, NULL;From what I can tell, the above does the same thing, just using ISNULL instead of a bunch of IF statements. Provides you with the same results as your original request, no?
I personally try to avoid using dynamic SQL if at all possible. SOMETIMES it is needed, but in this case, I don't see how the dynamic SQL is helpful.
If Dynamic SQL is required (ie the skeleton code is dumbed down), then DesNorton's method is my usual route. Or failing that, I build the entire SQL string into a single variable and pass that along to sp_executesql. Depends on if I need it to be parameterized or not.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Don't use functions in a WHERE clause if you can avoid it, as they destroy "sargability".
In this case, just directly check each variable for NULL or a match, as below. You don't need dynamic SQL in any way. If in certain specific cases you want to add a %(s) to the variable, do that before the SQL statement because it's more flexible and thus easier to maintain.
SELECT *
FROM oper.vOPERATIONAL
WHERE
(@ProjectID IS NULL OR ProjectID LIKE @ProjectID) AND
(@ProjectName IS NULL OR ProjectName LIKE @ProjectName) /*AND ...*/While it's not likely SQL could do seeks on this type of code, it's possible index intersection could be used, so it's better to maintain sargability just in case.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Don't use functions in a WHERE clause if you can avoid it, as they destroy "sargability".
In this case, just directly check each variable for NULL or a match, as below. You don't need dynamic SQL in any way. If in certain specific cases you want to add a %(s) to the variable, do that before the SQL statement because it's more flexible and thus easier to maintain.
SELECT *
FROM oper.vOPERATIONAL
WHERE
(@ProjectID IS NULL OR ProjectID LIKE @ProjectID) AND
(@ProjectName IS NULL OR ProjectName LIKE @ProjectName) /*AND ...*/While it's not likely SQL could do seeks on this type of code, it's possible index intersection could be used, so it's better to maintain sargability just in case.
The downside of using this approach, is that it forces a scan instead of a seek. The reason is that SQL does not short-circuit the OR, and has to evaluate the "@ProjectID IS NULL" against every record in the index/table that it has chosen.
Create 10000 rows of test data
CREATE TABLE dbo.[test_table] (
projectid int NOT NULL
, projectname varchar(100) NOT NULL
);
GO
SET NOCOUNT ON;
;WITH T(N) AS (SELECT N FROM (VALUES (0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS X(N))
, NUMS(N) AS (SELECT TOP(10000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM T T1,T T2,T T3,T T4,T T5,T T6,T T7,T T8,T T9)
INSERT INTO dbo.[test_table] (projectid, projectname)
SELECT
projectid = NM.N
, projectname = LOWER(RIGHT(REPLACE(CONVERT(VARCHAR(36), NEWID()), '-', ''), ABS(CHECKSUM(NEWID())%30)+15))
FROM NUMS AS NM
OPTION (RECOMPILE);
GO
ALTER TABLE dbo.[test_table]
ADD PRIMARY KEY CLUSTERED (projectid);
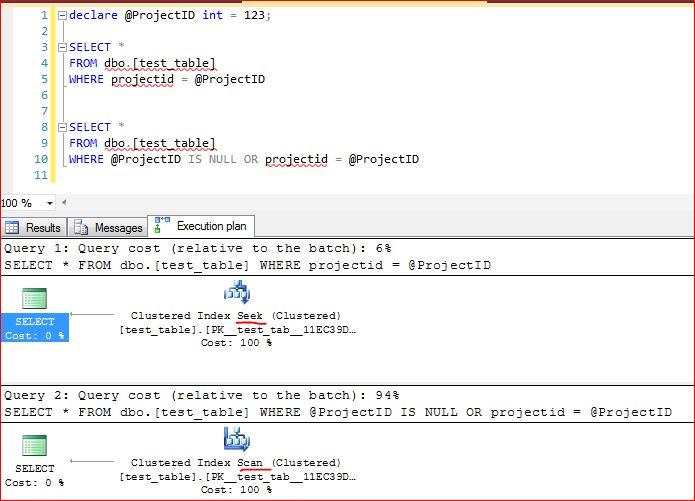
GOQuery the test data, using the clustered key. Note the change from a seek to a scan.

-
The major problem with your first query is that it doesn't satisfy the original conditions to: select all rows if the value is NULL. Other than dynamic SQL, the scan is nearly unavoidable in these situations, given how the SQL optimizer works. It's unfortunate that, at least as of now, the optimizer cannot do a better job of avoiding an unnecessary scan in that case.
Stated by OP:
The table is tiny.
I've seen the article(s) on this topic and I understand the concerns. To me, it depends on the specifics. Given the specified requirements, and if even 1/4+ of the time I'm returning the whole table anyway, then I wouldn't be concerned with a scan.
Of course dynamic SQL might avoid a scan, since it will have WHERE for only those params actually specified. However, for a tiny table, it's probably worth the extra effort to generate and maintain dynamic code. Moreover, using ISNULL() in the WHERE of dynamic SQL would force a scan anyway, so you'd get the worst of both worlds: dynamic SQL and a scan.
Yes, tables can grow, but usually not that dramatically. If it does, I'll engineer more than, rather than over-engineer for everything on the front-end.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
The best performance would be to create 4 procedures, 1 calling and 3 for each contingency. Each of the 3 would have an execution plan optimized for the workload.
-
Thanks for all the replies 🙂
@ScottPletcher: D'oh! Sometimes you just don't see what's obvious.
@DesNorton:
The reason is that SQL does not short-circuit the OR, and has to evaluate the "@ProjectID IS NULL" against every record in the index/table that it has chosen.
Most of the columns will be NOT NULL, would that improve performance?
When posting to a forum, it's always a tradeoff between brevity vs. not enough context.
So here's more context:
Right now we have a really clunky (IMO) flattened operational table. A record gets written each time an end user runs a particular program. They are run on an adhoc, manual basis. Over the course of say 4 years the table has about 1200 rows.
Right now the business process is they create variables (text) in the programming interface (SAS Enterprise Guide) and submit the program. Thus there is a lot of junk in that table due to bad variable text.
The business model is:
Source: The source of (health) data. The sources are Admitted Patients, Emergency Department, Deaths, and Cause of Death. So only 4 rows.
Project: A project authorized for a given source. A project is generally a request for data from researchers that has been approved by an ethics committee. So, a project's parent is source.
Service: A particular service against a project. That could be repeated requests for data (say a data refresh), or a new service (completely different request but still pertaining to that project). So, a service's parent is project.
Batch: This is a particular run of the service. Multiple batches (rows) usually mean a repeated run of the code, say due to programming errors, etc. This table also captures metrics, such as run dates and row counts. So, a batch's parent is service.
The structure is a bit like a file system:
Source
Project
Service
BatchIn this example, the Batch data is analogous to a fact table. IOW the number of rows in the Batch table should be the maimum number of rows in the operational table (view), and the upstream tables, once remodeled, will have unique rows per service/project/source.
I'm working on 1) normalizing the tables into 4 separate tables, and 2) creating a crude interface that will make it easier for the end user to keep from shooting him/herself in the foot with bad data settings, and easier for us to clean up data when they do. Identity columns and FK constraints will enforce cross tabular data integrity, and a view will flatten out the data.
Say the SP is named spGetProject. These are scenarios that I envision:
exec spGetProject:
Return all rows in the table. The user then scans the output for an obvious match on an existing project.
exec spGetProject @ProjectID=300:
Returns all rows matching that ProjectID
exec spGetProject @ProjectID=300, @ServiceID=100:
Returns all rows matching that ProjectID and ServiceID
exec spGetProject @ProjectName='Some Project', @ServiceCode='ABC123':
You get the idea
exec spNewProject
@ProjectName='...'
,@ProjectDesc='...'
,@FileReferenceNum='AK/47'
,@ServiceCode='M/16'
,<any other required columns>
After scanning for an existing project and/or service,
the end user determines that he/she needs to create a new Project+Service.
There will be separate (cloned) SP's in separate databases that will set the correct SourceID.
In fact the SourceID could just be a computed column in the appropriate database
or coded as a constant in the view.The business logic is you *always* search for a matching Project+Service. If required, you create the new Project+Service via a SP that implements some error checking, and the newly created row (ProjectSK + ServiceSK) is your setting for this new run.
The interface is crude - I'd prefer to create a .Net form that would provide a picklist interface, but my boss looked at me like I had three heads. Sigh...
By breaking up the tables, they will be easier to keep clean since the data isn't repeated across rows (i.e. ProjectName and ProjectDesc repeated multiple times). If an error occurs, I can go in and fix the FKs in a downstream table then remove the bogus upstream row. Plus unique indexes will help with preventing double loading of the same data.
I do believe the table will stay very small, and a scan will give sufficient performance. I doubt my end users would know how to do an injection attack, let alone try one. Plus they can delete the rows in this table anyway (I don't control the security - IMO they should be allowed to insert rows but not delete them, but that would completely confuse my DBA).
Hope the context helps - I was probably too brief in my first post and too wordy in this one ;-).
- Scott In Sydney wrote:
Thanks for all the replies 🙂
@DesNorton:
The reason is that SQL does not short-circuit the OR, and has to evaluate the "@ProjectID IS NULL" against every record in the index/table that it has chosen.
Most of the columns will be NOT NULL, would that improve performance?
It's not about the nullability of the data in the table. It is about SQL having to compare the value of the variable @ProjectID against every record in the index/table.
Viewing 10 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply