Slow update on temp table
-
I have a job running each night starting at 4:30AM and usually finishing at around 6:30AM or shortly thereafter doing some number crunching.
Occasionally, this job slows down taking much longer...today it ran until about 8:45AM.
This statement, normally would take a second or two...the table is about 250,000 rows with 8 columns...today it took about 15 minutes for almost exactly the same number of rows:
UPDATE #temptable
SET avol = CASE WHEN uvol >= hvol
THEN (uvol - ISNULL(hvol,0)) / factor
ELSE 0
ENDWe collect statistics from sys.dm_exec_requests every 20 seconds (using an old tool called DMVStats). During the 15 minutes it ran today, for the SPID performing the above query, the statistics reported were:

etc.
- Does this indicate a problem with TEMPDB contention or is it somehow just a red herring?
- The same query when run the day before had no wait_resource entries.
- For the entire workload today there were 755 similar wait_resource rows...the previous day just 3 (they both run the same code, just for different daily data of the same size).
- The wait_type is NULL and wait_time is 0 so maybe there's nothing to consider, but why is there a wait_resource entry (I presume that's on the #temptable)?
During the time this job was running, I see nothing odd about the number of other tasks that were running at the same time or signs of heavy activity. There were no indications of blocking by other SPIDs.
I'm thinking of enabling the query store for the database so at least I can see whether the plans have degraded.
Can someone recommend anything else (monitoring, extended events) I can put in place to try and solve this mystery?
Thanks much for any help.
-
I know some folks will say they can help you but only if you supply the Plan Metrics so you might consider adding that in since you do not want to be barking up the wrong tree.
Still my first question would be is this Temp Table got an Index to it? Where the uvol and hvol are at least included?
-
Some older queries that worked fine in the past do not do well on SQL Server 2014 and up due to changes in the cardinality estimator. You can force a query to use the legacy cardinality estimator with
OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
I had to do that for some queries that worked well from SQL200 through SQL2012, but would run forever on SQL2019
-
Another possibility is, assuming that:
(1) column avol was NULL before this UPDATE
(2) your server still has the default FILLFACTOR 0f 0 (=100)
Then this UPDATE could a lot of leaf page splits, even every page to split.
You should probably try rebuilding the temp table after the initial load with a FILLFACTOR that allows this column to be populated from NULL to a value without requiring the page to split.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
Another possibility is, assuming that:
(1) column avol was NULL before this UPDATE
(2) your server still has the default FILLFACTOR 0f 0 (=100)
Then this UPDATE could a lot of leaf page splits, even every page to split.
You should probably try rebuilding the temp table after the initial load with a FILLFACTOR that allows this column to be populated from NULL to a value without requiring the page to split.
I think that it works in a different way. Each row has a bitmap for null values, and the space that the datatype should use is reserved even if there is a null value (unless we are using spars columns). This means that even if everything was null and then was modified to have a different value, no page splits should occur (unless we are updating the column that a clustered index is based on it).
Adi
-
If avol is actually numeric. If it's varchar, could be an issue.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
There could be many reasons why the update takes longer some times vs other times - some of which have already been discussed. With that said I would avoid the issue in the first place and move that update into the code that creates the temp table.
The first thing I would try is a computed column - since the update is a simple CASE expression based on other columns a computed column should work. If that isn't possible (because the other columns are part of a prior update statement - for example), then I would work on getting those included in the original creation as well.
In most cases, the reason for the update is because the values that are needed to create the value in the other column are calculated - and repeating the calculation becomes cumbersome. That can be easily overcome using CROSS/OUTER APPLY in the original creation of the temp table.
Can't be much more specific without seeing the other code - but I have refactored code like this before and reduced overall performance significantly by getting rid of the post updates to the table(s).
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
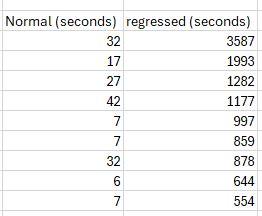
Thanks for all answers received. I have investigated further and it appears we're running into multiple regressed queries throughout the workload:
I've been reluctant to enable the query store on this database due to overhead, but it looks like it has to be done. I don't know if we'll use it to force plans...I'd rather not, but I would like to know why the plans are suddenly going awry. This code has been running for years on a pretty powerful server, slowly but surely though, more and more load has been put on it.
My understanding is that the SQL Server optimizer will fall to bad plans due to overall system load. It'd be nice to know if the server is particularly stressed before plans regress. Are there any tools, metrics available that can help with that? The Activity Monitor has never been that helpful and although I'm collecting vast amounts of statistics from the DMVs, I've never been able to examine them and say, "hey, my server is about to fall over".
Thanks for any and all input.

Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply