Recursive Select runs slow
-
Hello,
I have a recursive Select that runs ultra slow. My test table has only 100 entries and I've aborted the execution after almost an hour execution time. Here's a dbFiddle: https://dbfiddle.uk/?rdbms=sqlserver_2017&fiddle=51f892882939d51f4c6ab96ac024cbfd
The second box in the fiddle shows the whole Select and the third box shows the recursive select that causes the bad performance. I think the problem is, that the recursive Select processes all entries multiple times. Do you have an idea how to improve performance? Or do you have a better approach to solve my task?
What I want to achieve
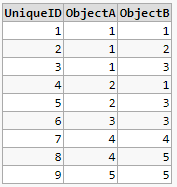
I have a table with object links and the task is "Find a bundle with number less than X". The starting point doesn't matter, but the bundle must always contain ALL entries for ObjectA and ALL for ObjectB.
Examples for possible bundles

- If you start with UniqueID = 1 then the entries with UniqueID 1 - 6 should be selected. The same result should be given when you start with UniqueID 2,3,4,5,6.
- If you start with UniqueID = 7, the entries with UniqueID 7-9 should be selected. The same result should be given when you start with UniqueID 8,9.
Then let's say I search a bundle with number of rows less than 10, then should the first bundle be selected, that meets this condition - e.g. the first bundle (UniqueID 1-6).
If I search a bundle with number of rows less than 5, then should the second bundle (UniqueID 7,8,9) be selected, because the first one has 6 rows.
Thanks, Soleya
-
Okay... let's restate the problem. What you posted as the "task" is: "Find a bundle with number less than X".
Not sure exactly what that means, as neither "bundle", nor "number" is defined anywhere in your post. I can pick up on the word number from context that the "bundle" has less than X rows. However, while I have an idea about what bundle might mean, I am not at all sure I'm right. It would appear, and from context, that a "bundle", is all rows that, starting from a given UniqueID value, that share any of the ObjectA or ObjectB values as any other row's UniqueID or ObjectA or ObjectB values. However, without a rather larger example set to work with, it's not certain that it might not simply be "any other row's ObjectA or ObjectB values. This would make a difference. And, does the data always follow the kind of pattern established, in that all rows in a bundle are consecutive in terms of UniqueID value? Until these questions are answered with certainty, I'd hesitate to try and start coding something when the right approach might require that I throw away all the previous work.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
I'd forget recursion for this for now, maybe try a more "loopy" approach:
USE tempdb;
DROP TABLE IF EXISTS dbo.objectLinks;
CREATE TABLE dbo.objectLinks (
UniqueID int IDENTITY(1,1) NOT NULL,
ObjectA int NOT NULL,
ObjectB int NOT NULL
);
ALTER TABLE dbo.objectLinks ADD CONSTRAINT objectLinks__PK PRIMARY KEY ( UniqueID ) WITH ( DATA_COMPRESSION = ROW, FILLFACTOR = 99 );
SET NOCOUNT ON;
TRUNCATE TABLE dbo.objectLinks
INSERT INTO dbo.objectLinks (ObjectA, ObjectB)
VALUES (1, 1), (1, 2), (1, 3), (2, 1), (2, 3), (3, 3), (4, 4), (4, 5), (5, 5);
SET NOCOUNT OFF;
DROP TABLE IF EXISTS #bundles
GO
CREATE TABLE #bundles (
UniqueId int NOT NULL PRIMARY KEY,
ObjectA int NOT NULL,
ObjectB int NOT NULL,
Pass# smallint NOT NULL,
has_been_processed bit NOT NULL DEFAULT 0
)
GO
DECLARE @MaxUniqueID int
DECLARE @NewObjectsFound int
DECLARE @ObjectA int
DECLARE @ObjectB int
DECLARE @Pass# smallint
DECLARE @UniqueID int
SELECT @UniqueId = Min(uniqueid),
@MaxUniqueId = Max(uniqueid)
FROM dbo.objectLinks
WHILE @UniqueID <= @MaxUniqueID
BEGIN
TRUNCATE TABLE #bundles;
SET @Pass# = 1
INSERT INTO #bundles ( UniqueID, ObjectA, ObjectB, Pass#, has_been_processed )
SELECT UniqueID, ObjectA, ObjectB, @Pass#, 0
FROM dbo.objectLinks
WHERE UniqueID = @UniqueID
SET @NewObjectsFound = @@ROWCOUNT
WHILE @NewObjectsFound > 0
BEGIN
SET @Pass# = @Pass# + 1
INSERT INTO #bundles ( UniqueID, ObjectA, ObjectB, Pass#, has_been_processed )
SELECT oL.UniqueID, oL.ObjectA, oL.ObjectB, @Pass#, 0
FROM dbo.objectLinks oL
WHERE
NOT EXISTS(
SELECT 1
FROM #bundles b
WHERE b.UniqueId = oL.UniqueID
) AND
EXISTS(
SELECT 1
FROM #bundles b
WHERE b.has_been_processed = 0 AND
((oL.ObjectA IN (b.ObjectA, b.ObjectB)) OR
(oL.ObjectB IN (b.ObjectA, b.ObjectB)))
)
SET @NewObjectsFound = @@ROWCOUNT
--/*
UPDATE #bundles
SET has_been_processed = 1
WHERE Pass# = @Pass# - 1
--*/
END /*WHILE*/
SELECT *, @UniqueID AS OriginalUniqueId
FROM #bundles
SET @UniqueID = @UniqueID + 1
END /*WHILE*/SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
@sgmunson - Sorry for the bad test data and ambiguities.
@ScottPletcher - I've tested your approach and it's much faster. It runs 5 seconds for my test table with 100 entries. Thank you so much for your help, you saved my day :).
-
Nicely done, Scott... I had a funny feeling that there was no way to make recursion work for this, and that some kind of loop was likely a necessity. My brain also went down the road of adding a column to represent a "BundleID", and then tried to think of a way to use a difference in ROW_NUMBER() values to identify a particular bundle. That identification just wasn't going to happen with recursion, and there didn't really appear to be a set-based way to identify the bundle at all, so I gave up and posted for clarification, as I wasn't even sure I had the rules down for identifying a given bundle, as they weren't specifically stated.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
Thanks all.
Yeah, normally I too try to avoid loops, but in this case, it's probably better just to loop.
For absolute max efficiency, you can uncomment the UPDATE #bundles statement, although unless you have a LOT of bundles, it's likely to make very little actual difference.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply