Partitioned Heap Table
-
On SQL Server 2016,
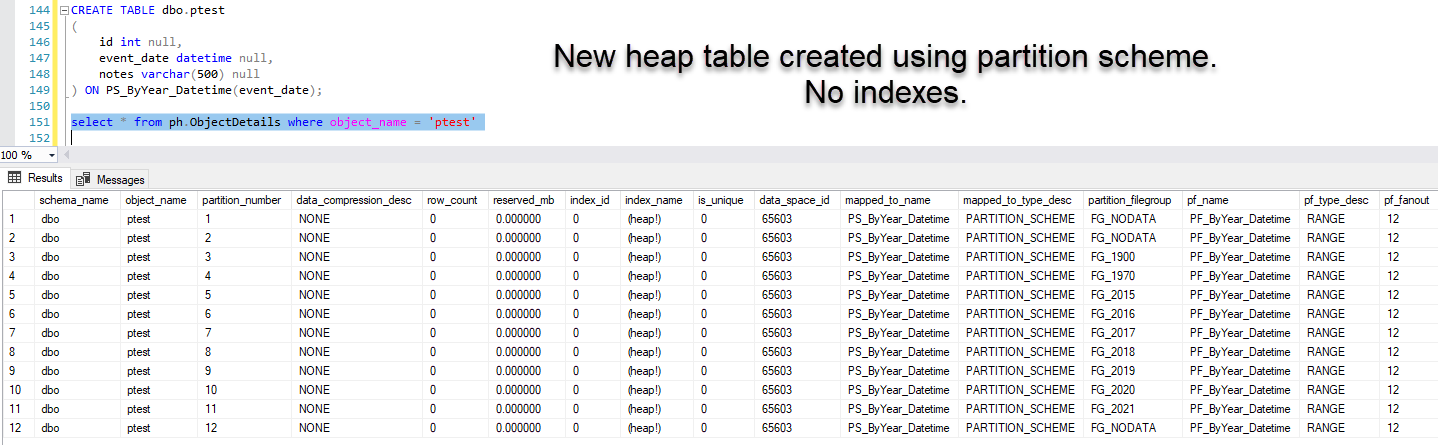
I have a HEAP table that is partitioned on a scheme. Definition looks something like this
CREATE TABLE [dbo].[PartitionedHeapTable]
(
[id] INT NULL,
[event_date] DATETIME2(7) NULL,
[record_desc] VARCHAR(500) NULL
) ON [PS_ByYear_Datetime2]([event_date])There are no indexes on this table.
If a new record is inserted, will the partition scheme be honored/used to decide which filegroup the data will be written to, even though there is no clustered index defined?
-
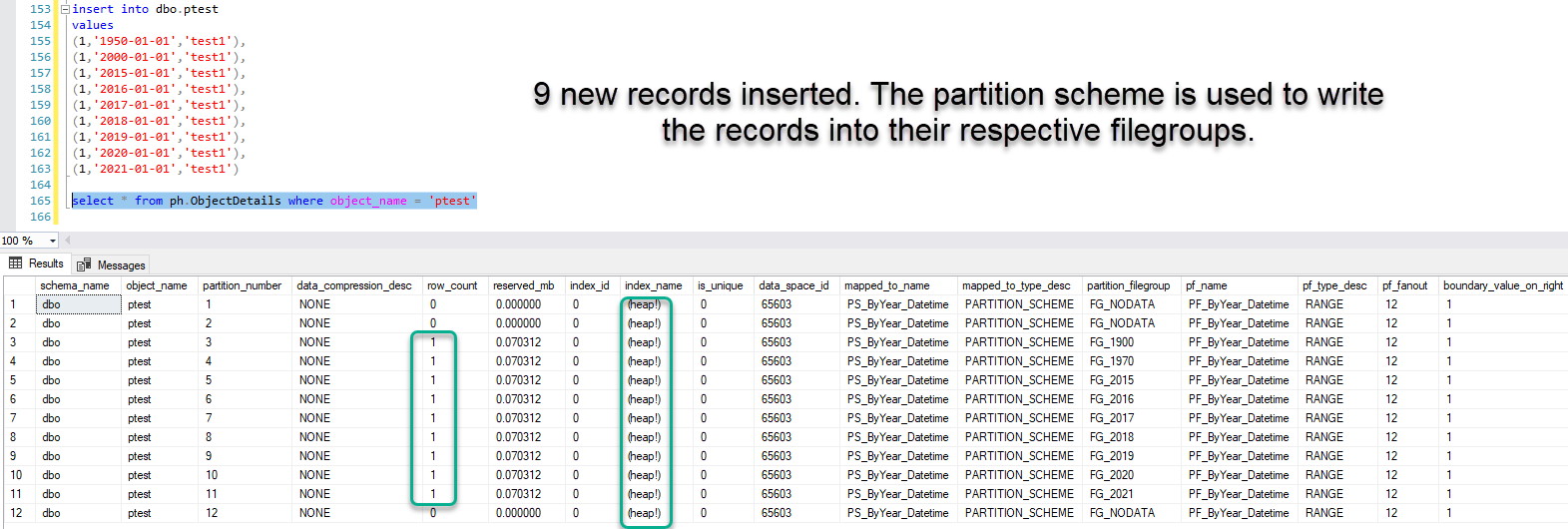
So, stopped being lazy for five minutes, and tested this myself. Indeed, the partition scheme is used to insert new records into such a heap table. Clustered index is not required.
A clustered index was used to move the data to their respective filegroups when the partition scheme was defined for the first time on the heap table. Then the clustered index was dropped. After dropping the clustered index, the partition scheme is still used for new records.

I suppose this would work for later versions of SQL Server, but I have not tested that.
-
I'm just curious... Do you ever do SELECTs from this partitioned HEAP? Do you ever UPDATE any of the rows in the HEAP? What's the HEAP actually used for? It looks like it's a WORM history table.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Very good question, Jeff. Thanks for asking. And you're spot on.
These tables are part of a data warehouse solution and their sole purpose is to store all the data that comes in through the ingress process from many different data sources in case part of the DW database needs to be rebuilt. It is very rare that these tables are queried and only when there is an issue to resolve. Indexes are added to the very large table if needed during that time. They are kept as heaps to make the insert as fast as possible to shorten the data load process. Hope that answers your question.
- qbrt wrote:
Hope that answers your question.
It does, indeed. Thanks for the feedback.
As a bit of a sidebar and especially since the partitioning is done on a temporal column, consider a strategy like 1 filegroup with 1 file per quarter and then make the older file groups READ_ONLY. This will keep you from having to do backups on data that will never again change.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
As a bit of a sidebar and especially since the partitioning is done on a temporal column, consider a strategy like 1 filegroup with 1 file per quarter and then make the older file groups READ_ONLY. This will keep you from having to do backups on data that will never again change.
That's a great suggestion. I will look into its feasibility in our environment. Thank you.
Viewing 6 posts - 1 through 6 (of 6 total)
You must be logged in to reply to this topic. Login to reply