Merge Conflicts with SQL Server Database Project
-
I hope someone more familiar with database projects can provide me some guidance.
I am currently trying to introduce a better source control solution and automated deployment solution for a project I have joined.
The current state is I have a database project in Visual Studio 2019 which will be used to maintain an Azure SQL Database. When a single developer is using the project they will do the following to made changes.
- Clone the Azure repo master branch to their local host
- Create a new feature branch
- Add their changes, commit and push the changes back to the repo
- Create a pull request to merge the changes
- PR is merged
- Azure pipeline is triggered to build the database project and create an artifact for deployment
- Azure release pipeline is triggered to deploy the database change to the Azure SQL DB
Now the above works fine when changes are being implemented by a single developer, however when changes are being made to the same repo by multiple developers each on their own feature branch once the PR is created we are encountering merge conflicts on the .sqlproj file and .refactorlog file. This makes sense as although they may have been working on unrelated files such as new sql files for table creation or procedure modifications these changes are also refeclected in their own copy of the project and refactor log files. When trying to merge their PR's a conflict is always likely as those files are being modified by sepearte PR's.
Has anyone any experience of preventing these merge conflicts to the master branch where you have multiple developers all working on the same repo but from different feature branches?
MCITP SQL 2005, MCSA SQL 2012
-
After each merge make the remaining teams (with unmerged code) pull from the master (or the newer, more pc, 'main') branch. The team with the least seniority makes the last merge 🙂
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Hi Steve I'm not sure I fully understand you suggestion. Take this scenario:
- DevA creates a new feature branch from master
- DevB also creates a new feature branch from master
- Both of the above have the same starting point (i.e. both createed their feature branch from master at the same commit state)
- DevA adds a new procedure, commits and creates a PR to merge their changes to master
- DevB adds a new procedure, commits and creates a PR to merge their changes to master
At this point there is 2 PR's raised, neither has been reviewed or approved yet for merge to master.
The PR for DevA will merge without issue as raised first so is approved and merged.
The PR for DevB will now no longer merge successfully due to the merge conflict caused by the merge of DevA's PR.
Are you saying that DevB should now merge master into their branch so that they will have all commits added to master since their feature branch was created? If you are this then also causes a merge conflict on the feature branch with the same two files as they have changed in master and in the feature branch.
Ideally I am trying to establish if it's possible to avoid the merge conflicts entirely but still have a working project that will sucessfully build.
MCITP SQL 2005, MCSA SQL 2012
-
Just a note after some further testing, in the example above merging master into the DevB PR does resolve the PR merge conflict. In this case I have to choose the merge option of keeping both changes, its not ideal as it gets messing if the PR has lots of changes but could potentially work as a compromise.
MCITP SQL 2005, MCSA SQL 2012
-
For independent groups to modify the same set of objects and end up with code which combines the best elements of each somehow the merge conflicts must be dealt with, no? If you get all of the teams in a room/zoom and proceed to merge multiple pull requests into the same master trying to do so hierarchically by seniority would quickly become ridiculous. That was sarcasm. Actual teamwork could/should occur to determine a good way forward. Hopefully. Hopefully teamwork already happened to reduce the necessity for multiple teams to modify the same object(s) independently. You could try to batch up changes (perhaps with an impressive label, like an "agile push", or "git flow arc") and then get everyone in a room/zoom. If you split apart #4 and #5 on the list, then perhaps both "merge their changes to master" could be #6 room/zoom. Otherwise, my post suggested a "hub and spoke" approach where git pulls from master/main are made in succession so each team handles merges back into their own branch. In theory the last merge would be without conflict. Actual teamwork imo works well when given a chance 🙂 because the alternative is not as good
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
one way of doing it
Merge manager should decide (within team) which change should go first
developer A
--> Local -- Remote
--> Master -- master
--> project_change_A - created from the local copy of master
--> push to remote - new branch
--> create merge request onto master (Remote)
developer B
--> Local -- Remote
--> Master -- master
--> project_change_B - created from the local copy of master
--> push to remote - new branch
--> create merge request onto master (Remote)
Merge Manager
--> Merge from Dev A is accepted and merged onto remote master
--> Merge from Dev B now has conflicts - Rejects Merge
--< Dev B must apply new changes to their local branch and push to remote again
--> Deletes project_change_A from remote - Dev A should remove it also from local
Developer B
--> refreshes local copy of master - now includes changes from DevA
--> Merge local master onto project_change_B
--> push to remote - overrides previously created branch
--> create merge request onto master (Remote)
Merge Manager
--> Merge from Dev B is accepted and merged onto remote master
--> Deletes project_change_B from remote - Dev B should remove it also from local -
I understand what you are saying but in this particular instance the developers are working in isolation on seperate objects within seperate schemas and due to the nature of how database projects work in VS it does not lend itself to parrallel development on seperate branches.
Take my example above:
DevA adds a single file to the project in the location schema1\Tables\t_fancyfeature1.sql
DevB adds a single file to the project in the location schema37\Tables\t_fancyfeature37.sql
Neither is working within the same schema or indeed the same files however each time a file is added to a Visual Studio Database Project an entry for each new file is added to the .sqlproj file automatically as a result of the developers actions of adding an object rather than something that perform themself.
In the case of DevA the .sqlproj file has been modified by visual studio itself adding these 3 lines, lets say at lines 30,31 and 32 in the file
<ItemGroup>
<Build Include="schema1\Tables\t_fancyfeature1.sql" />
<ItemGroup>In the case of DevB the same file has been modified but as it is not aware of the additions from the other branch which has not yet been merged to master it also adds 3 lines at the same line numbers
<ItemGroup>
<Build Include="schema37\Tables\t_fancyfeature37.sql" />
<ItemGroup>Whilst your points are entirely valid if various developers were actively modifying the same files I would agree its a co-ordination and communication issue but in this case, in my opinion it is an issue with how database projects in visual studio do not lend themselves to concurrent development utilising a feature branch method.
MCITP SQL 2005, MCSA SQL 2012
- frederico_fonseca wrote:
one way of doing it
Merge manager should decide (within team) which change should go first
developer A
--> Local -- Remote
--> Master -- master
--> project_change_A - created from the local copy of master
--> push to remote - new branch
--> create merge request onto master (Remote)
developer B
--> Local -- Remote
--> Master -- master
--> project_change_B - created from the local copy of master
--> push to remote - new branch
--> create merge request onto master (Remote)
Merge Manager
--> Merge from Dev A is accepted and merged onto remote master
--> Merge from Dev B now has conflicts - Rejects Merge
--< Dev B must apply new changes to their local branch and push to remote again
--> Deletes project_change_A from remote - Dev A should remove it also from local
Developer B
--> refreshes local copy of master - now includes changes from DevA
--> Merge local master onto project_change_B
--> push to remote - overrides previously created branch
--> create merge request onto master (Remote)
Merge Manager
--> Merge from Dev B is accepted and merged onto remote master
--> Deletes project_change_B from remote - Dev B should remove it also from localThank you for the reply, this does affirm my suspicions that due to how the .sqlproj file is used in the project its almost inevitable merge conflicts will exist which will result in having to manually resolve merge conflicts.
MCITP SQL 2005, MCSA SQL 2012
-
Yes and no - majority of cases the merge by the second developer will be without conflicts - only in a few cases will the developer be required to manually select which changes will be picked up by the merge.
we use this on one of my current projects - 95% of the times the merge has no conflict - steps still need to be followed as I stated, but its straightforward.
-
RTaylor2208, I thought you explained yourself very well. We are running into this also and trying to figure out how to address.
It seems the issue is a fundamental roadblock to real CI/CD. Microsoft needs to address. It is ludicrous to expect two developers to not be able to work on stored procedures separately. Or even add a table to support work they are addressing. So, what I gather the solution is from the discussion is to decide on ALL YOUR TABLE AND ALL YOUR STORED PROCEDURES up front and work on them completely in sequence or else you will have a merge conflict. REALLY?!?
-
I have managed to figure out a solution to the issue, but the process is very lengthy to explain. I cannot post fully the entire process documentation here as it would violate our company policies, but I can explain the most important parts which may help you get to the desired solution.
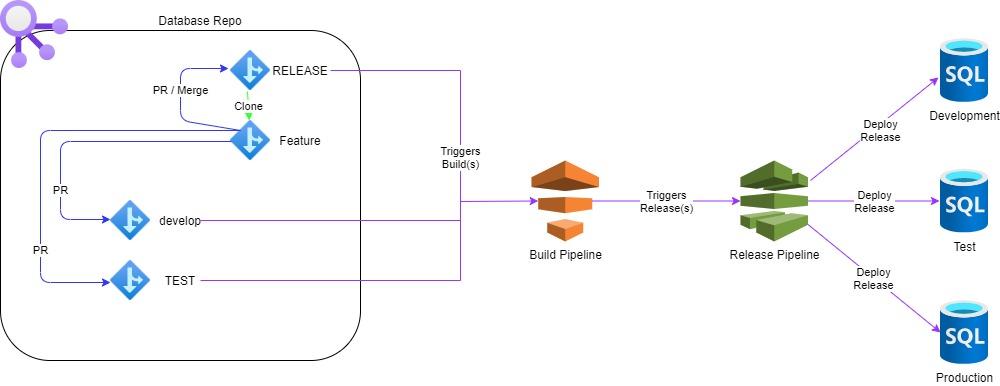
First up how the solution is architected:

- The engineer clones the database repository
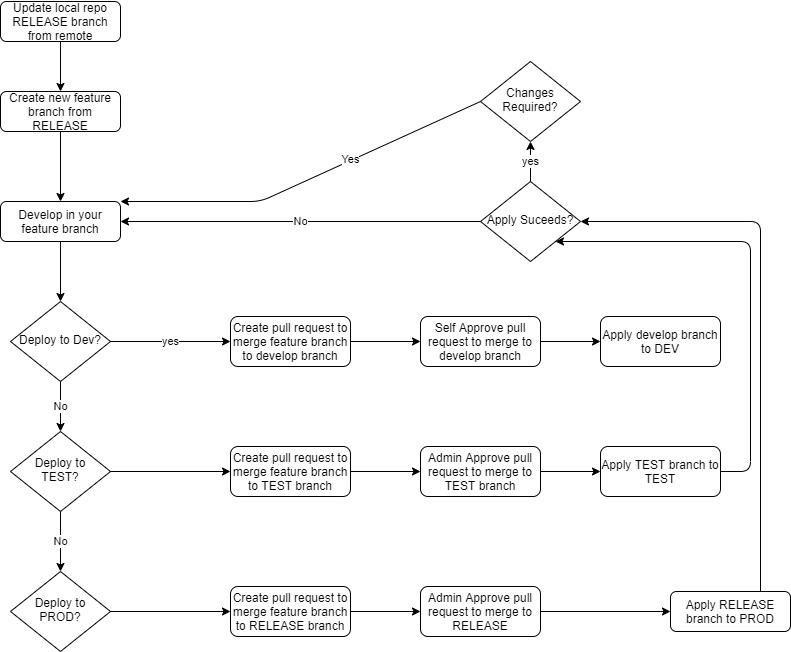
- The engineer ensures the RELEASE (default) branch is fetched to their local host. The release branch is considered to be the production code base and the starting point for all new development.
- The engineer creates a new feature branch for their changes and continues all development commits to this branch.
- Once the feature is ready for deployment to the development environment the engineer must create a pull request to merge the contents of their feature branch to the "develop" branch which is the common branch for development deployment.
- Once the feature has been merged to the develop branch the engineer will execute the build of the database project using a common build pipeline producing an artifact based on the contents of the develop branch.
- Providing the build has been successful the release pipeline will automatically deploy the database artifact to the development environment
- Should the engineer need to make further changes to their feature they must repeat the process of making changes in the feature branch and merging to the develop branch which in turn will rebuild and redeploy to the development environment.
- Once the development stage is complete and the engineer is ready to deploy to the test environment the process is the same as deploying to the development environment. However this time the engineer must create a pull request to merge their feature branch to the TEST branch, again they will execute a build based on the TEST branch and deployment to the test environment, NOTE the release pipeline will require approval to deploy the change to the target database.
- Once all validation of the feature is complete in the test environment the engineer can repeat the process of merging their feature branch for the final time to the "RELEASE" branch. Again running the build pipeline based on the "RELEASE" branch which once complete will trigger the release pipeline. NOTE the release pipeline will require approval to deploy the change to the target database.
- During the merge of the feature branch to the release branch the option to delete the branch should be chosen as no further development should occur on the feature branch once release to production.
From a workflow perspective this is the actions taken:
.sqlproj File Maintenance
Every SQL Database Project created using Visual Studio requires a .sqlproj file, the purpose of this file is to store the properties of the project and track all folders and files which are included in the building of the project.
This single file would potentially be updated by all engineers when making changes in their isolated feature branches. This can and will result in merge conflicts when new features are merged to the develop, TEST and RELEASE branches. For this reason the .sqlproj file is not included in the source control of the project instead this file is created each time the project needs to be used, whether that be on the engineers host or within the build pipeline itself.
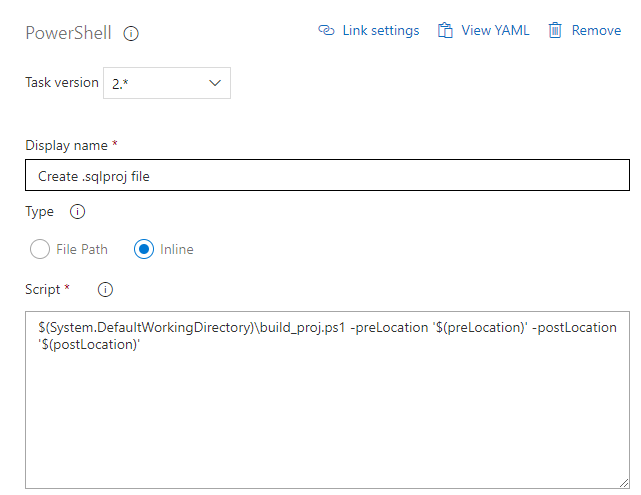
This is achieved by taking a template project file and adding the required XML elements and attributes to the template and subsequently saving a new .sqlproj file.
The files build_proj.ps1 and project_template.xml stored within the repo (see attached files) are used every time you open the database project and when the database build is executed to recreate the .sqlproj file based on the contents of the folders within the project.
Working with the solution in visual studio
Prior to opening the solution from any branch you execute the .ps1 file attached which builds the .sqlproj file then you develop as you would. When submitting your code that .sqlproj file should be in the git.ignore file so it is not sent to source control.
The Ci\Cd pipelines
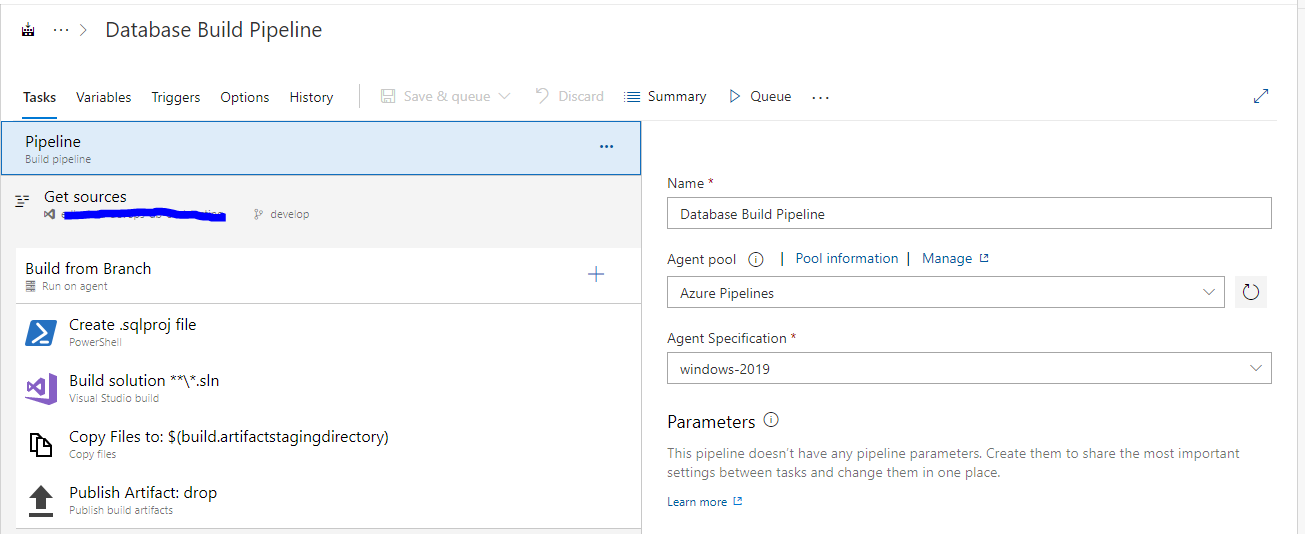
We use Azure Devops for the pipelines, we have a separate build and release pipeline for all of the deployment steps.
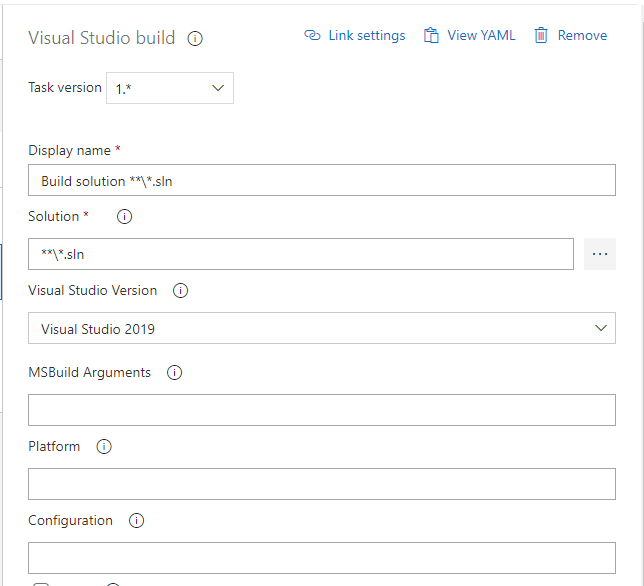
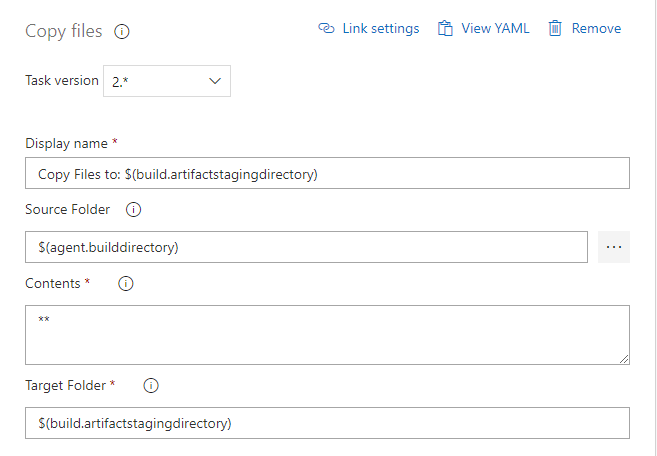
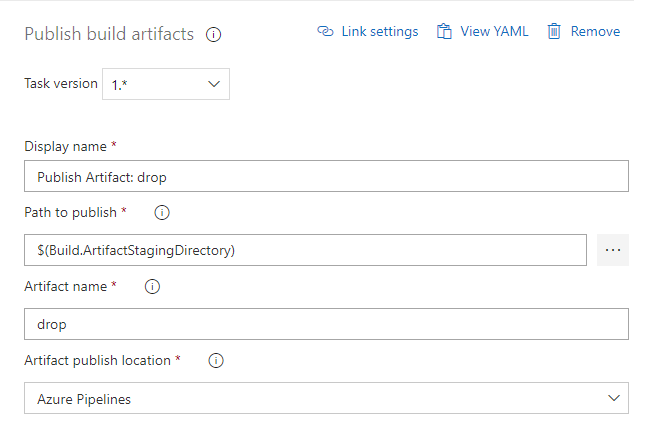
The build pipeline is defined as below:
The pipeline takes 2 variables for controlling the inclusion of pre and post deployment script, more details to follow on how we handle those:
The task definitions within the pipeline are:
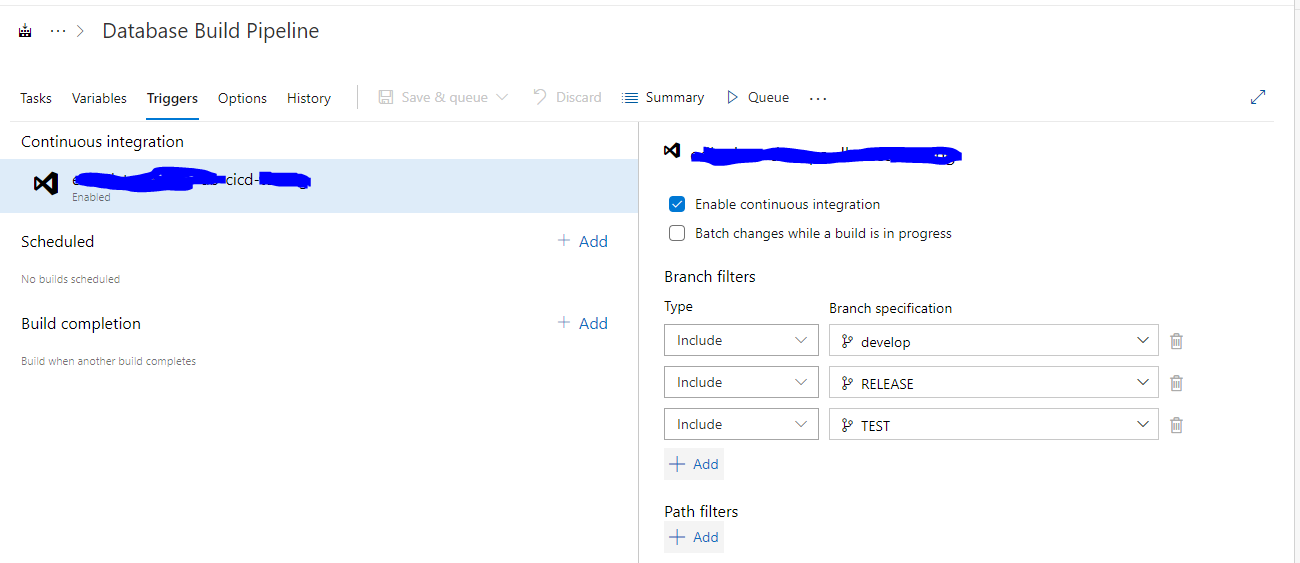
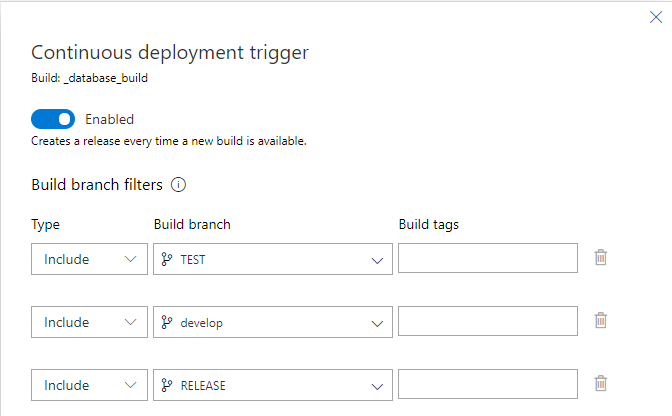
The triggers on the build pipeline are defined as:
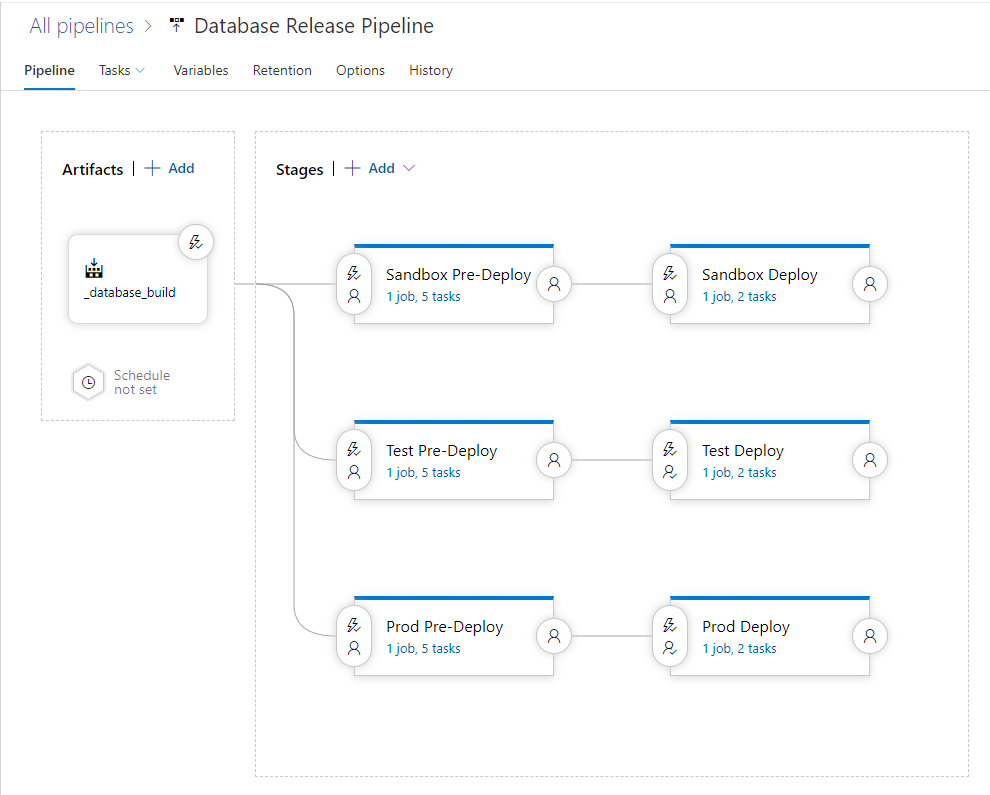
The Release Pipeline is defined as below:
The pipeline utilizes a single artifact which when created is scoped to a particular source branch of the repository the artifact was created from:
The trigger controls what builds are included based on the branches
The pipeline contains 6 stages:
- The Sandbox* stages will only be executed when the artifact has been created from the develop branch
- The Test* stages will only be executed when the artifact has been created from the TEST branch
- The Prod* stages will only be executed when the artifact has been created from the RELEASE branch
This behavior is controlled by defining the "pre deployment conditions" on each of the stages, for example of the "Sandbox Pre-Deploy" stage is is defined as:
The stages which deploy the changes to TEST and PROD have an additional Pre-Deployment condition which is the requirement of approval before the stage will execute:
Database project standards
Folder Structures
Within the database project the following folder structure should be adhered too:
+---mySchema
¦ +---Functions
¦ ¦ myFunction.sql
¦ ¦
¦ +---Stored Procedures
¦ ¦ myProcedure.sql
¦ ¦
¦ +---Tables
¦ ¦ myTables.sql
¦ ¦
¦ +---Triggers
¦ ¦ myTrigger.sql
¦ ¦
¦ +---Views
¦ myView.sql
¦
+---postDeploymentScripts
¦ +---12345_myFeature
¦ ¦ 001_myfeaturePostDeploy.sql
¦ ¦ 002_myfeaturePostDeploy.sql
¦ ¦ 003_myfeaturePostDeploy.sql
¦ ¦ 004_myfeaturePostDeploy.sql
¦ ¦ PostDeployment.sql
¦ ¦
¦ +---45678_my2ndFeature
¦ 001.sql
¦ 002.sql
¦ PostDeployment.sql
¦
+---preDeploymentScripts
¦ +---12345_myFeature
¦ ¦ 001_myfeaturePreDeploy.sql
¦ ¦ PreDeployment.sql
¦ ¦
¦ +---9999_my3rdFeature
¦ 001.sql
¦ PreDeployment.sql
¦
+---Security
+---roles
¦ myRole.sql
¦
+---schemas
¦ mySchema.sql
¦
+---users
myUser.sqlAll objects that belong to a particular database schema should reside in a folder at the root level for that schema, sub directories are used to categories each of the object types.
Database objects which are defined at the database level rather than a specific schema level will be created under the "Security" folder at the root level, again sub folders are used to categorize the object types such as roles, users and schemas.
Pre and Post deployment scripts are stored within the related folder at the root level, Sub folders again should be used to group the the files based on the feature the pre and post deployment scripts relate to.
Pre-Deployment Scripts
Pre-deployment scripts are SQL scripts that should be executed against the database before applying any changes to the structure of the database via the database project. Examples of this could be making a copy of a table and dropping the original table so that the database project will recreate the table with a new schema.
SQL database projects have a limitation that you can only define 1 single pre deployment script. This CI\CD solution has overcame that limitation by allowing you at the time of building the project to define a specific folder for pre-deployment scripts and utilizing a controlling script to call other scripts.
Take for example you are creating a new feature that will potentially make a breaking change to a table such as changing the nullability of a column, as part of pre-deployment we will copy the contents of the table to a new table and drop the existing table.
First we create a sql script to backup the table and save this to a new folder under the ./PreDeploymentScripts location:
file = ./PreDeploymentScripts/11111_MyBigChange/001_backup_table.sql
contents:
IF NOT EXISTS (SELECT * FROM sys.tables WHERE name = 'bck_DemoTable' AND schema_id = schema_id('dm_test'))
SELECT * INTO [dm_test].[bck_DemoTable]FROM [dm_test].[DemoTable]
GONext we will create a second file to drop the table:
file = ./PreDeploymentScripts/11111_MyBigChange/002_drop_table.sql
contents:
IF EXISTS (SELECT * FROM sys.tables WHERE name = 'DemoTable' AND schema_id = schema_id('dm_test'))
DROP TABLE [dm_test].[DemoTable]GOWe now have 2 scripts that must be executed in order and we know that database projects can only have a a single Pre-Deployment script, to overcome this issue we create a sql script that utilizes SQLCMD syntax to execute other scripts:
file = ./PreDeploymentScripts/11111_MyBigChange/PreDeployment.sql (not the name of the file must be exactly "PreDeployment.sql"
contents:
:r .\001_backup_table.sql
:r .\002_drop_table.sqlNote in the above the location of the files that will be executed is the path relative to that of the PreDeployment.sql file, the ":r" characters are the SQLCMD command to read a file and execute it's contents.
The folder structure now looks like below:
+---preDeploymentScripts
¦ +---11111_MyBigChange
¦ 001_backup_table.sql
¦ 002_drop_table.sql
¦ PreDeployment.sqlWhen we build the project either locally on your host or within the CI pipeline we will reference the folder in which you have created the files so they and only they are executed during the pre-deployment phase.
Post-Deployment Scripts
Post-deployment scripts are SQL scripts that should be executed against the database after applying any changes to the structure of the database via the database project. Examples of this could be repopulating a table that you backed up using pre-deployment, change the structure of the table within the project then re-populated in post deployment once the table structure was changed.
SQL database projects have a limitation that you can only define 1 single post-deployment script. This CI\CD solution has overcame that limitation by allowing you at the time of building the project to define a specific folder for post-deployment scripts and utilizing a controlling script to call other scripts.
Take for example you are creating a new feature that needs to load a new table with data after the table has been created with the results of a query.
First we create a sql script to load the table and save this to a new folder under the ./PostDeploymentScripts location:
file = ./PostDeploymentScripts/22222_MyOtherChange/001_load_table.sql
contents:
IF (SELECT COUNT(1) FROM [dm_test].[testtable1]) = 0
INSERT INTO [dm_test].[testtable1] (id, ColA, ColB, ColC, ColX, ColY, ColZ)SELECT id, ColA, ColB, 'Static', 'Test', 'Data', '!'
FROM [dm_test].[DemoTable]
GOWe now have 1 script that must be executed, as having a single post deployment script is supported we could have just called this file "PostDeployment.sql" and it would execute successfully, but to maintain consistency in how we are applying pre and post deployment scripts we create a sql script that utilizes SQLCMD syntax to execute other scripts:
file = ./PreDeploymentScripts/22222_MyOtherChange/PostDeployment.sql (note the name of the file must be exactly "PostDeployment.sql"
contents:
:r .\001_load_table.sql
Note in the above the location of the files that will be executed is the path relative to that of the PostDeployment.sql file, the ":r" characters are the SQLCMD command to read a file and execute it's contents.
The folder structure now looks like below:
+---postDeploymentScripts
¦ +---22222_MyOtherChange
¦ 001_load_table.sql
¦ PostDeployment.sqlWhen we build the project either locally on your host or within the CI pipeline we will reference the folder in which you have created the files so they and only they are executed during the post-deployment phase.
MCITP SQL 2005, MCSA SQL 2012
-
Pasting the powershell code here rather than attaching as the forum does not allow .ps1 files:
Param (
[string]$preLocation,
[string]$postLocation
)
$cur_dir = Get-Location | Select Path
$cur_dir = ([string]$cur_dir.Path) + '\'
$xmlfile = 'project_template.xml'
$targetxml = 'AzureDB.sqlproj'
#$preLocation = '.\preDeploymentScripts\9939\'
#$postLocation = '.\postDeploymentScripts\9939\'
############################################################
#Add folder to project
############################################################
Write-host 'Checking for folders within database repository'
$folders = Get-ChildItem -Recurse | Where-Object { $_.PSIsContainer } | Select-Object FullName
If ($folders) {
Write-host "Loading template xml for sqlproj file $xmlfile"
[xml]$xml = Get-Content $xmlfile
Write-host 'Adding folders within database repository to project definition'
$folderElement = $xml.CreateElement("ItemGroup", $xml.DocumentElement.NamespaceURI);
$element = $xml.Project.AppendChild($folderElement);
ForEach ($folder in $folders) {
$folder = $folder.FullName.Replace($cur_dir,"")
$newFolderElement = $xml.CreateElement("Folder",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$folder)
}
Write-Host "Writing target sqlproj file $targetxml"
$xml.Save($targetxml)
}
############################################################
#Add regular object files to project excluding file in \bin
#\preDeploymentScripts and \postDeploymentScripts
############################################################
Write-host 'Checking for sql files within database repository'
$files = Get-ChildItem -Recurse -Include '*.sql' | Where-Object { ! $_.PSIsContainer -and $_.FullName -notlike "*\bin*" -and $_.FullName -notlike "*\preDeploymentScripts\*"-and $_.FullName -notlike "*\postDeploymentScripts\*"} | SELECT-Object FullName
If ($files) {
Write-host "Loading template xml for sqlproj file $targetxml"
[xml]$xml = Get-Content $targetxml
Write-host 'Adding files within database repository to project definition'
$folderElement = $xml.CreateElement("ItemGroup", $xml.DocumentElement.NamespaceURI);
$element = $xml.Project.AppendChild($folderElement);
ForEach ($file in $files) {
$file = $file.FullName.Replace($cur_dir,"")
if ($file -notcontains 'bin') {
$newFolderElement = $xml.CreateElement("Build",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$file)
}
}
Write-Host "Writing target sqlproj file $targetxml"
$xml.Save($targetxml)
}
############################################################
#Add pre deployment scripts to the project from
#\preDeploymentScripts
############################################################
if ($preLocation) {
Write-host 'Checking for pre deployment scripts within database repository'
$files = Get-ChildItem -LiteralPath $preLocation -Recurse -Include '*.sql' | Where-Object { ! $_.PSIsContainer } | SELECT-Object FullName
If ($files) {
Write-host "Loading template xml for sqlproj file $targetxml"
[xml]$xml = Get-Content $targetxml
Write-host 'Adding pre-deployment scripts within database repository to project definition'
$folderElement = $xml.CreateElement("ItemGroup", $xml.DocumentElement.NamespaceURI);
$element = $xml.Project.AppendChild($folderElement);
ForEach ($file in $files) {
$file = $file.FullName.Replace($cur_dir,"")
write-host 'adding pre-deployment ' $file
if ($file -like '*\PreDeployment.sql') {
$newFolderElement = $xml.CreateElement("PreDeploy",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$file)
}
else {
$newFolderElement = $xml.CreateElement("None",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$file)
}
}
Write-Host "Writing target sqlproj file $targetxml"
$xml.Save($targetxml)
}
}
############################################################
#Add post deployment scripts to the project from
#\postDeploymentScripts
############################################################
if ($postLocation) {
Write-host 'Checking for post deployment scripts within database repository'
$files = Get-ChildItem -LiteralPath $postLocation -Recurse -Include '*.sql' | Where-Object { ! $_.PSIsContainer } | SELECT-Object FullName
If ($files) {
Write-host "Loading template xml for sqlproj file $targetxml"
[xml]$xml = Get-Content $targetxml
Write-host 'Adding post-deployment scripts within database repository to project definition'
$folderElement = $xml.CreateElement("ItemGroup", $xml.DocumentElement.NamespaceURI);
$element = $xml.Project.AppendChild($folderElement);
#Add the post deployment scripts not included in the build
ForEach ($file in $files) {
$file = $file.FullName.Replace($cur_dir,"")
write-host 'adding post-deployment ' $file
if ($file -like '*\PostDeployment.sql') {
$newFolderElement = $xml.CreateElement("PostDeploy",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$file)
}
else {
$newFolderElement = $xml.CreateElement("None",$xml.DocumentElement.NamespaceURI)
$newFolderElementAdd = $element.AppendChild($newFolderElement)
$newFolderElementAdd.SetAttribute("Include",$file)
}
}
Write-Host "Writing target sqlproj file $targetxml"
$xml.Save($targetxml)
}
}
Write-Host "Database Project sqlproj file generated $targetxml"MCITP SQL 2005, MCSA SQL 2012




Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply