How to force MS SQL to select a partition instead of making a full table scan
-
Hi all,
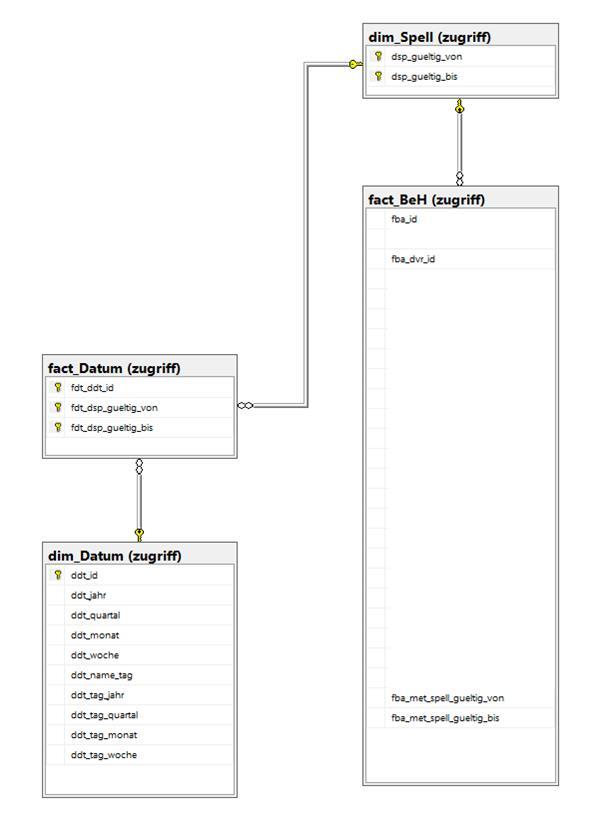
I am currently designing a datamart layer in MS SQL 2016 Enterprise. My data and thus, the main fact table is not point-in-time but time-interval-based, because I am dealing with the whole history of the customer. Of course, there will be point-in-time analysis. Thus, I have modelled that in the following way:
- fact_BeH: my customer time-interval based fact table (valid from column name: fdt_dsp_gueltig_von / valid to column name: fdt_dsp_gueltig_bis)
- dim_Datum: table storing all calendar dates
- dim_Spell: storing all the time intervals used in the fact table fact_BeH
- fact_Datum: m:n factless fact table tranlating which date refers to which time interval and wich dates are within one time interval

As both fact tables as well as dim_Spell can get quite big (1bn records in fact_Datum), I am using a yearly based partitioning as typical use cases only focuses on 1-2 year periods or point in time request. I want to avoid full table/index scans to just select a slice. Further, all tables are stored in clustered column store index.
Next, I have tested a typical query called example 1 (generated by MicroStrategy if you are curious about the strange aliases :-)) to get all customer history within a given year. For the sake of clarity, I just want to count all distinct customers (fba_dvr_id = customer id) having any kind of event in that year 2010:
SELECT a13.ddt_jahr ddt_jahr,
Count(DISTINCT a11.fba_dvr_id) fba_met_cnt_distinct_vrs
FROM zugriff.fact_beh a11
JOIN zugriff.fact_datum a12
ON ( a11.fba_met_spell_gueltig_bis = a12.fdt_dsp_gueltig_bis
AND a11.fba_met_spell_gueltig_von = a12.fdt_dsp_gueltig_von )
JOIN zugriff.dim_datum a13
ON ( a12.fdt_ddt_id = a13.ddt_id )
WHERE a13.ddt_jahr IN ( 2010 )
GROUP BY a13.ddt_jahrI have checked the actual execution plan and when checking the clustered index scans I have noticed that - I assume due to the long run time - the whole index is scanned:
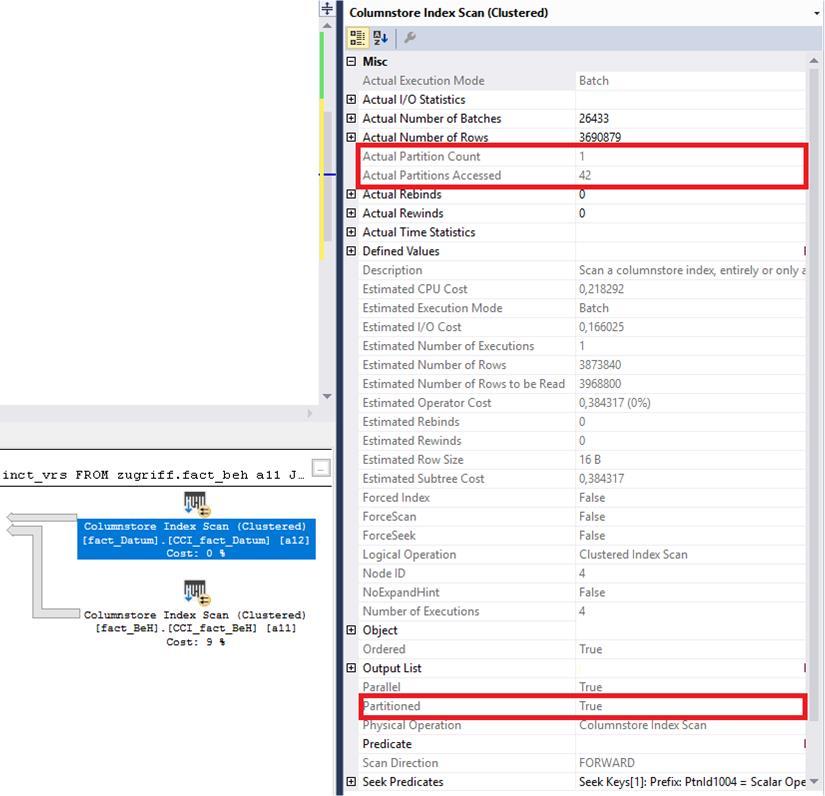
Actual partition count = 0 (I have 50 partitions in place) and no information that only a single partition is used but the query optimizer recognizes that the table is partitioned.
Next, I just wrote the time span in particular dates instead of the year (saving one join) to verify that behavior:
SELECT a12.fdt_ddt_id ddt_id,
Count(DISTINCT a11.fba_dvr_id) fba_met_cnt_distinct_vrs
FROM zugriff.fact_beh a11
JOIN zugriff.fact_datum a12
ON ( a11.fba_met_spell_gueltig_bis = a12.fdt_dsp_gueltig_bis
AND a11.fba_met_spell_gueltig_von = a12.fdt_dsp_gueltig_von )
WHERE a12.fdt_ddt_id BETWEEN '2010-01-01' AND '2010-12-31'
GROUP BY a12.fdt_ddt_idLooking at the execution plan, partition 42 (year 2010) is accessed:
This is good but all other related partitioned tables (fact_BeH) are accessed with full index scan. I would have assumed that the query optimizer is smart enough to know only a subset of data is required and that based on that data the relevant partition (42) would be selected. But for some reason, the query optimizer does only handle the table which is exactly filtered.
My question is: How do I force MS SQL with a query hint to use only the single/relevant partition?
If needed, below are my DDLs for the above tables (exluding foreign keys) and the partition functions/schemes. I can provide .sqlplan files on PM if you like.
Thanks a lot,
Sven
CREATE TABLE [zugriff].[fact_BeH]
(
fba_id BIGINT NOT NULL IDENTITY(1,1),
[fba_dvr_id] INT NOT NULL,
[fba_met_spell_gueltig_von] DATE NOT NULL,
[fba_met_spell_gueltig_bis] DATE NOT NULL,
INDEX [CCI_fact_BeH] CLUSTERED COLUMNSTORE ON FactPartitioningByDateTables ([fba_met_spell_gueltig_von])
)
ON FactPartitioningByDateTables ([fba_met_spell_gueltig_von])
GO
CREATE TABLE [zugriff].[fact_Datum]
(
[fdt_ddt_id] DATE NOT NULL,
[fdt_dsp_gueltig_von] DATE NOT NULL,
[fdt_dsp_gueltig_bis] DATE NOT NULL,
CONSTRAINT [PK_fact_Datum] PRIMARY KEY NONCLUSTERED ([fdt_dsp_gueltig_von], [fdt_dsp_gueltig_bis], [fdt_ddt_id]) WITH (DATA_COMPRESSION = PAGE) ON FactPartitioningByDateIndices ([fdt_ddt_id]),
INDEX [CCI_fact_Datum] CLUSTERED COLUMNSTORE ON FactPartitioningByDateTables ([fdt_ddt_id])
)
ON FactPartitioningByDateTables ([fdt_ddt_id])
GO
CREATE TABLE [zugriff].[dim_Spell]
(
[dsp_gueltig_von] DATE NOT NULL,
[dsp_gueltig_bis] DATE NOT NULL,
CONSTRAINT [PK_dim_Spell] PRIMARY KEY NONCLUSTERED ([dsp_gueltig_von], [dsp_gueltig_bis]) WITH (DATA_COMPRESSION = PAGE) ON DimPartitioningByDateIndices ([dsp_gueltig_von]),
INDEX [CCI_dim_Spell] CLUSTERED COLUMNSTORE ON DimPartitioningByDateTables ([dsp_gueltig_von])
)
CREATE TABLE [zugriff].[dim_Datum]
(
[ddt_id] DATE NOT NULL,
[ddt_jahr] SMALLINT NOT NULL,
[ddt_quartal] NVARCHAR(50) NOT NULL,
[ddt_monat] NVARCHAR(50) NOT NULL,
[ddt_woche] NVARCHAR(50) NOT NULL,
[ddt_name_tag] NVARCHAR(50) NOT NULL,
[ddt_tag_jahr] SMALLINT NOT NULL,
[ddt_tag_quartal] TINYINT NOT NULL,
[ddt_tag_monat] TINYINT NOT NULL,
[ddt_tag_woche] TINYINT NOT NULL,
CONSTRAINT [PK_dim_Datum] PRIMARY KEY NONCLUSTERED ([ddt_id]) WITH (DATA_COMPRESSION = PAGE) ON DimPartitioningByDateIndices ([ddt_id]) ,
INDEX [CCI_dim_Datum] CLUSTERED COLUMNSTORE ON DimPartitioningByDateTables ([ddt_id])
)
CREATE PARTITION FUNCTION [PartitioningByDate]
(
DATE
)
AS RANGE RIGHT
FOR VALUES
(
'1970-01-01',
'1971-01-01',
'1972-01-01',
...
)
CREATE PARTITION SCHEME FactPartitioningByDateTables
AS PARTITION PartitioningByDate
ALL TO ([FACTS_TABLES_DEFAULT]) -
curious of what statistics io would say on both cases - specifically segments read / skipped which will be an output when table/index is a columnstore.
on this case I don't think a hint will be possible/feasible. but wonder if having a foreign key between dim_datum and fact_datum will help
-
Foreign keys do exist (see screenshot of ERD, I just removed them from the script).
As I am a novice to query plans: does the sqplan file help you to answer your I/O question? I don't understand your sentence at all, sorry :-(.
-
This will explain what it is.
I don't think full plan has columnstore segments data on it - but to confirm we would need the full explain plan file (to upload here you need to change extension to be a .txt)
and sql ready for you - would need the printed messages
print 'step1' + convert(varchar(26), getdate(), 121)
set statistics io on
SELECT a13.ddt_jahr ddt_jahr,
Count(DISTINCT a11.fba_dvr_id) fba_met_cnt_distinct_vrs
FROM zugriff.fact_beh a11
JOIN zugriff.fact_datum a12
ON ( a11.fba_met_spell_gueltig_bis = a12.fdt_dsp_gueltig_bis
AND a11.fba_met_spell_gueltig_von = a12.fdt_dsp_gueltig_von )
JOIN zugriff.dim_datum a13
ON ( a12.fdt_ddt_id = a13.ddt_id )
WHERE a13.ddt_jahr IN ( 2010 )
GROUP BY a13.ddt_jahr
print 'step2' + convert(varchar(26), getdate(), 121)
SELECT a12.fdt_ddt_id ddt_id,
Count(DISTINCT a11.fba_dvr_id) fba_met_cnt_distinct_vrs
FROM zugriff.fact_beh a11
JOIN zugriff.fact_datum a12
ON ( a11.fba_met_spell_gueltig_bis = a12.fdt_dsp_gueltig_bis
AND a11.fba_met_spell_gueltig_von = a12.fdt_dsp_gueltig_von )
WHERE a12.fdt_ddt_id BETWEEN '2010-01-01' AND '2010-12-31'
GROUP BY a12.fdt_ddt_id
print 'step3' + convert(varchar(26), getdate(), 121) -
First, I should note that I have SQL standard, not enterprise and have not done partitioning so my input here may be way out to left field.
I was just reading the queries and looking at the DDL, and to me I don't see how the first one can use the partition.
In query number 1, your WHERE is using the column dim_datum.ddt_jahr. This is not in any partition.
Looking at the diagram, my best guess is that your FK is from fact_datum to dim_spell is on the column fdt_dsp_guetig_von which points to dsp_guetig_von.
none of those columns are in the partition.
On fact_datum, the column fdt_ddt_id is partitioned, but SQL has no way to know if fdt_dsp_guetig_von matches fdt_ddt_id. Since it has no way to know if they match, it has no way to know if it can use the partition or not and in order to provide accurate data, it cannot use the partitioning.
With the second query, you are filtering on fact_datum.fdt_ddt_id which IS part of the parition, so SQL can pick just the associated partitions.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi,
your comment is exactly my issue I have.
To confirm your assumptions:
- fact_BeH is partitioned by guelt_von (begin of time interval)
- fact_Datum is partitioned by ddt_id (calendar date)
First, let us stick to the second query
SELECT a12.fdt_ddt_id ddt_id,
Count(DISTINCT a11.fba_dvr_id) fba_met_cnt_distinct_vrs
FROM zugriff.fact_beh a11
JOIN zugriff.fact_datum a12
ON ( a11.fba_met_spell_gueltig_bis = a12.fdt_dsp_gueltig_bis
AND a11.fba_met_spell_gueltig_von = a12.fdt_dsp_gueltig_von )
WHERE a12.fdt_ddt_id BETWEEN '2010-01-01' AND '2010-12-31'
GROUP BY a12.fdt_ddt_idfact_Datum is partitioned by calendar date and when using that granularity, the partitioned is accessed (as seen). fact_BeH is partitioned by fba_met_spell_gueltig_von and coming from fact_Datum there is only a subset of data going into fact_BeH, so I would assume that SQL knows that when it is looking for the data to join it must look only in partition 42 and not all.
-
Maybe I am misunderstanding the problem here, but to me how you describe it is how I expect it to work.
With the second query and second screenshot, you are showing that the lookup on fact_datum is only looking at a single partition. Your partitions are done by years, and your WHERE clause is ON the partition column, so SQL would only need to look at 1 partition, in this case partition 42, to get all of the data required for the fact_datum table. This part makes sense.
The JOIN then needs to find all rows from fact_beh that match fact_datum based on the join conditions. Due to the WHERE clause, you only need to look at 1 partition of fact_datum, but you are not filtering anything on fact_beh. With fact_beh, based on how it looks like to me, you have the index on the fba_met_spell_gueltig_von column but there is no direct relation back to fact_datum. So to SQL, these are unrelated tables that you are joining on. As far as it can tell, the value of fdt_dsp_gueltig_von could be any valid value. It doesn't know until it looks at the data what the value is. So you are telling it that fba_met_spell_gueltig_von must match with fd_dsp_gueltig_von, but it does not have enough information about both of the columns to do a scan on a single partition.
At least this is how I expect it is working. Again, having SQL Standard, I can't test this with respect to partitions. But my understanding of how SQL works, if table A has FK's to table B and table C is has FK's to table B, but table A and table C have no FK's to each other except through table B and I try to join them without also joining them to table B, SQL will need to do a scan on the entire table or index to find all matching values for the join.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi,
sorry, my remote access to the server doesn't work since half a day. I couldn't run the I/O tests.
But Brian pointed it out: MSSQL joins with the whole table what can be seen in the query plan. What I need is a way to write the query that the other fact table doesn't need a full table scan.
As I cannot test it right know: would cross apply operator do the trick as it process data differently. I am missing the feature Oracle gives
select * from t partition (p2)
as I do know which partition has to be scanned.
-
You can access data in a given partition using the $partition system function.
here is a clean example...
https://database.guide/return-all-rows-from-a-specific-partition-in-sql-server-t-sql/

Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply