Hash Match performance issue
-
Hi
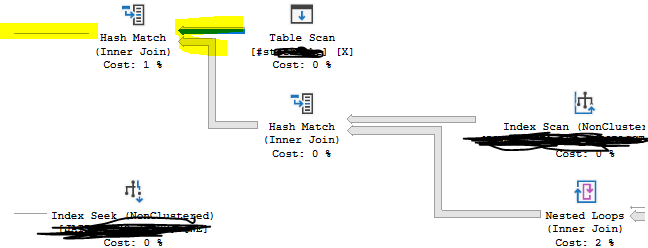
I have a stored proc that is performing badly. When I look at the execution plan I can see a couple of instances where there are a large number of rows inputted into a hash match but the output is estimated to be only 1 row.
The inputs into the hash match below are 500,000 and 1,000,000 rows, but the estimated output is only a single row. Apart from out of date statistics, can anyone think of a reason why the output is estimate so low?

-
Actual execution plan (obfuscated as needed) could help. Part of an image is of limited value.
What are the actual outputs?
Are there scalar or multi-statement table-valued functions involved?
The costs pictured are low. Is this a big complex plan with lots of 1-2% costs, or are there some major costs elsewhere?
-
Thanks for the reply.
This is from the estimated plan. The full plan is large, and the SP is taking hours to run, so that's why I can't post from the actual.
Looking at the plan this just struck me as weird and given that there are Nested loops after the Hash match, an incorrect estimate of 1 could cause real performance issues when we get to that operator.
So that's why I asked for ideas as to why the hash match would estimate so low, this feels like a cardinality issue to me.
-
It's possible that creating your own statistics would help SQL here, but without more details, it's impossible to say what stats to create.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
I'm just wondering if there's something, outside of stats, that would cause the cardinality estimator, to estimate a single row output. Like table variables always have an estimate of a single row.
-
You might need some new statistics. Put the query into "Database Engine Tuning Advisor" in SSMS and see if it suggest some new statistics.
-
Look at the join criteria within the details of the operator and see what the likely output from that is, based on the statistics provided. Additionally, see if there are further filter criteria defined within the hash match operator. Also, what are the next operators in the plan. If they have row limits, you may be seeing the results of that. Remember, plans logically run, from left to right. Data flow is right to left, but the logical instantiation, and the way they get called, is from the left. In rowmode processing, "give me a row, give me a row" is how to think of it. In batch mode, "give me a thousand rows, give me a thousand rows."
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Kindly share the full execution plan. the part is less to suggest.
Regards
Durai Nagarajan -
Hi Durai, I don't want to share the plan. I was specifically looking for, what seemed to me, to be a weird calculation of the Hash Match.
Thank you for taking the time to read my question though.
I'm going to add an Update Statistics for the temp table in the hash join and see if that gets more reasonable estimation
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply