Fuzzy Search
- J Livingston SQL - Thursday, August 3, 2017 11:01 AM
The site has changed since I downloaded census data several years ago but it looks familiar enough I think you can find the same data.
https://www.census.gov/2010census/data/I have several pages of scripts I wrote to randomly generate a million names in the frequency they normally occur. Census data is defined by frequency per 100,000. The 87,000 last names in the census would have different span sizes but end-to-end would go from 1 to 1 million when I create the ranges. Using the RAND function, I pick a number between 1 and 1 million to get a last name. The RAND is pretty good at having an even distribution. The drawback from my routines is you may get Chinese first names and Spanish last names when building a full name.
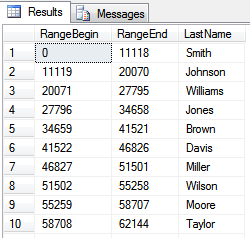
Here are the top 10 last names in the census with the range numbers I generated. A rand value of 30000 would return the name Jones. You can see that the first 10 names take up 62144 positions in the 1 million values. The least common last names may only take one or two positions each. Looking at the chart, I would expect to see 11,118 Smiths generated give or take 10%.

-
I've had some success using the combination of Levenshtein and Difference functions. I had a problem where I needed to match names like 'Term Loan' to 'Term Loan A', 'Term Loan B' etc:
SELECT
x.ID
,RowNumber = ROW_NUMBER() OVER(PARTITION BY x.ID ORDER BY x.Lev ASC, x.Dif DESC)
,x.Lev
,x.Dif
INTO #FuzzyMatch
FROM (
SELECT
obj1.ID
,Lev = dbo.Levenshtein(obj1.Name,obj2.Name)
,Dif = DIFFERENCE(obj1.Name,obj2.Name)
,SnapshotID = snap.ID
FROM dbo.Object1 obj1
JOIN dbo.Object2 obj2 ....
) x
Later on, I would select from that table ordering by rank (from row_number). It was a reasonably quick way to accomplish the matches I was looking for. - danechambrs - Thursday, August 3, 2017 1:42 PM
Levenshtein isn't an internal function, it's a user-defined function. I'd be very interested to see the code for it.
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
I was hoping to find something that would return matches on similar names but this one did not accommodate that. I would like to search text like 'david' and return 'dave' or even search for 'james' and return 'james' or 'jim'.
- dlchase - Friday, August 4, 2017 7:01 AM
I have production implementations of nickname variation searches (Margaret, Agatha, Maggie). They're functional and rational and procedural but can't handle misspelled names and variation explosions like this function. I'd say build yourself a nickname or abbreviation or synonym table where your search needs it but then call the fuzzy search to do the actual matching so you can find misspellings and variations. If someone wants a nickname table article, I can write that, but I'm telling you, this fuzzy function is a magnitude more powerful. As Microsoft employees say "don't flip the bozo bit". That phrase means don't consider something as stupid unless you first understand it.
This general fuzzy search function can be used for any strings such as movie names, song names, addresses, and descriptions. If you know what you want to find, then type it into the search function. I have examples in a previous post of how to find variations. Search on all names and nicknames and variations to find all targets for a person. For example, search on "Jim Jimmy James TheDude Smith Smitty Smythe" or whatever else the person goes by. Do it all in one function call so you get the benefit of exponential explosion of variation matches. That is where the power is.
-
Thanks. BTW I love the function for many of my searches! I will try some way of incorporating nicknames. Do you know of any sources where this might be available so I don't have to manually enter them into a table?
- dlchase - Friday, August 4, 2017 7:39 AM
These are screen-scraped nicknames from dozens of web pages. The attached 49k text file has about 1000 names and their 3389 variations.
-
Thanks.
-
William, thank you for your very nice work with the fuzzy search function. I'm a 74-year-old retired DBA who now 'plays' nearly every day with SQL code working mainly on analyzing and cleaning my digital music collection of 70k tracks and standardizing my 31 years of Quicken financial data which is all imported into SQL Server because it is my tool of choice. Unfortunately my learning curve has flattened lots but I still love to work with data and keep what's left of my brain active. I appreciate finding work such as yours that serves to further my projects and at the same time give me a little exposure to the newer techniques. I peruse nearly all the information that arrives from the SSC website.
Rick
If you do a half-assed job of things, folks will ask 'why did this ass only do half the job?' -
Every now and then you come across a solution that is both simple and elegant. The only flaw is that I didn't come up with it myself! My first association was to anagrams, if the characters appears in pairs it’s often easy to figure out, but if there is no character combination from the original word it’s much harder.
With the help of your function I built a simple tool, FindObject, that we’ll useinternally to look for SQL objects. We'll bring it into our production as soon as possible.
Something along those lines:
DECLARE @s1 varchar(100) = 'Countries';
SELECT DISTINCT top (50)
ObjectName = concat(s.name, '.', o.name), o.type_desc, fms.score
from sys.objects o
inner join sys.schemas s on s.schema_id = o.schema_idCROSS APPLY ( selectdbo.FuzzyMatchString(@s1, concat(s.name, o.name)) AS score) AS fms
where o.parent_object_id = 0
ORDER by fms.score desc
Thanks for sharing this simple and elegant solution!
-
I love this idea. I can immediately see a potential use for this that warrants some further research. I work in the legal sector and can see that this might be very useful in conflict of interest searches.
"Knowledge is of two kinds. We know a subject ourselves, or we know where we can find information upon it. When we enquire into any subject, the first thing we have to do is to know what books have treated of it. This leads us to look at catalogues, and at the backs of books in libraries."
— Samuel Johnson
I wonder, would the great Samuel Johnson have replaced that with "GIYF" now? -
I always enjoy seeing different approaches to handling fuzzy matching in SQL Server. That said, there are many issues with this approach that I don't want to dive into that deeply.
If you were to use this approach (not suggested) the #1 thing to address is ensure that the shorter of the two strings is always evaluated first. Otherwise a consistant or accurate result is not guaranteed. Observe:
DECLARE
@s1 varchar(100) = 'Billy William Lee Talada Jr. alalalalalalalalalal',
@s2 varchar(100) = 'Mr. William Lee Talada Jr.';SELECT dbo.FuzzyMatchString(@s1, @s1);
SELECT dbo.FuzzyMatchString(@s2, @s1);#2: Performance wise - scalar always fails. This can be done easily by using NGrams8k like so:
DECLARE
@s1 varchar(100) = 'Billy William Lee Talada Jr.',
@s2 varchar(100) = 'Mr. William Lee Talada Jr.';SELECT fms = sum(sign(charindex(token, @s2)))
FROM dbo.NGrams8k(@s1, 2)
WHERE charindex(token, @s2) > 1;Performance test:
select TOP (10000) someid = identity(int, 1, 1), x.[name]
into #names
from (VALUES ('Mr. William Lee Talada Jr.'), ('William Lee Talada Jr.'),
('William Lee Talada'), ('Lee Talada'), ('William Lee Talada Jr.')
,(cast(newid() as varchar(100))), (cast(newid() as varchar(100)))
) x([name])
CROSS JOIN sys.all_columns a, sys.all_columns b;
GOPRINT 'scalar udf'+char(10)+replicate('-',50);
GO
DECLARE @st datetime = getdate(), @x int, @s1 varchar(100) = 'Billy William Lee Talada Jr.';
SELECT @x = fms.score
from #Names
CROSS APPLY (select dbo.FuzzyMatchString(@s1, Name) AS score) AS fms;
PRINT datediff(ms, @st, getdate());
GO 5PRINT char(10)+'ngrams serial'+char(10)+replicate('-',50);
GO
DECLARE @st datetime = getdate(), @x int, @s1 varchar(100) = 'Billy William Lee Talada Jr.';
SELECT @x = sum(sign(charindex(token, [name])))
FROM #names
CROSS APPLY dbo.NGrams8k(@s1, 2)
GROUP BY someid
OPTION (MAXDOP 1);
PRINT datediff(ms, @st, getdate());
GO 5PRINT char(10)+'ngrams parallel'+char(10)+replicate('-',50);
GO
DECLARE @st datetime = getdate(), @x int, @s1 varchar(100) = 'Billy William Lee Talada Jr.';
SELECT @x = sum(sign(charindex(token, [name])))
FROM #names
CROSS APPLY dbo.NGrams8k(@s1, 2)
CROSS APPLY dbo.make_parallel()
GROUP BY someid;
PRINT datediff(ms, @st, getdate());
GO 5Results
scalar udf
--------------------------------------------------
Beginning execution loop
243
237
240
236
240
Batch execution completed 5 times.ngrams serial
--------------------------------------------------
Beginning execution loop
237
230
227
240
233
Batch execution completed 5 times.ngrams parallel
--------------------------------------------------
Beginning execution loop
100
103
100
100
100
Batch execution completed 5 times."I cant stress enough the importance of switching from a sequential files mindset to set-based thinking. After you make the switch, you can spend your time tuning and optimizing your queries instead of maintaining lengthy, poor-performing code."-- Itzik Ben-Gan 2001
- ChrisM@Work - Friday, August 4, 2017 1:48 AM
I basically took this https://www.dotnetperls.com/levenshtein and turned it into a CLR:
https://pastebin.com/grC4enaR -
Here is an sql function implementation of the Levenshtein Difference function. I am posting it with the statement that it is not my original code, but I am certain that it came from this forum or a similar one but I have long since lost the original reference. Use it as you wish, I desire neither credit or blame
CREATE FUNCTION [dbo].[edit_distance]
(
@s1 NVARCHAR(3999)
, @s2 NVARCHAR(3999)
)
RETURNS INT
AS
BEGIN
/* example SELECT dbo.edit_distance ( N'kitten', N'kitchen' ) */
DECLARE @s1_len INT
, @s2_len INT
, @i INT
, @j INT
, @s1_char NCHAR
, @c INT
, @c_temp INT
, @cv0 VARBINARY(8000)
, @cv1 VARBINARY(8000);
SELECT @s1_len = LEN(@s1)
, @s2_len = LEN(@s2)
, @cv1 = 0x0000
, @j = 1
, @i = 1
, @c = 0
IF @s1= ' '
BEGIN
SELECT @s1= REPLICATE('Z',25)
SELECT @s1_len = LEN(@s1)
END
IF @s2 = ' '
BEGIN
SELECT @s2= REPLICATE('X',25)
SELECT @s2_len = LEN(@s2)
ENDWHILE @j <= @s2_len
SELECT @cv1 = @cv1 + CAST(@j AS BINARY(2))
, @j = @j + 1;
WHILE @i <= @s1_len
BEGIN
SELECT @s1_char = SUBSTRING(@s1, @i, 1)
, @c = @i
, @cv0 = CAST(@i AS BINARY(2))
, @j = 1;
WHILE @j <= @s2_len
BEGIN
SET @c = @c + 1;
SET @c_temp = CAST(SUBSTRING(@cv1, @j + @j - 1, 2) AS INT)
+ CASE WHEN @s1_char = SUBSTRING(@s2, @j, 1)
THEN 0
ELSE 1
END;
IF @c > @c_temp
SET @c = @c_temp;
SET @c_temp = CAST(SUBSTRING(@cv1, @j + @j + 1, 2) AS INT)
+ 1;
IF @c > @c_temp
SET @c = @c_temp;
SELECT @cv0 = @cv0 + CAST(@c AS BINARY(2))
, @j = @j + 1;
END;
SELECT @cv1 = @cv0
, @i = @i + 1;
END;
RETURN @c;
END;
GO -
I have a question regarding this nice implementation. What happens when you have a string of less then four characters in length or two? I am noticing that it will obviously not rank it, so i tried to add a logical check for if the string input is less then four chars, do it per char not every two, but the desired outcome is not happening. Do you have any advice on tweaking this to handle strings less then 4 chars? Should it just be a LIKE clause at that point, and if so how to return score cards for it.
-Thanks-
Viewing 15 posts - 16 through 30 (of 34 total)
You must be logged in to reply to this topic. Login to reply