FTI Query over Joined tables is slow
-
Hi
I have a table with a full text index. I have a query which uses CONTAINS to search the table. This works well.
I now need to expand the query to also search in a parent table. The two tables are join with a primary/foreign key.
The parent table has a full text index and the columns I need to search are included in the index. The parent table is very small.
I added an Inner Join to the query and included the parent table search in an OR. For example:
select tb1.fields
from tb1 inner join tb2 on tb1.id = tb2.id
where contains(tb1.field, 'searchvalue')
OR contains (tb2.field, 'searchvalue')
The problem is the search is now slow. What am I doing wrong?
-
Might help to see the execution plan... Without that we are really just guessing. Maybe SQL isn't using the full text index? Maybe statistics are out of date so estimates are bad.
Seeing an execution plan will help a lot with this.
Is your search slow if you search in one table and then the other (ie do 2 searches outside of the join)? If not, you may benefit from making some temp tables/table variables and joining those instead?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi Brian
Thanks for getting back to me. I'll provide two version. The first version is without the OR which runs instantly. The second version is with the OR which takes about 60 seconds to run (it should be near instant).
Query Plan - without OR - runs instantly
SELECT TOP 1000
c.ID,
c.FullName AS Name,
c.Email,
c.AddressCompany,
c.AddressCareOf,
c.AddressStreet,
CONCAT(c.AddressCompany, ' ', c.AddressCareOf, ' ', c.AddressStreet) AS [Street Address],
CONVERT(VARCHAR(10), c.DateOfAquisition, 103) AS [Date of Acquisition],
CONVERT(VARCHAR(10), c.MailUnclaimed, 103) AS [Returned Mail Date],
c.SharesHeld AS Shares,
CONVERT(VARCHAR,ROUND(c.TotalAmount, 2)) AS Total,
c.NbrUnpaid AS Dividends,
c.Company,
c.AssetType AS [Asset Type],
Case when c.contactid is null then f.FileName else c.CaseTitle end AS [File Name],
c.ImportId,
c.PhoneStrings,
c.WCReference,
c.InitialContactReferenceNo,
c.RelationshipCode,
c.ContactId,
c.CaseImportId
FROM CS.WCContact c
join CS.Files f on f.fileid = c.fileid
where f.IsCurrent = 1
and ( CONTAINS((c.FullName), '"MCCALLUM"'))
Query Plan - with OR - runs in about 60 seconds (too slow)
SELECT TOP 1000
c.ID,
c.FullName AS Name,
c.Email,
c.AddressCompany,
c.AddressCareOf,
c.AddressStreet,
CONCAT(c.AddressCompany, ' ', c.AddressCareOf, ' ', c.AddressStreet) AS [Street Address],
CONVERT(VARCHAR(10), c.DateOfAquisition, 103) AS [Date of Acquisition],
CONVERT(VARCHAR(10), c.MailUnclaimed, 103) AS [Returned Mail Date],
c.SharesHeld AS Shares,
CONVERT(VARCHAR,ROUND(c.TotalAmount, 2)) AS Total,
c.NbrUnpaid AS Dividends,
c.Company,
c.AssetType AS [Asset Type],
Case when c.contactid is null then f.FileName else c.CaseTitle end AS [File Name],
c.ImportId,
c.PhoneStrings,
c.WCReference,
c.InitialContactReferenceNo,
c.RelationshipCode,
c.ContactId,
c.CaseImportId
FROM CS.WCContact c
join CS.Files f on f.fileid = c.fileid
where f.IsCurrent = 1
and ( CONTAINS((c.FullName), '"MCCALLUM"')
OR CONTAINS((f.filename), '"MCCALLUM"')
) -
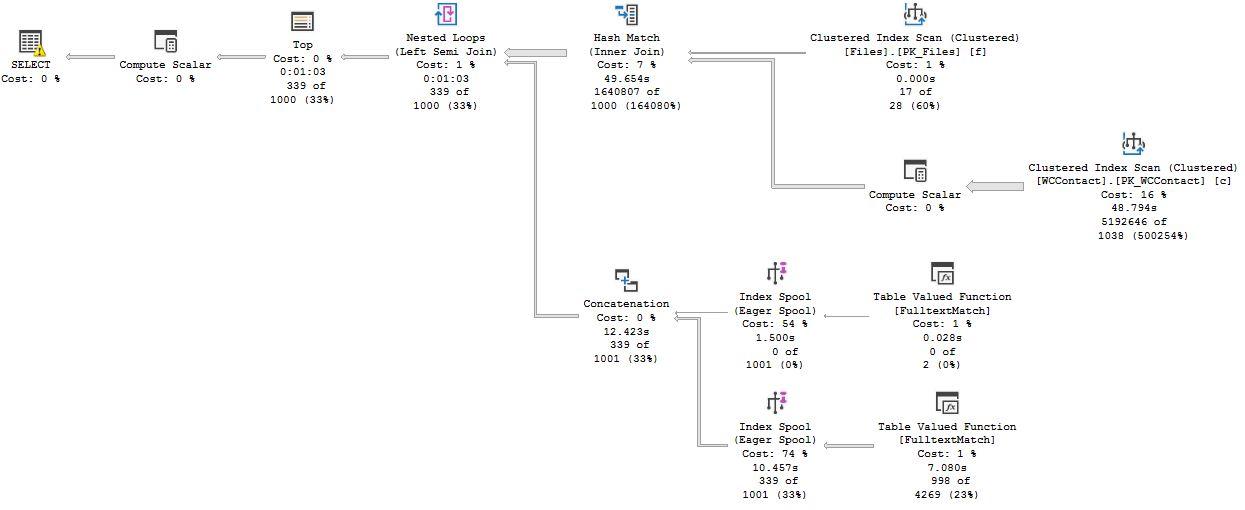
Looking at your execution plans, both of your FTI's are pretty quick. 0.028 seconds on one of them and 7.080 seconds on the other. The slow part is your clustered index scan which is taking 48 seconds to complete.
You also have a yellow triangle on your SELECT. would be interesting to see what warning it is giving you.
Having the full execution plan instead of screenshots would be a bit nicer to work with...
I would also be curious to see performance of:
SELECT TOP 1000
c.ID,
c.FullName AS Name,
c.Email,
c.AddressCompany,
c.AddressCareOf,
c.AddressStreet,
CONCAT(c.AddressCompany, ' ', c.AddressCareOf, ' ', c.AddressStreet) AS [Street Address],
CONVERT(VARCHAR(10), c.DateOfAquisition, 103) AS [Date of Acquisition],
CONVERT(VARCHAR(10), c.MailUnclaimed, 103) AS [Returned Mail Date],
c.SharesHeld AS Shares,
CONVERT(VARCHAR,ROUND(c.TotalAmount, 2)) AS Total,
c.NbrUnpaid AS Dividends,
c.Company,
c.AssetType AS [Asset Type],
Case when c.contactid is null then f.FileName else c.CaseTitle end AS [File Name],
c.ImportId,
c.PhoneStrings,
c.WCReference,
c.InitialContactReferenceNo,
c.RelationshipCode,
c.ContactId,
c.CaseImportId
FROM CS.WCContact c
join CS.Files f on f.fileid = c.fileid
where f.IsCurrent = 1
and ( CONTAINS((f.filename), '"MCCALLUM"')
)Basically the same query but only running the newly added part.
I think your statistics may be out of date for something as those row estimates are pretty off. 5,192,646 rows of 1,038 is DRASTICALLY off AND is also one of the slowest operations in there. Something is making the optimizer guess VERY wrong on how many rows are coming back.
You said that the two tables are joined on a PK/FK, is that on the fileid column? And is that a clustered index on fileid?
To make this a bit easier, could you post the DDL for these 2 tables?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hi Brian
I've saved the Execution Plan of the slow query and attached it here.
Here is the warning message:
Type conversion in expression (CONVERT(varchar(10),[c].[DateOfAquisition],103)) may affect "CardinalityEstimate" in query plan choice, Type conversion in expression (CONVERT(varchar(10),[c].[MailUnclaimed],103)) may affect "CardinalityEstimate" in query plan choice, Type conversion in expression (CONVERT(varchar(30),round([c].[TotalAmount],(2)),0)) may affect "CardinalityEstimate" in query plan choice
I ran the query you provided and it's instant because there is no match on that search.
Possibly statistics is out of date. Not long ago we removed a large number of records from CS.WCContact. It went from 18 million to 5 million records. The total in CS.Files is only 32 records.
Yes the CS.WCContact and CS.Files tables are linked with FileId which is a clustered index primary key in CS.Files.
Here is the Create script for CS.WCContact
CREATE TABLE [CS].[WCContact](
[ID] [int] IDENTITY(1,1) NOT NULL,
[FullName] [nvarchar](300) NULL,
[AddressCompany] [nvarchar](300) NULL,
[AddressCareOf] [nvarchar](300) NULL,
[AddressStreet] [nvarchar](300) NULL,
[AddressPostCode] [nvarchar](300) NULL,
[Domicile] [nvarchar](300) NULL,
[SharesHeld] [int] NULL,
[DateOfAquisition] [date] NULL,
[CaseTitle] [nvarchar](300) NULL,
[Company] [nvarchar](250) NULL,
[AssetType] [nvarchar](250) NULL,
[NbrUnpaid] [int] NULL,
[TotalAmount] [money] NULL,
[OrdClassTotal] [int] NULL,
[DateLodged] [date] NULL,
[LodgedBy] [nvarchar](150) NULL,
[ReceiptDate] [date] NULL,
[MailUnclaimed] [date] NULL,
[Category] [nvarchar](300) NULL,
[YearOfReturn] [int] NULL,
[Returned] [bit] NULL,
[ClaimStatus] [nvarchar](250) NULL,
[DatePayable] [date] NULL,
[GroupID] [int] NULL,
[Created] [datetime] NULL,
[Modified] [datetime] NULL,
[IsDeleted] [bit] NULL,
[Email] [nvarchar](255) NULL,
[ImportId] [nvarchar](100) NULL,
[PhoneStrings] [nvarchar](350) NULL,
[WCReference] [nvarchar](100) NULL,
[InitialContactReferenceNo] [nvarchar](100) NULL,
[zzzCaseTitle] [nvarchar](250) NULL,
[ContactId] [uniqueidentifier] NULL,
[VersionNumber] [nvarchar](255) NULL,
[RelationshipCode] [nvarchar](20) NULL,
[CaseImportId] [nvarchar](100) NULL,
[FileId] [int] NULL,
CONSTRAINT [PK_WCContact] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [CS].[WCContact] WITH CHECK ADD CONSTRAINT [FK_WCContact_FileId] FOREIGN KEY([FileId])
REFERENCES [CS].[Files] ([FileId])
GO
ALTER TABLE [CS].[WCContact] CHECK CONSTRAINT [FK_WCContact_FileId]And here is the Create script for CS.Files
CREATE TABLE [CS].[Files](
[FileId] [int] IDENTITY(1,1) NOT NULL,
[FileName] [nvarchar](500) NOT NULL,
[LocationId] [int] NULL,
[IsCurrent] [bit] NOT NULL,
[TotalContacts] [int] NULL,
[DateCreatedUTC] [datetime] NULL,
[DateModifiedUTC] [datetime] NULL,
CONSTRAINT [PK_Files] PRIMARY KEY CLUSTERED
(
[FileId] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY],
CONSTRAINT [UnCSFiles_FileName] UNIQUE NONCLUSTERED
(
[FileName] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [CS].[Files] WITH CHECK ADD CONSTRAINT [FK_Files_LocationId] FOREIGN KEY([LocationId])
REFERENCES [CS].[Locations] ([LocationId])
GO
ALTER TABLE [CS].[Files] CHECK CONSTRAINT [FK_Files_LocationId]Cheers
-
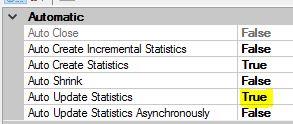
A few thoughts here. First, update statistics if auto update statistics is not on. And it may even help if that is on.
Second thought - I think you forgot to attach the execution plan.
Third, I am wondering if you get better performance by adding an index on your WCContact table on the FileID column? I think this will give you the best performance increase for this one query, but will come at a cost as well. Building the index, as there are 5 million rows, will be slow and it will affect insert, update and delete performance as well as increase the table size and thus backup size.
Last thought - does running that query I suggested but with a valid value return near instantly? If so, you might get a performance benefit by running the first query UNIONed to my query rather than with the OR. Makes for longer code and you end up with some duplicated code as you are copy-pasting the query and just changing one small part of the WHERE, but if the 2 queries individually complete in under 1 second, UNIONing them should result in roughly the time for each query combined. It will have additional overhead of doing a DISTINCT on the result set, but if the result set is small enough, you shouldn't notice much difference. OR if you are confident that there won't be duplicate rows in the 2 data sets, you could use a UNION ALL which will give a performance boost as you are no longer getting a distinct list.
Of the options I listed above, updating statistics is the first one I'd do as that should be done regularly anyways. It might not help, but it is very unlikely that it hurt. Next, I'd try the query with the UNION instead of the OR as I think this is the easiest change to make that should have a decent performance boost. Last thing I'd change is the index and that is only because of the performance hit to other operations and that it will likely be the most time consuming change. Short code change as the create index syntax isn't too long, but execution time on 5 million rows will be time consuming.
NOTE- the above suggestions are done without seeing the actual execution plan, just the screenshot of it. I am fairly confident the suggestions above are valid even without seeing the execution plan and all of them are easy to undo if things get worse except for updating statistics. That is a one-way change as far as I know.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
The file upload got rejected. Here is a link to download the file:
https://1drv.ms/u/s!AgdNTno_yQL5g8kC7isX-EBVjaZAMw?e=pmJIl2
Thanks for your advice. I will review and get back to you today.
-
Hi Brian
I have added a non-clustered index to the foreign key:
CREATE NONCLUSTERED INDEX IX_WCContact_ContactId ON CS.WCContact ( FileId ASC)
I have updated statistics:
UPDATE STATISTICS [CS].[WCContact] WITH FULLSCAN
I ran the full query again and the execution time is now 60 seconds. It's only a very small improvement. Looking the at the execution plan it doesn't even appear to use the index.
Here are the auto-index settings. Note: this is an Azure SQL Server (serverless).
These tables are mostly read-only, like a data-mart, so adding more indexes is not a problem.
I ran the query with only the CONTAINS on the Files table and it ran instantly.
SELECT ....
FROM CS.WCContact c join CS.Files f on f.fileid = c.fileid
where f.IsCurrent = 1 and CONTAINS((f.filename), '"CBA"')
Your Union suggestion looks interesting. I'll have a shot at that and get back to you.
Sam
-
Hi Brian
I had a look at using the union approach but it's not going to work. The query is actually more complex. It's dynamically generated based on how many search terms there are. I provided an example where there was only one search term, but when there is multiple the WHERE clause looks like this:
where f.IsCurrent = 1
and(
CONTAINS((c.FullName,c.AddressCompany,c.AddressCareOf,c.AddressStreet,c.Email,c.Company,c.ImportId,c.PhoneStrings,c.WCReference,c.InitialContactReferenceNo,c.CaseImportId,c.CaseTitle), '"ALWYN"')
OR CONTAINS((f.filename), '"ALWYN"')
)
AND
(
CONTAINS ((c.FullName,c.AddressStreet,c.AddressCompany,c.AddressCareOf,c.Email,c.Company,c.ImportId,c.PhoneStrings,c.WCReference,c.InitialContactReferenceNo,c.CaseImportId,c.CaseTitle), '"unclaimed"')
OR CONTAINS((f.filename), '"unclaimed"')
)Now it's getting to complicated to take the Union approach.
I'm starting to think FTI doesn't work well over multiple tables, and it's best to have a single denormalised table.
Two ideas I have:
- Create an indexed view on cs.wccontact which includes the parent FileName. I believe FTI works on indexed views.
- Create a persisted calculated field on cs.wccontact for FileName. The fields would have to utilise a scalar function.
Let me know if anything comes up on the Execution Plan.
Cheers,
Sam
One thought is I could create an Indexed
-
Looking at the execution plan, the slow operation is pulling the 5 million rows from the Contacts table into memory. It is taking over 40 seconds to pull the 5 million rows into memory, so reducing those rows will improve performance.
Of those 5 million rows, only 1.6 million rows are actually matching the join and it is only after that join happens that the FTI's are being used when the OR is in place. Getting the 5 million rows into memory is the slow operation that I think needs to be improved. And of those 1.6 million rows, only 483 are actually used after the FTI is applied in the execution plan you provided.
I am not seeing anything to tweak or change in the query that too useful. The indexed view may help, but I think you will hit the same snag that your JOIN is causing. The reason that the queries run fast when you don't have the OR is that it can filter the individual table prior to joining it. Once that OR comes into play, the query optimizer decides it is faster to get the data from the tables and the FTI's separately and join those. Having the calculated column would likely help performance as you no longer need the join, but if you need to update anything, it becomes a bigger pain in the butt.
That being said, you indicated that this set of tables does not get changed often; is it more for reporting purposes? If so, you will get a performance benefit by de-normalizing the data. Will end up with a lot more repeated data (as you only have 20-ish "Current"files for 1.6 million contacts) and if/when you need to do updates it will be incredibly slow. It also increases the risk that some data may be inaccurate (ie ccontact ABC and DEF both use file XYZ. You decide file XYZ is no longer current and you update contact ABC but forget to update contact DEF).
If you don't need realtime data for this, you could benefit from creating a scheduled SSIS package or stored procedure (or some form of ETL) to denormalize the data into a wider table. Downside to this is if you switch a file from IsCurrent 1 to 0 (for example) you would need to run the de-normalize job or the de-normalized table will still have the old data. First run of the ETL would be slower as you would be moving all data, but after that, you are just updating, inserting or deleting rows that have changed.
If you need near-realtime data, triggers on the main 2 tables to push the changes over to the "reporting" table should be pretty quick. If the tables are changing frequently, service broker may be a safer option as it is asynchronous.
Also, as that index didn't provide that much benefit, I'd remove it. It isn't helping the query enough and it is hurting insert, update and delete performance for sure.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
if only the where is generated but remaining query remains the same maybe changing it slightly could influence QE to choose a different path.
note that for the following the index mentioned above should be created
change
FROM CS.WCContact c
join CS.Files f on f.fileid = c.fileid
where f.IsCurrent = 1
to
from CS.Files f
outer apply (select top 200000 --(or lower if you know max number of records that can exist)
*
from CS.WCContact c
where c.fileid = f.fileid
order by c.fileid
) c
where c.fileid is not null -- so it behaves as a inner join
and f.IsCurrent = 1 -
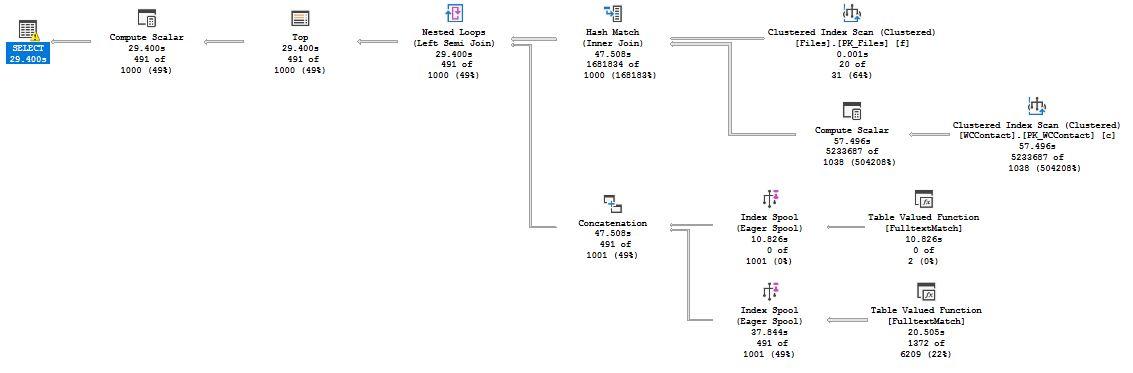
Hi Brian
I agree that a single de-normalized table is best with FTI. I created an indexed view which contains the fields from both tables and created the FTI on the View. It's super fast now. Here is the query plan:
Thanks for all your help with this one. It's been a great learning experience for me.
And thank you frederico for your idea. I tried using this approach but I got this error:
Cannot use a CONTAINS or FREETEXT predicate on column 'FullName' because it is not full-text indexed.
I think FTI doesn't like columns coming from a sub-query.
Sam



Viewing 12 posts - 1 through 12 (of 12 total)
You must be logged in to reply to this topic. Login to reply