finding SQL duplicates based on different parameters
-
Hi, I need to write a query (or a series of queries) that will allow me to find when two clients are living in the same house.
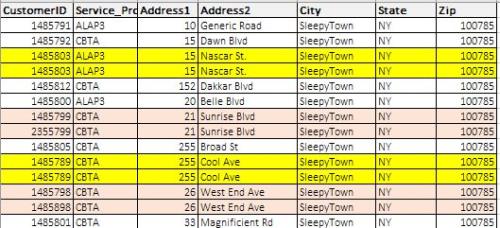
The data looks like the dataset (see sample dataset below).
The first thing I want to do is to find all the duplicate addresses in the dataset which I can already accomplish with a simple query using group by (see query 1 below).
The next thing I need to do is to figure out how many clients live in the same address in other words the address must be a duplicate but the “customerID” must be different for example in the sample dataset below you can see that customerIDs 1485799, 2355799 share the same address at 21 Sunrise Blvd , SleepyTown NY 100785, those are the type of records I need to find across thousands of entries in the database. This is the part that I am having a problem figuring out, Any ideas? - Your help is most appreciated.
Sample Data

Query 1
Select
street_number,
street,
City,
State,
Zip,
count (*) as number_of_records
from
clients
group by
street_number, street, City, State, Zip
having
count(*) > 1 -
I think that group by along with having clause is what you are after, such as:
select customer_id
,street_number
,street
,City
,State
,Zip
from your_table
group by
,street_number
,street
,City
,State
,Zip
having COUNT(*) > 1 - migurus - Wednesday, May 30, 2018 11:00 PM
Almost, but not quite... that would also pick up mere duplicates.
Let's try it this way:SELECT MIN(customer_id) AS MIN_CustID,
MAX(customer_id) AS MAX_CustID,
street_number,
street,
City,
[State],
Zip
FROM your_table
GROUP BY
street_number,
street,
City,
[State],
Zip
HAVING COUNT(*) > 1
AND MIN(customer_id) <> MAX(customer_id)
ORDER BY
[State],
City,
street,
street_number,
Zip;Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy)
Viewing 3 posts - 1 through 3 (of 3 total)
You must be logged in to reply to this topic. Login to reply