Express edition DB crossing limit
-
We have an express edition database and performing bulk import into a table.
Table details when fully imported:-
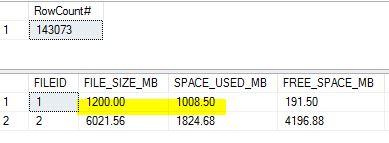
number of rows - 143,073
ReservedKB - 66136, Data - 66136, IndexKB - 43352, UnusedKB - 317648
Data file details when fully populated:
File size - 10273 MB, Used space - 1348.56 MB, Free Space - 8924.44 MB
When we truncate the table, used space is little less than a GB and when fully imported, it grows to less than 1.4 GB. Problem is data file size increases from 1 GB to 10273 MB during import activity even though the amount of data is too less. I cant figure out where the space is getting consumed in the data file. The moment it reaches 10273 MB, SQL Server starts rolling back the transaction with the following message:
CREATE DATABASE or ALTER DATABASE failed because the resulting cumulative database size would exceed your licensed limit of 10240 MB per database.
This is an old process running fine for years on SQL Server 2008 R2 but has started to fail on SQL Server 2016. Unused space for that table is unusually high. Also, no other activity /major transaction happens during test of import.
Any clues?
Regards
Pradeep Singh -
first thing i would look at was HEAP tables. unless you get a table lock, you could have rows that were deleted but never returned their space back to the database.
next, i would consider creating a Staging database for the ETL, and only move the final data
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
GO
SELECT 'Identify any HEAP tables AND the amount OF they are reserving due to updates and deletes' AS Notes
SELECT QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.' + QUOTENAME(OBJECT_NAME([idx].[object_id])) AS [QualifiedObject] ,
OBJECT_SCHEMA_NAME([idx].[object_id]) AS [SchemaName] ,
OBJECT_NAME([idx].[object_id]) AS [table_name] ,
[fn].[forwarded_record_count] ,
[fn].[avg_fragmentation_in_percent] ,
[fn].[page_count] ,
'ALTER TABLE ' + QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.' + QUOTENAME(OBJECT_NAME([idx].[object_id])) + ' REBUILD;' AS [QuickFix] ,
CASE WHEN [colz].[is_nullable] = 1
THEN 'ALTER TABLE ' + QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.' + QUOTENAME(OBJECT_NAME([idx].[object_id])) + ' ALTER COLUMN '
+ QUOTENAME([colz].[name]) + ' ' + UPPER(TYPE_NAME([colz].[user_type_id])) + ' '
+ CASE
-- data types with precision and scale IE DECIMAL(18,3), NUMERIC(10,2)
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'decimal', 'numeric' )
THEN '(' + CONVERT(VARCHAR, [colz].[precision]) + ',' + CONVERT(VARCHAR, [colz].[scale]) + ') ' + SPACE(6
- LEN(CONVERT(VARCHAR, [colz].[precision])
+ ','
+ CONVERT(VARCHAR, [colz].[scale])))
+ SPACE(7) + SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
+ CASE WHEN COLUMNPROPERTY([idx].[object_id], [colz].[name], 'IsIdentity') = 0 THEN ''
ELSE ' IDENTITY(' + CONVERT(VARCHAR, ISNULL(IDENT_SEED(QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.'
+ QUOTENAME(OBJECT_NAME([idx].[object_id]))), 1)) + ','
+ CONVERT(VARCHAR, ISNULL(IDENT_INCR(QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.'
+ QUOTENAME(OBJECT_NAME([idx].[object_id]))), 1)) + ')'
END
-- data types with scale IE datetime2(7),TIME(7)
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'datetime2', 'datetimeoffset', 'time' )
THEN CASE WHEN [colz].[scale] < 7 THEN '(' + CONVERT(VARCHAR, [colz].[scale]) + ') '
ELSE ' '
END + SPACE(4) + SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id]))) + ' '
--data types with no/precision/scale,IE FLOAT
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'float' ) --,'real')
THEN
--addition: if 53, no need to specifically say (53), otherwise display it
CASE WHEN [colz].[precision] = 53
THEN SPACE(11 - LEN(CONVERT(VARCHAR, [colz].[precision]))) + SPACE(7) + SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
ELSE '(' + CONVERT(VARCHAR, [colz].[precision]) + ') ' + SPACE(6 - LEN(CONVERT(VARCHAR, [colz].[precision]))) + SPACE(7)
+ SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
END
--data type with max_length ie CHAR (44), VARCHAR(40), BINARY(5000),
--##############################################################################
-- COLLATE STATEMENTS
-- personally i do not like collation statements,
-- but included here to make it easy on those who do
--##############################################################################
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'char', 'varchar', 'binary', 'varbinary' )
THEN CASE WHEN [colz].[max_length] = -1
THEN '(max)' + SPACE(6 - LEN(CONVERT(VARCHAR, [colz].[max_length]))) + SPACE(7) + SPACE(16
- LEN(TYPE_NAME([colz].[user_type_id])))
ELSE '(' + CONVERT(VARCHAR, [colz].[max_length]) + ') ' + SPACE(6 - LEN(CONVERT(VARCHAR, [colz].[max_length]))) + SPACE(7)
+ SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
END
--data type with max_length ( BUT DOUBLED) ie NCHAR(33), NVARCHAR(40)
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'nchar', 'nvarchar' )
THEN CASE WHEN [colz].[max_length] = -1
THEN '(max)' + SPACE(5 - LEN(CONVERT(VARCHAR, ( [colz].[max_length] / 2 )))) + SPACE(7) + SPACE(16
- LEN(TYPE_NAME([colz].[user_type_id])))
ELSE '(' + CONVERT(VARCHAR, ( [colz].[max_length] / 2 )) + ') ' + SPACE(6 - LEN(CONVERT(VARCHAR, ( [colz].[max_length] / 2 ))))
+ SPACE(7) + SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
END
WHEN TYPE_NAME([colz].[user_type_id]) IN ( 'datetime', 'money', 'text', 'image', 'real' )
THEN SPACE(18 - LEN(TYPE_NAME([colz].[user_type_id])))
-- other data type IE INT, DATETIME, MONEY, CUSTOM DATA TYPE,...
ELSE SPACE(16 - LEN(TYPE_NAME([colz].[user_type_id])))
+ CASE WHEN COLUMNPROPERTY([idx].[object_id], [colz].[name], 'IsIdentity') = 0 THEN ' '
ELSE ' IDENTITY(' + CONVERT(VARCHAR, ISNULL(IDENT_SEED(QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.'
+ QUOTENAME(OBJECT_NAME([idx].[object_id]))), 1)) + ','
+ CONVERT(VARCHAR, ISNULL(IDENT_INCR(QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.'
+ QUOTENAME(OBJECT_NAME([idx].[object_id]))), 1)) + ')'
END + SPACE(2)
END + ' NOT NULL;'
ELSE ''
END + CHAR(13) + CHAR(10) + 'GO' + CHAR(13) + CHAR(10)
+ '--CREATE CLUSTERED INDEX IX_' + REPLACE(REPLACE(REPLACE(OBJECT_NAME(idx.object_id), '_', ''),
' ', ''), '-', '') + '_'
+ REPLACE(REPLACE(REPLACE(colz.name, '_', ''), ' ', ''), '-', '') + ' ON ' + QUOTENAME(OBJECT_SCHEMA_NAME(idx.object_id)) + '.'
+ QUOTENAME(OBJECT_NAME(idx.object_id)) + ' (' + QUOTENAME(ISNULL(colz.name,
'column_1'))
+ ');' + CHAR(13) + CHAR(10) + 'GO' + CHAR(13)
+ '--ALTER TABLE ' + QUOTENAME(OBJECT_SCHEMA_NAME([idx].[object_id])) + '.'
+ QUOTENAME(OBJECT_NAME([idx].[object_id])) + ' ADD CONSTRAINT PK_' + REPLACE(REPLACE(REPLACE(OBJECT_NAME([idx].[object_id]), '_', ''), ' ', ''), '-', '')
+ '_' + REPLACE(REPLACE(REPLACE([colz].[name], '_', ''), ' ', ''), '-', '') + ' PRIMARY KEY CLUSTERED (' + QUOTENAME(ISNULL([colz].[name], 'column_1')) + ');'
+ CHAR(13) + CHAR(10) + 'GO' + CHAR(13) + CHAR(10) AS [SuggestedCreatePK]
FROM [sys].[indexes] [idx]
LEFT JOIN [sys].[columns] [colz] ON [idx].[object_id] = [colz].[object_id]
AND [colz].[column_id] = 1
CROSS APPLY [sys].[dm_db_index_physical_stats](DB_ID(), [idx].[object_id], DEFAULT, DEFAULT, 'SAMPLED') [fn]
WHERE [idx].[index_id] = 0
ORDER BY [fn].[forwarded_record_count] DESC;
Lowell
--help us help you! If you post a question, make sure you include a CREATE TABLE... statement and INSERT INTO... statement into that table to give the volunteers here representative data. with your description of the problem, we can provide a tested, verifiable solution to your question! asking the question the right way gets you a tested answer the fastest way possible! -
Thanks Lowell. The table is a clustered one. Data from this table is removed and fresh data is imported everytime. There is just problem that i see so far. Developers are using delete instead of truncate here and entire operation (delete/bulk import) is a part of single transaction. I will ask for modification and see how it goes.
Pradeep Singh -
I tried importing the access file (49 MB) on both new (sql server 2016 express) and old servers(sql server 2081 R2 Express). New server's data file size increases from 1 GB to 10 GB and rolls back the transaction. Old server increases its data file size by few MBs. We restored same database on the new server for testing.
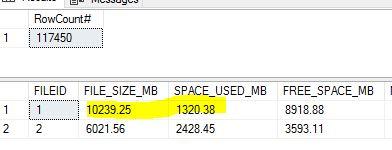
These images will explain before and after import sizes. Please note that used space used has increased
**Before import. Table already has data. It will be removed and fresh data inserted.

**During import. File size increases to max, though used space increases by ~300 MB only.
Pradeep Singh -
Some further updates:
.net process is something like this:
1. begin tran
2. delete from table
3. bulk import access file
4. commit
Since the process was failing mid way due to file size exceeding 10 GB, it used to rollback.
For trial, i truncated the table manually and started the process. and things go back to normal. File size remain as it is. import happens in 10 secs (normal) instead of 2 mins. I imported the file more than 10 times and dont see that behavior anymore.
Net net - i am unable to understand this behavior (or bug?) Though the process is stable now, i would request someone to shed some light on this unexpected behavior.
Pradeep Singh -
A thought and a suggestion on this.
My thought is, what is the growth setting for the database? Is it a percent or fixed rate? If it's a percentage, change it to a fixed size or even just set the DB to 10GB and turn off growth. Further, what's the recovery model of the database, simple, full, or bulk? If it's full or bulk, make sure you've got transaction log backups running.
The suggestion is, get the developers to ideally change the process a bit. My suggestion would be do it in two transactions, the first doing a truncate, not a delete, the second would check if the truncate succeeded, then do the insert.
As for why it's recently started running into a problem, that I don't have any speculation on.
-
Thanks Jasona. Recovery model was full and i changed it to simple. Also, truncate as i mentioned in previous reply wasnt the solution. The problem started repeating after sometime. Then i removed the table and recreated it and imported the file over 30 times but didnt see the problem. Also, earlier i had changed auto growth to 512 MB/fixed it to 10 GB but that didnt help as well. Even though the problem has not recurred yet, we have decided to move to web edition for this db. This is a trial phase for 2016 (for a process running fine in 2008 R2 for years) and we dont want to run into this trouble again as we dont know the cause of this erratic behavior.
Log backups were running as well, though the problem was not with the log file, it was the db file..
Pradeep Singh
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply