Dynamically Create Warehouse Dimensions
-
Comments posted to this topic are about the item Dynamically Create Warehouse Dimensions
-
I did not quite understand the purpose and the end result. I think you could provide some use cases.
-
Nehehe,
The technique illustrated in my article is used to create data warehouse dimensions that represent code sets. This scenario isn't a one-size-fits-all solution, but more often than not, it's quite helpful.
In a transactional model, users can sometimes select multiple values for a given data point. My example uses an "item" code set. Since customers can purchase multiple "items," a record would be saved for each item in the transactional model. In the analytical model, the data must often be pivoted into a single row that represents the "items" customers purchased. This is a common practice in data warehouses that employ star schemas where you would only have a single row in each dimension that represents a given fact (measure).
I hope this sheds a little more light. 🙂
-Craig
-
I've been doing OLAP designs for a long time now and I don't understand what you're doing here. A clearer explanation at the beginning and maybe some illustration of what would look like in a cube would be very helpful. Is this some sort of junk dimension? The 0s and 1s would seem to indicate this. But you don't use the term. You may just not be familiar with it.
An aside, the zero isn't a "best practice." I won't knock it as I often use the 0 for my unknown bucket. My I think most would recommend a -1. The zero has rarely given my any issue, but I have been slowly migrating to -1 anyway.
-
Hi RonKyle,
This approach creates non-junk dimensions that employ bit columns, each of which represents selected code values in a given code set. This results in a fixed-length, very-rarely-changing dimension (it would only change when new codes were added to a respective code set).
At ETL-time, you would simply select and store the applicable ID of the dimension row that represents the combination of code values for the given fact.
The zero row is indeed used for unknowns.
Hope this helps!
-Craig
-
As it's not a junk dimension, it unfortunately doesn't help. It's not clear to me what business or technical problem is being solved by this method. Can you include a snapshot or two of what this looks like in an SSAS and/or Excel environment.
-
RonKyle,
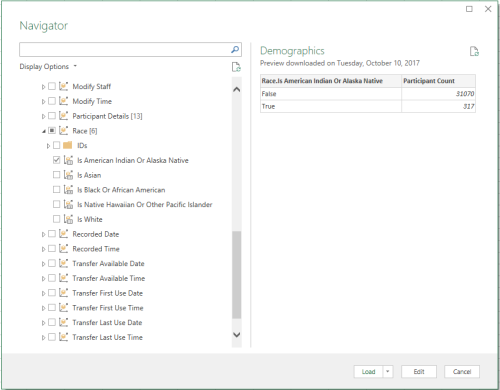
I see your point about junk dimensions, as that's where one would normally stick lone indicators. But the solution documented here fits the case for code sets on which analysis is desired. Case in point, take "race," which is very important in the healthcare industry. I've attached a screenshot for you.
-Craig
-
Thanks! That was very helpful. It's possible that only one would be checked per person, but it's also very possible that multiple checks could apply. But all the choices are related, so it's not a junk dimension. I can't think that I've ever created a dimension that does something like this before.
-
You're welcome, Ron. This is something I've had to do a lot in the healthcare domain. Data points like vital event conditions, e.g. birth / death conditions, etc. are perfect candidates for this type of fixed dimension (a Kimball "0" type of SCD). -Craig
Viewing 9 posts - 1 through 9 (of 9 total)
You must be logged in to reply to this topic. Login to reply