Dependency Chain
-
I have not yet been able to come up with a tidy solution for this one. An ETL process I've built has a series of 'get' procs which need to execute in level order. All in Level 1, then all in level2 etc. There are currently 34 of these, the list is growing and it's increasingly complex, so I decided to build some code to make sure I get the running order right.
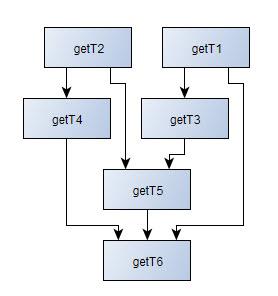
I'll jump in with my sample data. First, here is a diagram showing the desired execution order.

Here is my sample data and code for the top-level execution:
DROP TABLE IF EXISTS #deps;
CREATE TABLE #deps
(
ProcedureName NVARCHAR(128) NOT NULL
, SchemaName NVARCHAR(128) NOT NULL
, BaseTableName NVARCHAR(128) NOT NULL
, ReferencedEntity NVARCHAR(128) NOT NULL
);
INSERT #deps
(
ProcedureName
, SchemaName
, BaseTableName
, ReferencedEntity
)
VALUES
(N'getT1', N'sch1', N'T1', N'T1')
, (N'getT2', N'sch1', N'T2', N'T2')
, (N'getT3', N'sch1', N'T3', N'T1')
, (N'getT3', N'sch1', N'T3', N'T3')
, (N'getT4', N'sch1', N'T4', N'T2')
, (N'getT4', N'sch1', N'T4', N'T4')
, (N'getT4', N'sch1', N'T5', N'T2')
, (N'getT4', N'sch1', N'T5', N'T3')
, (N'getT4', N'sch1', N'T5', N'T5')
, (N'getT5', N'sch1', N'T5', N'T2')
, (N'getT5', N'sch1', N'T5', N'T3')
, (N'getT5', N'sch1', N'T5', N'T5')
, (N'getT6', N'sch1', N'T6', N'T1')
, (N'getT6', N'sch1', N'T6', N'T4')
, (N'getT6', N'sch1', N'T6', N'T5');
SELECT ProcedureName
, SchemaName
, BaseTableName
, ReferencedEntity
FROM #deps
ORDER BY ReferencedEntity;
--Execution Order 1
SELECT ProcedureName
, ExecutionOrder = 1
FROM #deps
GROUP BY ProcedureName
HAVING COUNT(*) = 1;
--Subsequent executions?(The code which creates and populates the #deps table was straightforward and is already written.)
Every proc has its own base table – this is the table that the proc populates and is not a dependency (BaseTableName = ReferencedEntity).
Thus, determining execution order 1 is easy … the procs getT1 and getT2 reference only their own base table and no other tables.
Is there a tidy way of getting the procs for execution orders 2, 3 and 4?
Thanks for any assistance.
-
If your ETL is done with SSIS, I am pretty sure you can set that up to execute things in a specific order. So you can have it wait for getT1 and getT2 to finish before it starts getT3 and so on.
If the ETL is done entirely inside SQL Server, the tidiest way I can think to do it would be to have a table (or something) that can monitor for task completion and each stored procedure checks that table and if all dependencies are not complete (ie getT3 can't start until getT1 and getT2 is complete), then it waits for a specified amount of time depending on how long the previous steps take to complete.
Where this will get messy is if getT1 succeeds and getT2 fails, getT3 will be waiting forever.
One nice thing about this method is you don't need to check the table for ALL previous dependencies, just the previous level of dependencies. getT6 doesn't care about getT1, so it only needs to watch for getT5 to complete successfully. So adding additional layers to it is pretty easy to do too. Each step needs to check for previous completion at the start and mark off that it is complete at the end. So if you added a getT7 and getT8 that both depend on getT6, it's adding 2 more rows to the Order table and you are good to go making getT7 and getT8. As it is a lot of duplicated code, you could always make a stored procedure to check for previous dependencies instead of having IF blocks with WAITs in the start of each SP, assuming they all will have similar wait times.
The dependency table approach gets messy once you try using the logic you have to determine order for 2, 3, and 4 and so on. If that is the approach you want though, you'll need to likely do a recursive CTE so you can get all of the layers for the mappings. By the time you get to T6, you need to look at if T5 is complete, and T1 and T2. Then the recursive call will check what needs to be complete for T5 to be called done and you get T5, T3, and T2. Considering you are doing things in layers (T1 & T2 then T3 & T4 then T5 then T6), I think it may make more sense to have a "completed" table rather than a dependency table, but that's just me. Downside for the completed table is that it relies on you having a good definition of what order 1, 2, 3, 4, and so on is. IF you decided that getT5 can start when getT3 and getT2 complete without worrying about the status of getT4, then it may get messy for SSIS, but still pretty easy with a "completed" table.
I still prefer using SSIS to call the SP's as you can control the flow from there, but it may not make sense in your particular scenario. Plus with SSIS, if you decided that getT5 doesn't need to wait for getT4, you can always adjust the flow in SSIS so getT6 will wait for getT1, getT4, and getT5 to complete and have getT5 start as soon as getT2 and getT3 are complete. You can control the flow MUCH easier and without a bunch of wait logic. Downside is that it is SSIS so you are adding another layer of abstraction to your ETL IF you were previously relying only on TSQL and stored procedures to solve this.
I do feel that SSIS is the right tool for the job though and that trying to make TSQL/SP's manage it will result in a lot of extra overhead and complexity. Now if you have SQL express, I am pretty sure that doesn't come with SSIS, so TSQL/SP's may be your only option, but if you are on Standard or higher, I recommend migrating this logic to SSIS where the diagram you drew is basically what SSIS would look like.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
It took some testing to get the recursion working. From the reference paths it's not clear how to proceed tho. Maybe you're looking for the maximum level for each ProcedureName?
with
base_cte as (
select ProcedureName, BaseTableName
from #deps
group by ProcedureName, BaseTableName
having sum(case when BaseTableName <> ReferencedEntity then 1 else 0 end) = 0),
tree_cte as (
select
root_proc = bc.ProcedureName,
ProcedureName,
BaseTableName,
level = 1,
path = cast(bc.ProcedureName as nvarchar(max))
from base_cte bc
union all
select
tc.root_proc,
d.ProcedureName,
d.BaseTableName,
tc.level + 1,
tc.path + ' -> ' + d.ProcedureName
from tree_cte tc
join #deps d on d.ReferencedEntity = tc.BaseTableName
and d.ProcedureName <> tc.ProcedureName
and d.BaseTableName <> d.ReferencedEntity)
select distinct
root_proc,
ProcedureName,
BaseTableName,
level,
path
from tree_cte
order by root_proc, level, ProcedureName;Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Wow, I just wrote a long response to Brian's message and after hitting Submit, I got an 'Are you sure you want to do that?' error and my text got wiped. What a wind-up.
Are there some issues with e-mail notifications at the moment? I have not received any today, despite your responses to my own thread.
I'm very familiar with SSIS and yes, it could have been used here. For now, however, we're sticking with a straight T-SQL solution. The volumes are quite small and executing all the procs in series (a master 'run all' proc does this) takes less than two minutes. Thus there's no need to check for proc completion. If one of the procs fails, the whole process bombs out there and then.
When I originally set this all up, I checked all of the dependencies manually. Only recently has it come to light that I missed one (luckily, this caused an error rather than running successfully but shafting the data). I don't want to maintain this dependency list manually in future, as there will be new procs and changes to the existing procs whose effects would need to be assessed if there are changes to the tables in those procs.
-
Steve, thank you for taking the time to code and test this. I've not written many rCTEs in the past and my brain has trouble composing them. I'd tried and failed!
I realise now that, for clarity, I should have included full expected results with my original post.
This is the resultset I am looking for, using MAX as you suggested – your CTE works perfectly.
SELECT ProcedureName
, MAX(level)
FROM tree_cte
GROUP BY tree_cte.ProcedureName
ORDER BY MAX(level)
, ProcedureName;I also realise that my sample data included spurious and incorrect 'getT4' rows. Here is a modified version of the same data which actually corresponds with the diagram I posted:
INSERT #deps
(
ProcedureName
, SchemaName
, BaseTableName
, ReferencedEntity
)
VALUES
(N'getT1', N'sch1', N'T1', N'T1')
, (N'getT2', N'sch1', N'T2', N'T2')
, (N'getT3', N'sch1', N'T3', N'T1')
, (N'getT3', N'sch1', N'T3', N'T3')
, (N'getT4', N'sch1', N'T4', N'T2')
, (N'getT4', N'sch1', N'T4', N'T4')
, (N'getT5', N'sch1', N'T5', N'T2')
, (N'getT5', N'sch1', N'T5', N'T3')
, (N'getT5', N'sch1', N'T5', N'T5')
, (N'getT6', N'sch1', N'T6', N'T1')
, (N'getT6', N'sch1', N'T6', N'T4')
, (N'getT6', N'sch1', N'T6', N'T5');Using this dataset and the modified SELECT gives me what I am looking for. Awesome work, thanks again.
-
As another thought, if you want this strictly TSQL, is there any harm in running them all sequentially? Like run getT1 then getT2 then getT3 and so on? It ensures that getT1 finishes before getT3, but means that getT2 doesn't start until getT1 completes. Advantage - a lot easier to manage the flow control. Disadvantage - may be slower as some things can run simultaneously and this would prevent it. Then instead of checking dependencies with complex TSQL, you can just check the return code from the previous SP call. If it is 0 (or whatever you use for success), then start the next one. I think that is what you meant by running the procs in series in under 2 minutes, but is there any harm in just continuing that approach rather than trying to get things to run parallel when possible? I mean, it means you need to maintain that stored procedure any time a new step needs to be added, but I imagine that is not very frequent.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks, Brian. There is no parallelism requirement. The fact that T3 and T4 are at the same level implies only that they are independent of each other and can be executed in any order within that level.
-
I imagine you don't actually have them named like that with numbers, so trying to figure out which one to run first and second is a bit more involved. I also imagine that your script is more of a sanity check thing than anything else. It's easy to build the master run SP that runs A then B then C, but it's nice to have that sanity check to make sure you didn't accidentally run A then C then B.
Offhand, I don't know of a good way to manage that, sorry. SSIS would be my approach only because I can easily see the order and can confirm that A completes before I run B as per the requirements. SQL stored procedures/jobs make it a bit harder to do.
Mind you, you could do it with SQL jobs. Each job step starts a different stored procedure and waits for it to complete before moving onto the next step. That way you have nice visual flow control (step 1 completes then step 2 then 3 and so on) and if logic needs to change, you just move steps around. Is that a possibility instead of a "master" SP that calls things in order?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
As I mentioned earlier, I have stopped receiving e-mail notifications of replies, for some reason.
The actual procs are not named with numbers! They are named based on the tables they populate – getCurrency, getCountry etc.
Sanity check is correct. I could doctor the master proc to execute dynamic SQL, using the results of this code, but that's an unnecessary overhead.
-
An alternate way -
You can create what I'd call a "procedure execution tracker" - either as a declared string variable or stored in a database table - to monitor which stored procedures need to run and control their execution sequence.
declare @procedure_mask nvarchar(34) = 'nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn'
-- Position corresponds to level : 11223333344444555556666666667777
To simplify management and ensure your SSIS job executes all 34 stored procedures in a single run to complete your data warehouse load, implement this approach:
Execute stored procedures by level, with each procedure updating the tracker string upon successful completion. For instance, when the first SP finishes successfully, change the first character from 'n' to 'y', resulting in: 'ynnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn'
Before running the second SP, verify that the first character is 'y'. If confirmed, execute the second SP and update the string to: 'yynnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn'
Continue this pattern using either a loop within a stored procedure or individual SSIS data flows until the entire string becomes 'yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy', indicating all procedures have completed successfully.
This method provides built-in restart capability - if execution fails midway, you can resume from the failed procedure since unsuccessful procedures don't update their corresponding position to 'y'.
=======================================================================
- Phil Parkin wrote:
As I mentioned earlier, I have stopped receiving e-mail notifications of replies, for some reason.
The actual procs are not named with numbers! They are named based on the tables they populate – getCurrency, getCountry etc.
Sanity check is correct. I could doctor the master proc to execute dynamic SQL, using the results of this code, but that's an unnecessary overhead.
My opinion - I'd avoid dynamic SQL unless it is your only option. It can be hard to debug and it is potential for problems in the event someone messes up your sanity check table.
I think your best options are going to be manually checking for SP completion or migrate it to a different tool (SQL Agent job steps or SSIS). My opinion - the other methods mentioned will end up being a lot of overhead when you need to add/remove a step or change step order. The exception being dynamic SQL, but I hate trying to debug dynamic SQL.
Just my 2 cents mind you - maybe you have had more luck with dynamic SQL and the risk is small if only a handful of users can update the table used for generating the dynamic SQL or the recursive SQL that Steve Collins made. Recursive SQL in my experience works great until it hits an error and you get stuck in an infinite loop and it stops on you (which is good) OR it gets too deep then it starts failing thinking it's an infinite loop. But all it takes is one bad data point and you could get an infinite loop which messes up your data or starts causing the SQL to fail and you get to debug the recursive call to try to figure out why it failed. With small data sets it can be easier to debug, but it is also a pain in the butt.
In the end, I'd use what you are comfortable with as you have to support it. I don't like recursive CTE's or dynamic SQL unless it is my only option (similar to cursors) and even then, I try to find another solution before giving in and using those. In your scenario though, I think those are your only options apart from using other tools or manual process and hoping you are not missing anything or doing it out of order like how you are doing it now.
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system.
Viewing 11 posts - 1 through 11 (of 11 total)
You must be logged in to reply to this topic. Login to reply