Counting the number of unique days between ranges of dates
-
This feels like an easy problem to solve, but I have not yet been able to find a solution.
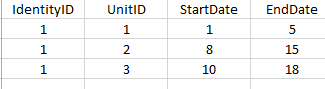
I have a table containing an IdentityID, UnitID, StartDate and EndDate. A person can be a member of more than 1 unit at a time. A person could also not be a member of any unit for a time (e.g. taking a break). I want to calculate each persons overall service (in days), not including any overlap or breaks.
Example (dates changed to integers to simplify the problem):

If I sum each row I get 22 days (inclusive). The answer I am looking for is 16 unique days.
Would appreciate your assistance.
Script for my example:
CREATE TABLE [dbo].[UnitMembership](
[IdentityID] [int] NULL,
[UnitID] [int] NULL,
[StartDate] [int] NULL,
[EndDate] [int] NULL
) ON [PRIMARY]
GO
INSERT INTO dbo.UnitMembership VALUES (1, 1, 1, 5)
INSERT INTO dbo.UnitMembership VALUES (1, 2, 8, 15)
INSERT INTO dbo.UnitMembership VALUES (1, 3, 10, 18)
SELECT IdentityID, SUM(EndDate-StartDate + 1) AS ServiceDays
FROM dbo.UnitMembership
GROUP BY IdentityID -
I am close i think but im not sure where my my error is.
I am taking the previous end date and compare it to the current start date. I take which ever one is later.
Guess the reason is the +1 i am not correctly including/excluding days.
Currently results in 14 instead of 16 but the idea is correct i think?
select *
,Total= case when Previous_EndDate > StartDate
then EndDate-Previous_EndDate
else EndDate-StartDate END
from (
select IdentityID
,StartDate
,EndDate
,Previous_EndDate = isnull(LAG(EndDate)
OVER(PARTITION BY IdentityID ORDER BY StartDate),0)
from dbo.UnitMembership
) kekI want to be the very best
https://www.sqlservercentral.com/articles/forum-etiquette-how-to-post-datacode-on-a-forum-to-get-the-best-help
Like no one ever was -
That's exactlly what I'm after. Thanks very much.
The difference is because our EndDates are inclusive. I.e. someone that was a member between 5 and 10 has been active for 6 days.
-
This will solve the data as you have provided it.
However, what happens when you have multiple overlapping units?
DECLARE @UnitMembership table (
IdentityID int NOT NULL
, UnitID int NOT NULL
, StartDate int NOT NULL
, EndDate int NOT NULL
);
INSERT INTO @UnitMembership ( IdentityID, UnitID, StartDate, EndDate )
VALUES ( 1, 1, 1, 5 )
, ( 1, 2, 8, 15 )
, ( 1, 3, 10, 18 );
WITH cteOverlaps AS (
SELECT um.IdentityID
, StartDate = CASE WHEN um.StartDate <= LAG(um.EndDate) OVER ( PARTITION BY um.IdentityID ORDER BY um.StartDate, um.EndDate )
THEN LAG(um.StartDate) OVER ( PARTITION BY um.IdentityID ORDER BY um.StartDate, um.EndDate )
ELSE um.StartDate
END
, um.EndDate
FROM @UnitMembership AS um
)
, cteGrouped AS (
SELECT ol.IdentityID, ol.StartDate, EndDate = MAX(ol.EndDate)
FROM cteOverlaps AS ol
GROUP BY ol.IdentityID, ol.StartDate
)
SELECT g.IdentityID, ServiceDays = SUM( g.EndDate -g.StartDate +1 )
FROM cteGrouped AS g
GROUP BY g.IdentityID; -
I would think this would be the most straightforward way, although it may not be the most efficient way. But it might work just fine for you if your data is not too large.
;WITH
cte_tally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cte_tally1000 AS (
SELECT 0 AS number UNION ALL
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS number
FROM cte_tally10 c1 CROSS JOIN cte_tally10 c2 CROSS JOIN cte_tally10 c3
)
SELECT
IdentityID,
COUNT(DISTINCT UM.StartDate + t.number) AS ServiceDays
FROM dbo.UnitMembership UM
INNER JOIN cte_tally1000 t ON t.number BETWEEN 0 AND EndDate - StartDate
GROUP BY IdentityID
--ORDER BY IdentityIDSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:
I would think this would be the most straightforward way, although it may not be the most efficient way. But it might work just fine for you if your data is not too large.
;WITH
cte_tally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cte_tally1000 AS (
SELECT 0 AS number UNION ALL
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS number
FROM cte_tally10 c1 CROSS JOIN cte_tally10 c2 CROSS JOIN cte_tally10 c3
)
SELECT
IdentityID,
COUNT(DISTINCT UM.StartDate + t.number) AS ServiceDays
FROM dbo.UnitMembership UM
INNER JOIN cte_tally1000 t ON t.number BETWEEN 0 AND EndDate - StartDate
GROUP BY IdentityID
--ORDER BY IdentityIDScott... you have to remember to use a TOP (or unconverted/SARGable WHERE) somewhere on the cteTally to prevent the generation of ALL the rows that cteTally can generate. I'm sure that you'll argue that it's "not that many" rows but you have no control over how that code will be used and it currently generates a full set of 1000 rows 3 times (3000 rows behind the scenes).
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - DesNorton wrote:
This will solve the data as you have provided it.
However, what happens when you have multiple overlapping units?
Man, you were really close and it was starting to look like you beat Itzik Ben-Gan for performance. Unfortunately, the following data set breaks it. It's a fully nested set with regressive end dates.
--Unfortunately, this is the group that breaks everything.
INSERT INTO dbo.UnitMembership VALUES (6, 1, 1, 10) --Behind the scenes, comes out as 1 to 10 (OK)
INSERT INTO dbo.UnitMembership VALUES (6, 2, 2, 9) --Behind the scenes, comes out as 2 to 8 (Bad)
INSERT INTO dbo.UnitMembership VALUES (6, 3, 3, 8) --Behind the scenes, comes out as 3 to 7 (Bad)
INSERT INTO dbo.UnitMembership VALUES (6, 4, 4, 7) --Behind the scenes, comes out as 4 to 5 (Bad)
INSERT INTO dbo.UnitMembership VALUES (6, 5, 5, 6) --Behind the scenes, comes out as 5 to 6 (OK)
INSERT INTO dbo.UnitMembership VALUES (6, 6, 5, 5) --Behind the scenes, comes out missing (Bad)
--And, the total is bad.--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Assuming "dates" could only be a number between 1 and 31...
DECLARE @UnitMembership TABLE
(
IdentityID int NULL,
UnitID int NULL,
StartDate INT NULL,
EndDate INT NULL
);
INSERT @UnitMembership
VALUES (1, 1, 1, 5),
(1, 2, 8, 15),
(1, 3, 10, 18);
SELECT COUNT(*)
FROM (
VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15), (16), (17), (18), (19), (20), (21), (22), (23), (24), (25), (26), (27), (28), (29), (30), (31)
) AS x(n)
WHERE EXISTS (SELECT * FROM @UnitMembership AS um WHERE x.n BETWEEN um.StartDate AND um.EndDate);N 56°04'39.16"
E 12°55'05.25" - Jeff Moden wrote:ScottPletcher wrote:
I would think this would be the most straightforward way, although it may not be the most efficient way. But it might work just fine for you if your data is not too large.
;WITH
cte_tally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cte_tally1000 AS (
SELECT 0 AS number UNION ALL
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS number
FROM cte_tally10 c1 CROSS JOIN cte_tally10 c2 CROSS JOIN cte_tally10 c3
)
SELECT
IdentityID,
COUNT(DISTINCT UM.StartDate + t.number) AS ServiceDays
FROM dbo.UnitMembership UM
INNER JOIN cte_tally1000 t ON t.number BETWEEN 0 AND EndDate - StartDate
GROUP BY IdentityID
--ORDER BY IdentityIDScott... you have to remember to use a TOP (or unconverted/SARGable WHERE) somewhere on the cteTally to prevent the generation of ALL the rows that cteTally can generate. I'm sure that you'll argue that it's "not that many" rows but you have no control over how that code will be used and it currently generates a full set of 1000 rows 3 times (3000 rows behind the scenes).
I have no objection to a TOP () clause, but the number of rows needed is driven by the data in the other table, with data row potentially needing a different number of tally rows. This is very likely a case where a physical tally table would be better, to avoid generating the rows.
I was first trying to accurately solve the problem for any data input. I could see lots of potential gotchas to trying to calc this some other way. Once a query works, then tune after that if necessary ... or even try to come up with a completely different approach if required.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
As Jeff Moden as pointed out, for performance reasons, it's likely to best to create a physical tally table (if you don't already have one) to use for this query:
SELECT
IdentityID,
COUNT(DISTINCT UM.StartDate + t.number) AS ServiceDays
FROM dbo.UnitMembership UM
INNER JOIN dbo.tally t ON t.number BETWEEN 0 AND EndDate - StartDate
GROUP BY IdentityID
--ORDER BY IdentityIDSQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- ScottPletcher wrote:Jeff Moden wrote:ScottPletcher wrote:
I would think this would be the most straightforward way, although it may not be the most efficient way. But it might work just fine for you if your data is not too large.
;WITH
cte_tally10 AS (
SELECT * FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) AS numbers(number)
),
cte_tally1000 AS (
SELECT 0 AS number UNION ALL
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS number
FROM cte_tally10 c1 CROSS JOIN cte_tally10 c2 CROSS JOIN cte_tally10 c3
)
SELECT
IdentityID,
COUNT(DISTINCT UM.StartDate + t.number) AS ServiceDays
FROM dbo.UnitMembership UM
INNER JOIN cte_tally1000 t ON t.number BETWEEN 0 AND EndDate - StartDate
GROUP BY IdentityID
--ORDER BY IdentityIDScott... you have to remember to use a TOP (or unconverted/SARGable WHERE) somewhere on the cteTally to prevent the generation of ALL the rows that cteTally can generate. I'm sure that you'll argue that it's "not that many" rows but you have no control over how that code will be used and it currently generates a full set of 1000 rows 3 times (3000 rows behind the scenes).
I have no objection to a TOP () clause, but the number of rows needed is driven by the data in the other table, with data row potentially needing a different number of tally rows. This is very likely a case where a physical tally table would be better, to avoid generating the rows.
I was first trying to accurately solve the problem for any data input. I could see lots of potential gotchas to trying to calc this some other way. Once a query works, then tune after that if necessary ... or even try to come up with a completely different approach if required.
Looking at the code, there's something else going on. I first thought it might be non-sargable but, relooking at that, it is. SARGable but it doesn't limit the values return from the Tally cte and so generates way too many rows internally. I'm still looking to see why it does the "overrun" like it is.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
Gosh... I think I've gone brain dead a bit. I've tried a couple of things and can't just now remember how to do this with either an inline Tally cte or a physical Tally table without the number generation overruns I'm seeing in Scott's good code. I've gotten way too used to using an fnTally function to do it, like in the following code, which doesn't suffer from that same overrun.
First, the table test harness I'm using for a more complete test...
-- DROP TABLE IF EXISTS dbo.UnitMembership
--===== Create the test table
CREATE TABLE dbo.UnitMembership
(
IdentityID INT NOT NULL
,UnitID INT NOT NULL
,StartDate INT NOT NULL
,EndDate INT NOT NULL
)
;
--===== Populate the test table
INSERT INTO dbo.UnitMembership
(IdentityID, UnitID, StartDate, EndDate)
VALUES (1, 1, 1, 5)
,(1, 2, 8, 15)
,(1, 3, 10, 18)
,(2, 1, 10, 18)
,(2, 2, 1, 5)
,(2, 3, 8, 15)
,(3, 1, 17, 18)
,(3, 2, 1, 5)
,(3, 3, 8, 15)
,(4, 1, 17, 18)
,(5, 1, 17, 18)
,(5, 2, 17, 18)
,(5, 3, 17, 18)
--Scott's code handles this just fine and using fnTally
--makes his code super simple and prevent number overruns.
--The other code failed on this.
,(6, 1, 2, 9)
,(6, 2, 3, 8)
,(6, 3, 4, 7)
,(6, 4, 5, 6)
,(6, 5, 5, 5)
,(6, 6, 1, 10)
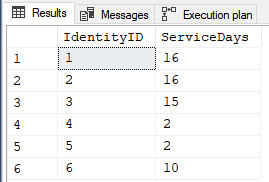
;And here's what Scott's code looks like if you use the fnTally function (available at the similarly named link in my signature line below)...
SELECT um.IdentityID
,ServiceDays = COUNT(DISTINCT um.StartDate + t.N)
FROM dbo.UnitMembership um
CROSS APPLY dbo.fnTally(0,um.EndDate - um.StartDate)t
GROUP BY IdentityID
ORDER BY IdentityID
;The really cool part is that Scott's idea for doing this does actually work even with the serious nested #6 group I posted above. Here's the proof of that (nicely done, Scott)...
Here's the output from all of that...
Of course, Itzik Ben-Gan also has some code to do this without any number sequence generation at the following URL..
https://www.itprotoday.com/sql-server/new-solution-packing-intervals-problem
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - SwePeso wrote:
Assuming "dates" could only be a number between 1 and 31...
DECLARE @UnitMembership TABLE
(
IdentityID int NULL,
UnitID int NULL,
StartDate INT NULL,
EndDate INT NULL
);
INSERT @UnitMembership
VALUES (1, 1, 1, 5),
(1, 2, 8, 15),
(1, 3, 10, 18);
SELECT COUNT(*)
FROM (
VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15), (16), (17), (18), (19), (20), (21), (22), (23), (24), (25), (26), (27), (28), (29), (30), (31)
) AS x(n)
WHERE EXISTS (SELECT * FROM @UnitMembership AS um WHERE x.n BETWEEN um.StartDate AND um.EndDate);Unfortunately, the has the same monster internal row generation problem as Scott's method. It also doesn't handle multiple distinct IdentityID's.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:SwePeso wrote:
Assuming "dates" could only be a number between 1 and 31...
DECLARE @UnitMembership TABLE
(
IdentityID int NULL,
UnitID int NULL,
StartDate INT NULL,
EndDate INT NULL
);
INSERT @UnitMembership
VALUES (1, 1, 1, 5),
(1, 2, 8, 15),
(1, 3, 10, 18);
SELECT COUNT(*)
FROM (
VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15), (16), (17), (18), (19), (20), (21), (22), (23), (24), (25), (26), (27), (28), (29), (30), (31)
) AS x(n)
WHERE EXISTS (SELECT * FROM @UnitMembership AS um WHERE x.n BETWEEN um.StartDate AND um.EndDate);Unfortunately, the has the same monster internal row generation problem as Scott's method. It also doesn't handle multiple distinct IdentityID's.
On top of which, I strongly doubt that the dates are limited to 1 to 31. To me, seems much more like this was some type of sequential date counter/id rather than just being the day of month.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
Thanks all for your help with this one. Reading through all your suggestions it looks like using a tally is what'll work for us. The dataset is only about 2,800 rows so performance isn't a huge problem.
Also came across this solution which is very similar and seems to work on the test data:
https://bertwagner.com/posts/gaps-and-islands/
Viewing 15 posts - 1 through 15 (of 20 total)
You must be logged in to reply to this topic. Login to reply