Conditional Update of Column
-
I can't remember ever trying this before, but I have need to do it now. I need to update a specific column in a table based on data in another table. The column to be updated varies. Some code will explain better:
DROP TABLE IF EXISTS #sample;
CREATE TABLE #sample
(
PK CHAR(3) NOT NULL PRIMARY KEY CLUSTERED
,Col1 INT NOT NULL
DEFAULT (0)
,Col2 INT NOT NULL
DEFAULT (0)
);
INSERT #sample
(
PK
,Col1
,Col2
)
VALUES
('AAA', 0, 0)
,('BBB', 0, 0)
,('CCC', 0, 0);
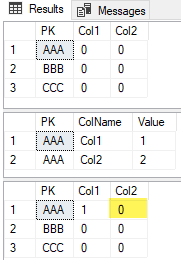
SELECT *
FROM #sample s;
DROP TABLE IF EXISTS #sample2;
CREATE TABLE #sample2
(
PK CHAR(3) NOT NULL
,ColName VARCHAR(10) NOT NULL
,Value INT NOT NULL
,
PRIMARY KEY CLUSTERED (
PK
,ColName
)
);
INSERT #sample2
(
PK
,ColName
,Value
)
VALUES
('AAA', 'Col1', 1)
,('AAA', 'Col2', 2);
SELECT *
FROM #sample2 s;
WITH src
AS (SELECT s.PK
,s.ColName
,s.Value
FROM #sample2 s)
UPDATE trg
SET trg.Col1 = IIF(src.ColName = 'Col1', src.Value, trg.Col1)
,trg.Col2 = IIF(src.ColName = 'Col2', src.Value, trg.Col2)
FROM #sample trg
JOIN src
ON src.PK = trg.PK;
SELECT *
FROM #sample s;Which produces the following results:

I want the highlighted cell to be '2' after running the update.
I assume that the problem is due to the fact that the same row is being updated more than once in the same batch.
What's the best way round this?
-
Other than using dynamic SQL I think you will have to do it like this:
In 2 statements
UPDATE s
SET s.Col1 = s2.Value
FROM #sample s
INNER JOIN #sample2 s2
ON s2.ColName = 'Col1'
AND s2.PK = s.PK;
UPDATE s
SET s.Col2 = s2.Value
FROM #sample s
INNER JOIN #sample2 s2
ON s2.ColName = 'Col2'
AND s2.PK = s.PK;or in 1 statement:
UPDATE s
SET s.Col1 = CASE WHEN s2.ColName = 'Col1' THEN s2.Value ELSE s.Col1 END,
s.Col2 = CASE WHEN s2.ColName = 'Col2' THEN s2.Value ELSE s.Col2 END
FROM #sample s
INNER JOIN #sample2 s2
ON s2.ColName IN ('Col1','Col2')
AND s2.PK = s.PK; -
Thanks for your input, Jonathan.
The single query method did not work, even after changing s2.Value to s2.ColName in the necessary spots.
I have gone ahead with the multiple-batch version (there are six batches in my real-world version, but that's still OK, as the data volume is low and I've first put the results of my source query into a temp table to avoid multiple executions of the same complex query).
- Phil Parkin wrote:
The single query method did not work, even after changing s2.Value to s2.ColName in the necessary spots.
Yes, I see why now, the join on the update query returns more than 1 row from #sample2 for 1 row in #sample.
-
Or this instead?:
;WITH src
AS (SELECT s.PK
,MAX(CASE WHEN s.ColName = 'Col1' THEN s.Value END) AS Col1Value
,MAX(CASE WHEN s.ColName = 'Col2' THEN s.Value END) AS Col2Value
/*,...*/
FROM #sample2 s
GROUP BY s.PK)
UPDATE trg
SET trg.Col1 = src.Col1Value
,trg.Col2 = src.Col2Value
FROM #sample trg
JOIN src
ON src.PK = trg.PK;SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
That is it, thanks Scott!
-
Multiple outer joins:
Select s1.PK
, Col1 = coalesce(c1.[Value], s1.Col1)
, Col2 = coalesce(c2.[Value], s1.Col2)
From #sample s1
Left Join #sample2 c1 On c1.PK = s1.PK
And c1.ColName = 'Col1'
Left Join #sample2 c2 On c2.PK = s1.PK
And c2.ColName = 'Col2';The assumption is that you know all possible columns in the #sample table. If that is dynamically generated - then any solution would also need to be dynamically generated.
To filter down to just the rows in #sample to be updated - you would need to add a where clause. Not sure how efficient it would be - but it could be done with: Where coalesce(s1.Col1, s2.Col1) Is Not Null
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
CREATE TABLE Samples
(sample_id CHAR(3) NOT NULL PRIMARY KEY.
DEFAULT 0,
col_1 INTEGER NOT NULL
DEFAULT 0,
col_2 INTEGER NOT NULL
DEFAULT (0));
INSERT INTO Samples (sample_id, col_1, col_2)
col_value ('AAA', 0, 0), ('BBB', 0, 0), ('CCC', 0, 0);
Socko hello hello hello
CREATE TABLE Sample2
(sample_id CHAR(3) NOT NULL,
col_name VARCHAR(10) NOT NULL,
col_col_value INTEGER NOT NULL,
PRIMARY KEY (sample_id, col_name)
);
INSERT INTO Sample2 (sample_id, col_name, col_value)
VALUES ('AAA', 'col_1', 1), ('AAA', 'col_2', 2);
>> I assume that the problem is due to the fact that the same row is being updated more than once in the same batch.<<
Actually the problems a little more subtle than that. The fiction in ANSI/ISO standard SQL is that when you create an alias (please start explicitly using the AS operator, so your code will be more readable.) It acts as if the result creates a new working table that exist within this scope for the duration of the statement. You get around to reading the SQL standards you learn to hate the word "effectively" which is all over the place. This means that an update statement that has the old Sybase extensions with UPDATE..FROM.. Has a lot of funny scoping rules in it . Add a CTE, and it gets really confusing. This is why I tell people either use a merge statement, or as simple an update as they can write.
As an aside on your code (which is generally good), do you know why we put commas at the start of rows back in the 1960s? We were using punch cards, and this convention made it easy to rearrange and reuse the cards in a deck. Starting sometime in the 1970s, however, we got pretty printers and could reformat our code changed by simply pushing a button. The leading, actually makes the code measurably harder to debug and read because your eyes taught to follow punctuation. If you want some really boring studies on and get them from the University of Maryland.
The IFF function is not part of SQL; we have a CASE expression. You're not using spreadsheets anymore, but make your code look like a mixture of Chinese and English. Try something like this:
UPDATE Samples
SET col_1 = CASE WHEN Sample2.col_name = 'col_1'
THEN Sample2.col_value ELSE col_1 END,
col_2 = CASE WHEN Sample2.col_name = 'col_2'
THEN Sample2.col_value ELSE col_2;
better yet, this is why we have the merge statement. Microsoft is not in a good job of implementing it yet, but it will do a lot of validations, look for multiple updates like you're worried about, etc.
Please post DDL and follow ANSI/ISO standards when asking for help.
Viewing 8 posts - 1 through 8 (of 8 total)
You must be logged in to reply to this topic. Login to reply