Cleaning the Data frame
-
Comments posted to this topic are about the item Cleaning the Data frame
-
Nice reminder, thanks Steve
____________________________________________
Space, the final frontier? not any more...
All limits henceforth are self-imposed.
“libera tute vulgaris ex” -
I found this in the syntax:
"header is set to TRUE if and only if the first row contains one fewer field than the number of columns."
So, because of the same number of columns and titles the right answer is:
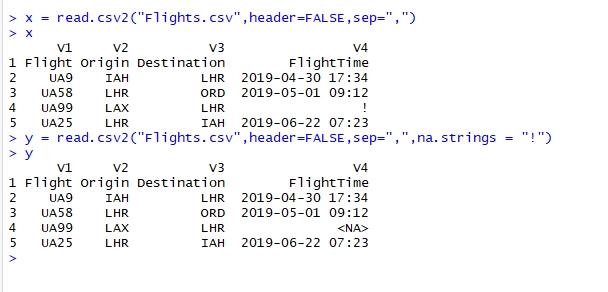
x = read.csv2("Flights.csv",header=FALSE,sep=",",na.strings = "!")
-
The "one fewer field" guidance is weird to me. I've been using read.csv2 on files with the same number of header fields and columns with header=TRUE to read many files successfully. I wonder if their is some implied row number field in a csv or if the guidance isn't clear.
-
I should try, but I think that if you specify "header=true or false" the first row contains column names (true= less names than columns, false=same number for names and columns.
-
Not sure that works.

-
The syntax description in the reference states that header is a logical value indicating whether the file contains the names of the variables as its first line. If missing, the value is determined from the file format: header is set to TRUE if and only if the first row contains one fewer field than the number of columns.
If header = FALSE is explicitly specified, the first line is always treated as data values. See both examples given above by Steve, the resulting Data Frame has default column names Values V1, V2, V3, V4 and the first row are data from the original column names of Flights.csv.
Try a simple text import code to easily check the function of the header parameter, for example:
1.
read.csv2(sep = ",", text = "
a,b,c,
1,2,3,4,5
")
Parameter header is missing, but in the first row there are 4 elements a, b, c, for 5 columns.
Default header = TRUE applies.
Result is a data frame with an added header and one row of data:
a b c X
1 2 3 4 5
2. But you cannot specify:
read.csv2(sep = ",", text = "
a,b,c
1,2,3,4,5
")
Result:
Error: more columns than column names
3. The header = FALSE is explicitly specified:
read.csv2(header = FALSE, sep = ",", text = "
a,b
1,2,3,4,5
")
Result is a data frame with the default column names.
The first row of data is completed with NA.
V1 V2 V3 V4 V5
1 a b NA NA NA
2 1 2 3 4 5
4. The header = TRUE is explicitly specified with more columns names than columns...:
read.csv2(header = TRUE, sep = ",", text = "
a,b,c,d,e,f,g,
1,2,3,4,5
")
Result is a data frame the header is completed with X. The first row of data is completed with NA.
a b c d e f g X
1 1 2 3 4 5 NA NA NA
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply