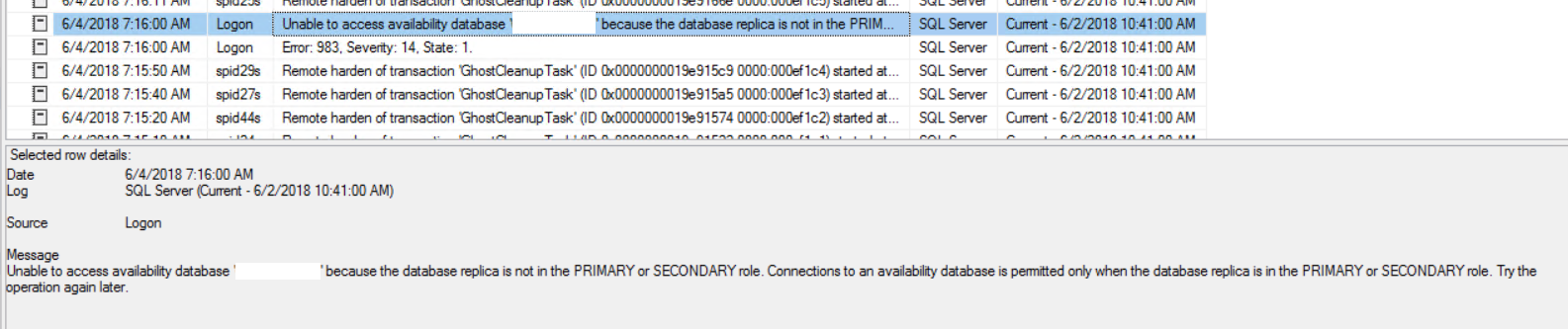
After also checking the availability group dashboard which also confirmed the error state I went to the Failover cluster manager and noticed the following errors:
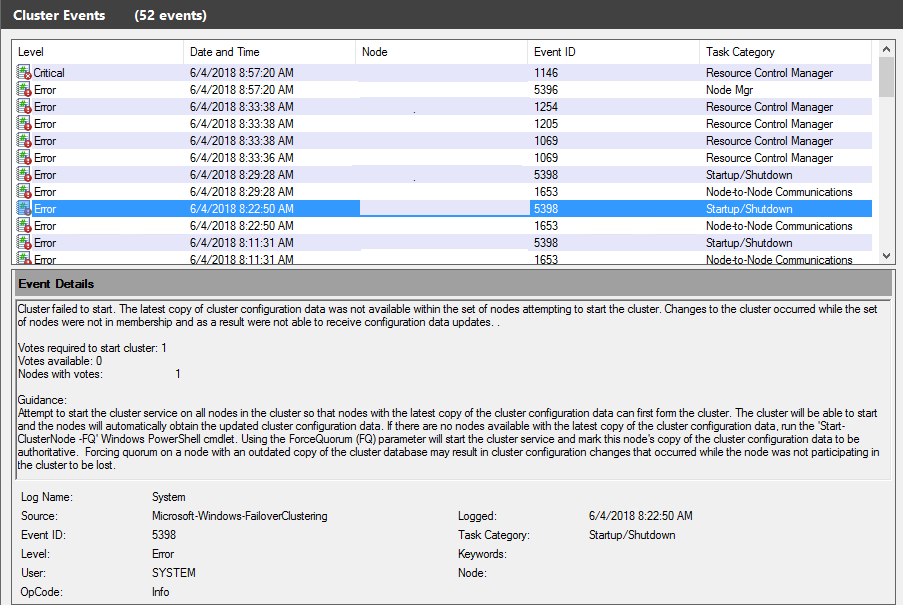
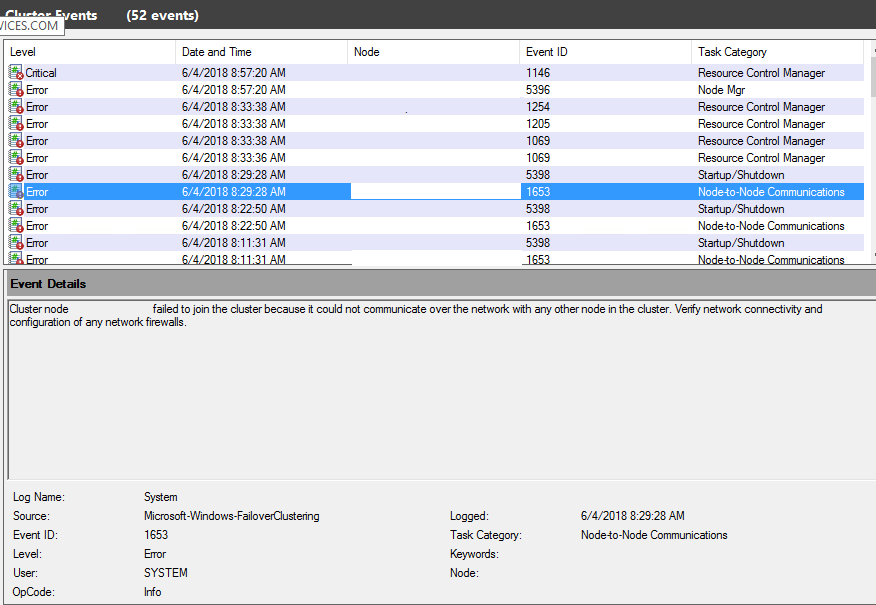
Also noticed that the node that was under the issues was showing that the Failover cluster state was stopped. Obviously if the server was not able to be reached through the network the cluster wouldn't be able to show it as healthy or running. But because lf that and the fact that there was no third witness the entire cluster state was failed and due to that the availably group and Listener were down as well, so what was needed? getting the cluster up and running even if one node is missing, but how would you do that? Well you need to start the cluster without the quorum validation, with that you will have the WSFC running and in return the availability group and listener will be up as well.
But wait, I'm a DBA that means that my experience with managing clusters at the windows level is minimal. If that is the case you have 2 options call IT to get the assistance you need or do it yourself, In my case was the second, if you choose the same, in the following URL are the required steps
https://docs.microsoft.com/en-us/sql/sql-server/failover-clusters/windows/force-a-wsfc-cluster-to-start-without-a-quorum?view=sql-server-2017
In my particular case the steps with the windows interface didn't work but the PowerShell ones did.
This got my cluster running, however my Availability group still had as primary the failed server, so I still had to failover the group to the one working, I achieved that by forcing the failover with this command:
ALTER AVAILABILITY GROUP <DAG NAME> FORCE_FAILOVER_ALLOW_DATA_LOSS
I know, it is scary when you see "Allow data loss" however, I had Synchronous commit set, so worst case scenario, I would be loosing the transactions that weren't committed at the time the primary server went offline so in the end that wasn't even written in the Primary database and it was safe to roll them back if needed.
That brought my databases online and the applications could resume working.
After fixing all the network issues and noticing that you are able to connect to your secondary replica execute this command to restart the synchronization, make sure that you update it for each of your databases.
ALTER DATABASE database_name SET HADR RESUME
And bam, you are all set, your cluster and Database availability group is back to the state it was before the failure.
As a lesson learned, add a witness to a file server, so that you don't loose your Quorum and prevent this issue to happen.
Thanks for reading!
![]()