
(2019-May-24) Data Flow as a data transformation engine has been introduced to the Microsoft Azure Data Factory (ADF) last year as a private feature preview. This privacy restriction has been lifted during the last Microsoft Build conference and Data Flow feature has become a public preview component of the ADF.
There are many different use-case scenarios that can be covered by Data Flows, considering that Data Flows in SQL Integration Service (SSIS) projects are still playing a big role to fulfill Extracting-Loading-Transforming (ETL) patterns for your data.
In this blog post, I will share my experience of populating a Data Vault repository by using Data Flows in Azure Data Factory.
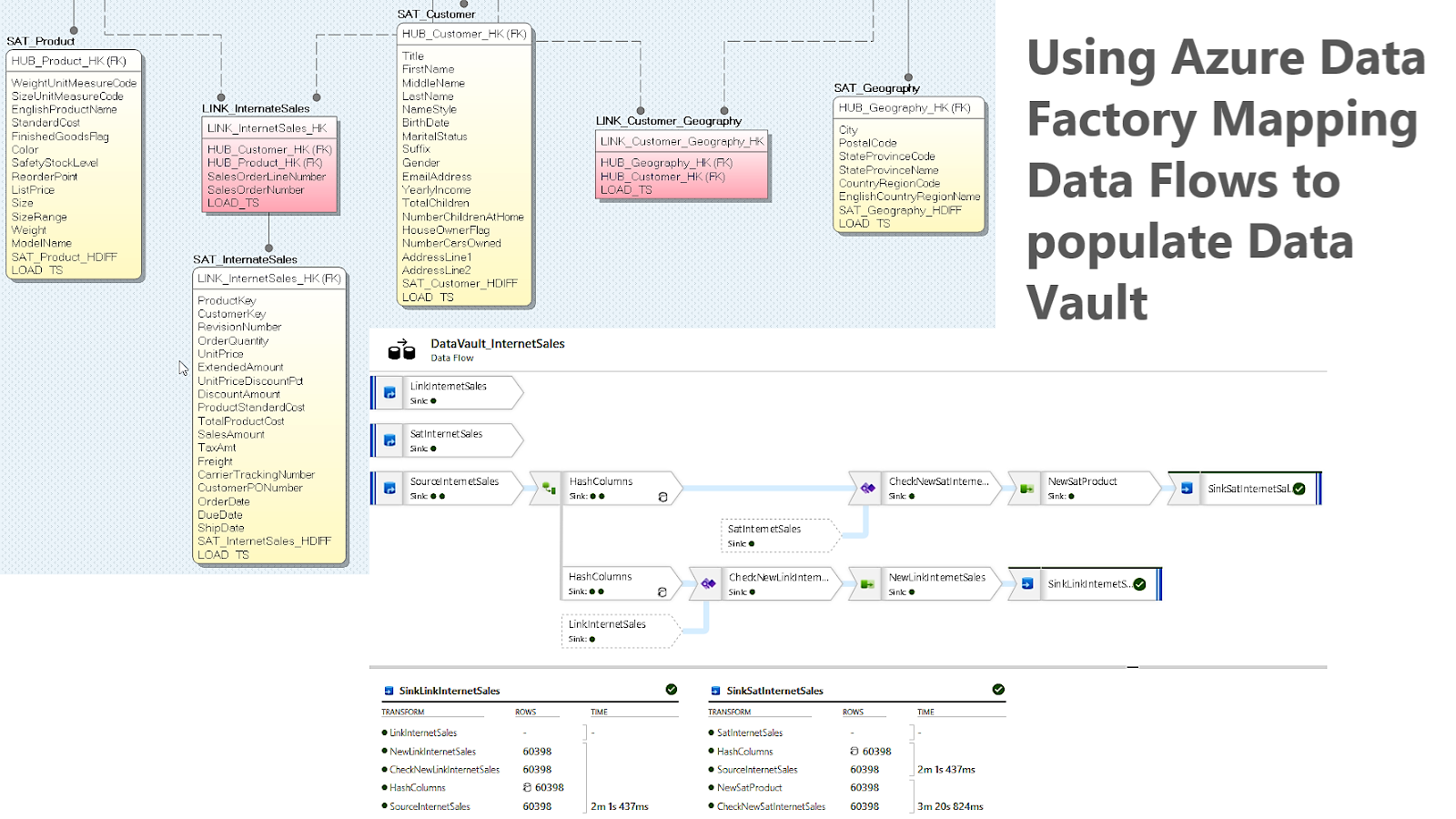
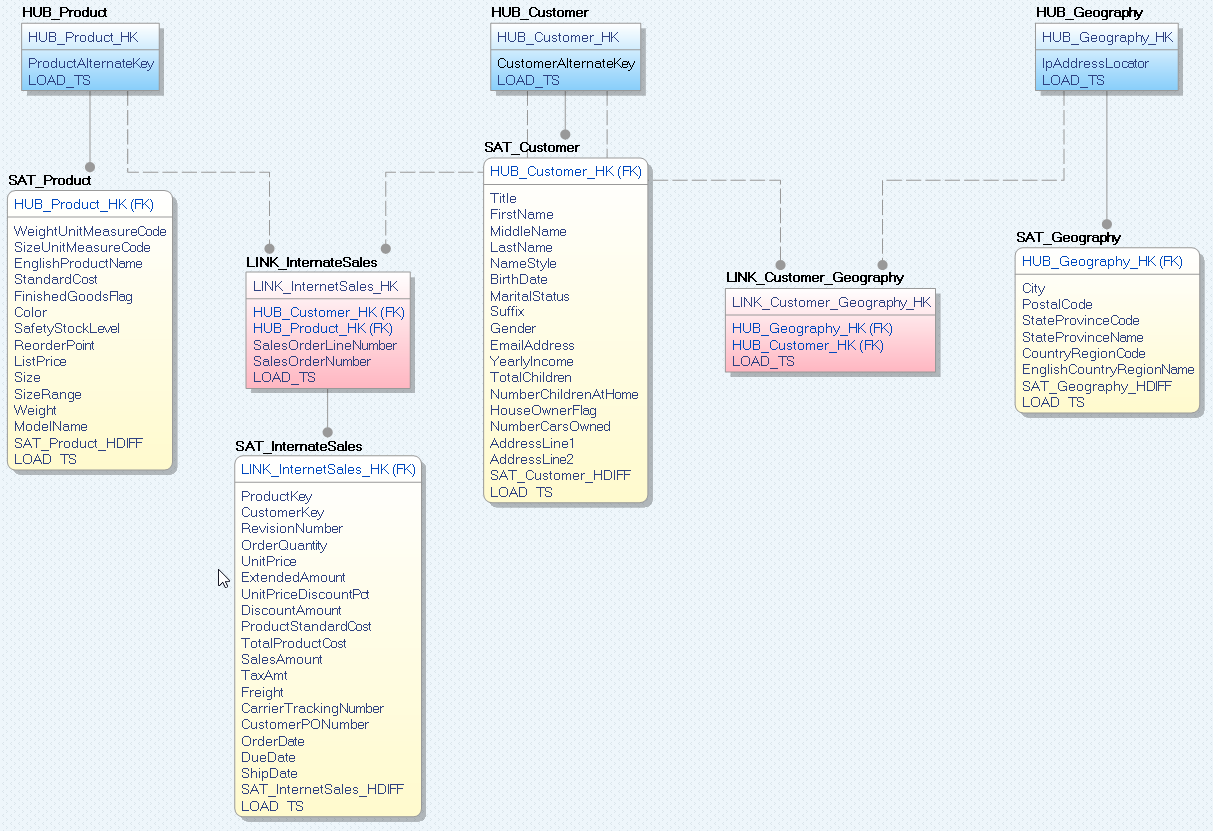
First, I need to create my Data Vault model.
Data Model
For this exercise I've taken a date warehouse sample of AdventureWorksDW2017 SQL Server database, twhere I limited a set of entities to a small set of dimension tables (DimProduct, DimCustomer, DimGeography) and one fact table (FactInternateSales).
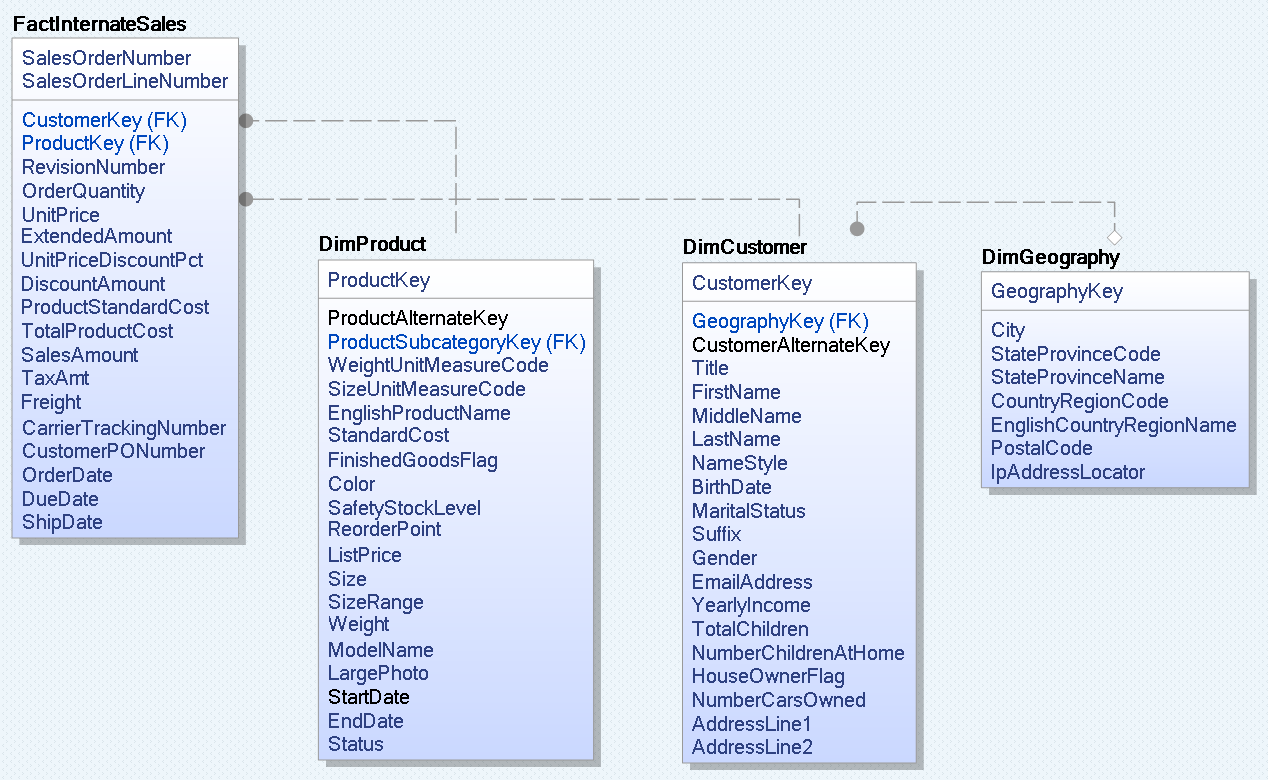
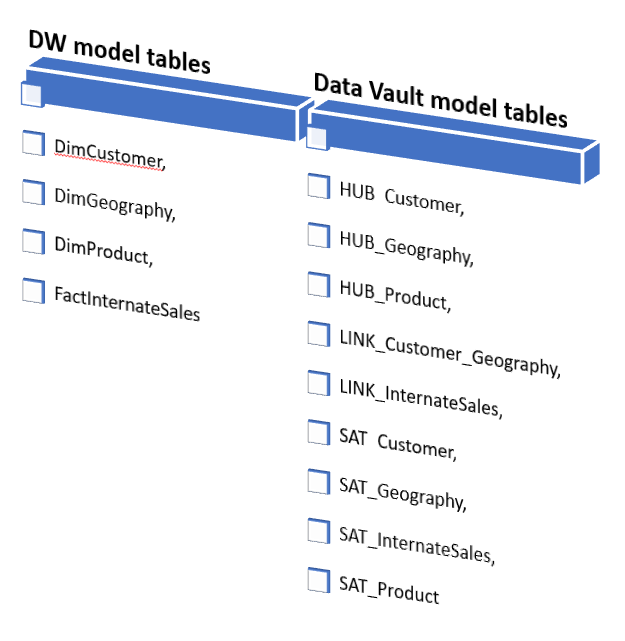
From the existing list of tables in my DW instance I came up with the list of entities for my new alternative Data Vault model:
Sourcing Data
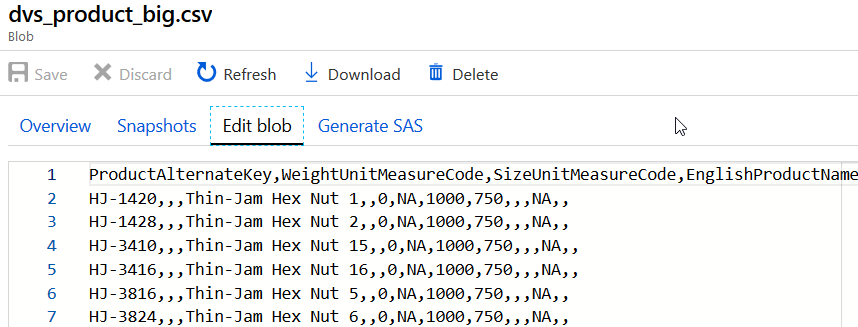
To test my Data Vault loading process in ADF Data Flows I extracted data from the existing Adventure Works SQL Server database instance and excluded DW related data columns. This is an example of my Product flat file in my Azure blob storage with the following list of columns:
ProductAlternateKey
,WeightUnitMeasureCode
,SizeUnitMeasureCode
,EnglishProductName
,StandardCost
,FinishedGoodsFlag
,Color
,SafetyStockLevel
,ReorderPoint
,ListPrice
,Size
,SizeRange
,Weight
,ModelName
Also, I created a set of views to show the latest version of the satellite table that I want to collide with sourcing data files. Examples of those views for SAT_InternetSales and SAT_Product tables:
CREATE VIEW [dbo].[vw_latest_sat_internetsales]
AS
SELECT [link_internetsales_hk],
[sat_internetsales_hdiff]
FROM (SELECT [link_internetsales_hk],
[sat_internetsales_hdiff],
Row_number()
OVER(
partition BY SAT.link_internetsales_hk
ORDER BY SAT.load_ts DESC) AS row_id
FROM [dbo].[sat_internetsales] SAT) data
WHERE row_id = 1;
CREATE VIEW [dbo].[vw_latest_sat_product]
AS
SELECT [hub_product_hk],
[sat_product_hdiff]
FROM (SELECT [hub_product_hk],
[sat_product_hdiff],
[load_ts],
Max(load_ts)
OVER (
partition BY sat.hub_product_hk) AS latest_load_ts
FROM [dbo].[sat_product] sat) data
WHERE load_ts = latest_load_ts;Data Integration
If you're new to building data integration projects in the Microsoft Data Platform (SSIS, Azure Data Factory, others), I would suggest this approach:
1) Learn more about different components of the existing data integration tools and their capabilities.
2) Go back to your real use case scenario and describe the business logic of your data integration/data transformation steps.
3) Then merge those business rules with corresponding technical components in order to come up with a technical architecture of your business solution.
Mapping Data Flows
Now, after preparing all of this, I'm ready to create Mapping Data Flows in Azure Data Factory.
Example of the Product data flow:

1) Source (Source Product): connection to the Product CSV data file in my blob storage account
2) Derived Columns (Hash Columns): to calculate hash columns and load timestamps.
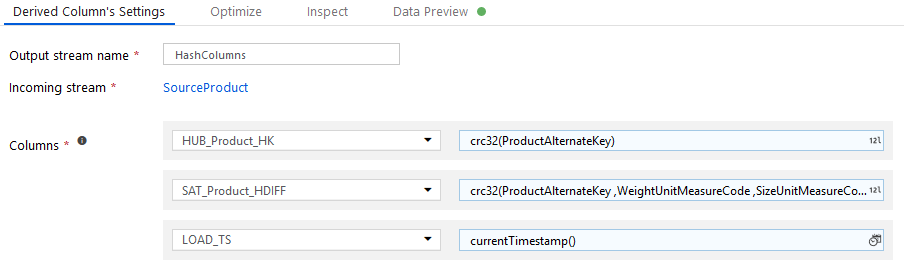
HUB_Product_HK = crc32(ProductAlternateKey)
SAT_Product_HDIFF = crc32(ProductAlternateKey, WeightUnitMeasureCode, SizeUnitMeasureCode, EnglishProductName, StandardCost, FinishedGoodsFlag, Color, SafetyStockLevel, ReorderPoint, ListPrice, Size, SizeRange, Weight, ModelName)
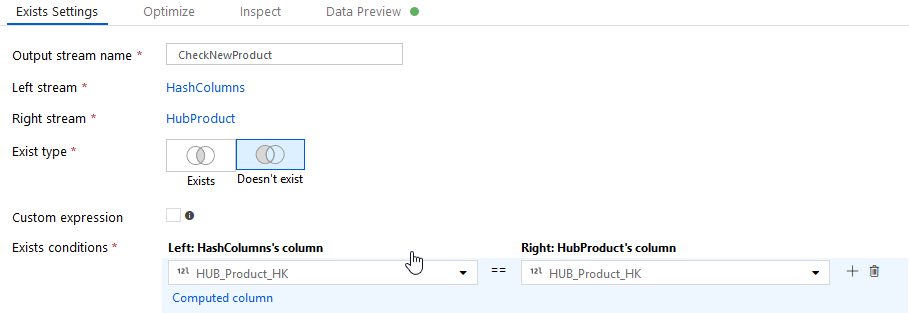
3) Exists transformation (CheckNewProduct): Filtering rows that are not matching the following criteria: move forward records from the Sourcing data files with records that are new to the HUB_Product table:
4) Select transformation: to select only 3 columns (ProductAlternateKey, HUB_Product_HK, LOAD_TS)
5) Sink: These 3 columns are then sinked my target HUB_Product data vault table.
Since Product data file is used both to load data to HUB_Product and SAT_Product (Step 1 & 2), a separate data stream is created to populate data the SAT_Product as well.
3) Exists transformation (CheckNewSatProduct): Filtering rows that are not matching the following criteria: move forward records from the Sourcing data files that are new to the SAT_Product table:

4) Select transformation: to select columns for my next Sink Step (HUB_Product_HK, WeightUnitMeasureCode, SizeUnitMeasureCode, EnglishProductName, StandardCost, FinishedGoodsFlag, Color, SafetyStockLevel, ReorderPoint, ListPrice, Size, SizeRange, Weight, ModelName, SAT_Product_HDIFF, LOAD_TS)
5) Sink: These 18 columns are then sinked my target SAT_Product data vault table.
Similarly, I created another Data Flow task to load Fact Internet Sales data (dvs_internetsales_big.csv) and populate LINK_InternetSales & SAT_InternetSales tables:

where LINK_InternetSales_HK & SAT_InternetSales_HDIFF hash keys were used to identify new data for the data vault tables.
This case is solved, and now I can use Azure Data Factory Mapping Data Flows to load data into a data vault repository.
Please let me know if you have further questions or you can get a closer look into the code of those developed pipelines and mapping data flows in my GitHub repository:
https://github.com/NrgFly/Azure-DataFactory/tree/master/Samples
Happy Data Adventures!