
(2020-Mar-26) There are two ways to create data flows in Azure Data Factory (ADF): regular data flows also known as "Mapping Data Flows" and Power Query based data flows also known as "Wrangling Data Flows", the latter data flow is still in preview, so do expect more adjustments and corrections to its current behavior.
Last week I blogged about using Mapping Data Flows to flatten sourcing JSON file into a flat CSV dataset:
Part 1: Transforming JSON to CSV with the help of Flatten task in Azure Data Factory
Today I would like to explore the capabilities of the Wrangling Data Flows in ADF to flatten the very same sourcing JSON dataset.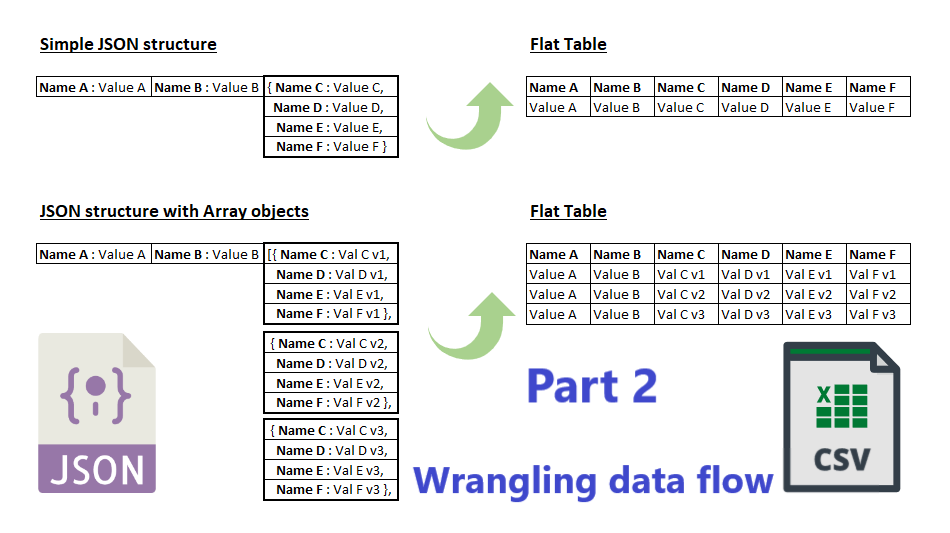
At the time of writing this blog post, ADF Wrangling Data Flows only supports two types of file formats: CSV and Parquet. JSON file type is not supported. I could have just stopped here and wait for Microsoft to enable the work with "JavaScript Object Notation" data structure.
Origin: https://opensource.adobe.com/Spry/samples/data_region/JSONDataSetSample.html
[
{
"id": "0001",
"type": "donut",
"name": "Cake",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" },
{ "id": "1003", "type": "Blueberry" },
{ "id": "1004", "type": "Devil's Food" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5007", "type": "Powdered Sugar" },
{ "id": "5006", "type": "Chocolate with Sprinkles" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
},
{
"id": "0002",
"type": "donut",
"name": "Raised",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5005", "type": "Sugar" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
},
{
"id": "0003",
"type": "donut",
"name": "Old Fashioned",
"ppu": 0.55,
"batters":
{
"batter":
[
{ "id": "1001", "type": "Regular" },
{ "id": "1002", "type": "Chocolate" }
]
},
"topping":
[
{ "id": "5001", "type": "None" },
{ "id": "5002", "type": "Glazed" },
{ "id": "5003", "type": "Chocolate" },
{ "id": "5004", "type": "Maple" }
]
}
]
or try and turn this JSON dataset into CSV file with a "wrapped" JSON structure within. I will try to fool Wrangling Data Flows and hope it will accept this trick 🙂
(1) Adjusted JSON file, with each JSON array element being presented as an individual CSV file record:
(2) Connection to this CSV file in Wrangling Data Flows. After configuring source settings to my ds_dataflow_sample dataset, all 3 lines are shown correctly: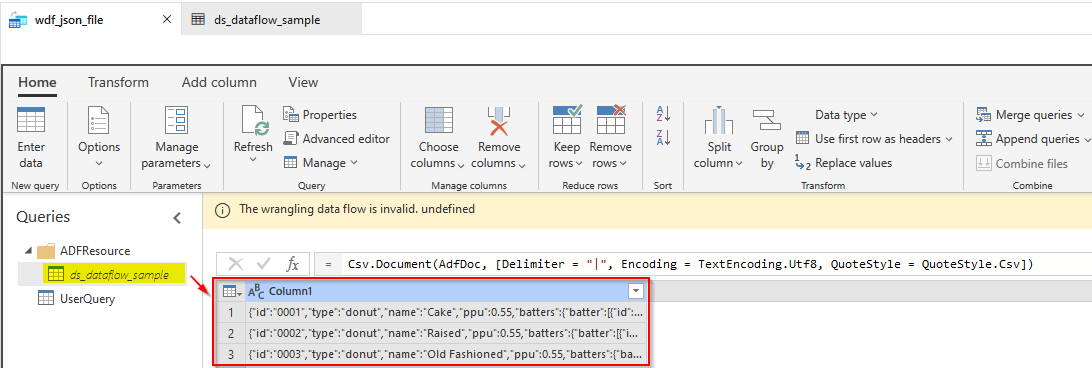
(3) Further transformations proved that we can really work and flatten JSON data files using Wrangling Data Flows. If you remember from my previous blog post where we had two Flatten transformation step: (2) to Flatten the Topping and the (3) to Flatten the Batter:
With the help of Power Query M language in Wrangling Data Flows we can still perform the same two JSON "Flatten" transformations: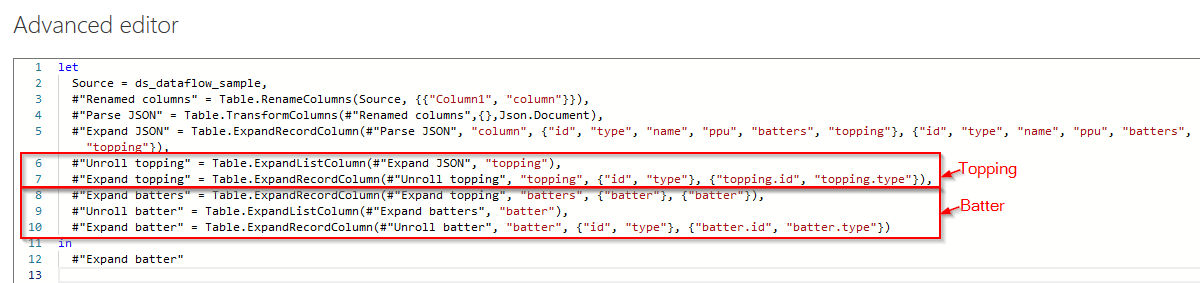
My final result in ADF Wrangling Data Flow still returns the expected 41 records correctly: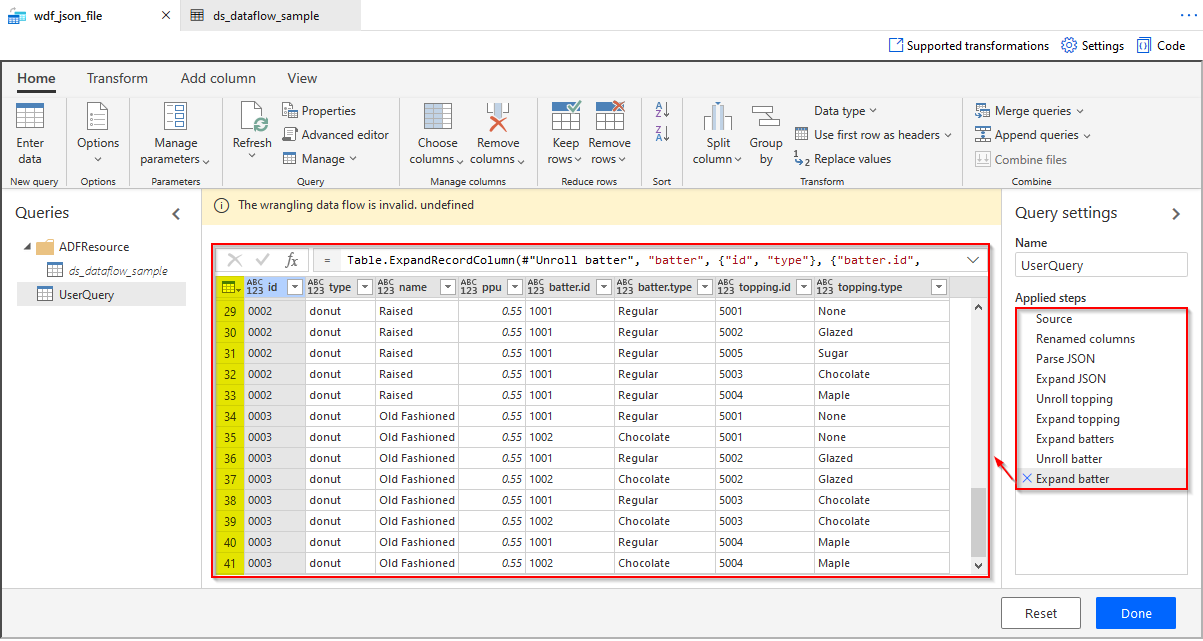
(4) Saving transformed result into a flat CSV file, that hasn't worked well for me yet. The error message at top, "The wrangling data flow is invalid. undefined" even with the correct M-query data transformation, blocked me from saving (or sinking) the output result into a CSV file.
My only hope that in future there will be legit support for JSON data files in Azure Data Factory Wrangling Data Flows and error messages in query editor would be more verbose and helpful.
I'm keeping my hopes up high 🙂