
(2021-Jan-12) Small data that is hard to be noticed but in a long run makes the greatest impact, little things that are not well apricated but eventually become those final pieces of a puzzle that fit perfectly and complete a problem solution.

Recently Microsoft team conducted a brief year-end survey about a “one thing” that Azure Data Factory (ADF) “made your day in 2020” - https://twitter.com/weehyong/status/1343709921104183296. There were different responses from the global parameters support to the limit increase of ADF instances per subscription.
I personally like the little things that are not easily detected on a surface, but with a deeper immersion into a data pipeline development, your level of gratefulness increases even more.
- Updates
Imagine waking up one morning to find out that that "all" your IT troubles are no more than a morning mist, that may have covered your perception but will soon dissipate into a thin air. All those ADF silent updates, that even the Microsoft support team is not aware of, will bring you a lot of joy to see bugs being resolved, new features being introduced, or even all ADF activity icons being changed to something more colorful and renewed.
- Multiline support in expressions

- Data Type validation

- Skipping duplicate columns

I am a firm believer that to cut time in software development projects, good training on how to use development tools effectively in those projects will be valuable. I acknowledge that it took me a while to notice these skipping options in the Select data flow transformation, and the actual reading of the ADF documentation helped me to cover a simple use case of returning the same empty string '' column as two separate columns without being “skipped”.
However, along with these and many other little things that I can find in my working experience with Azure Data Factory there are other types of "little" things that considered not that important, but they may potentially bring your frustration to another level.
- Naming in Data Flows
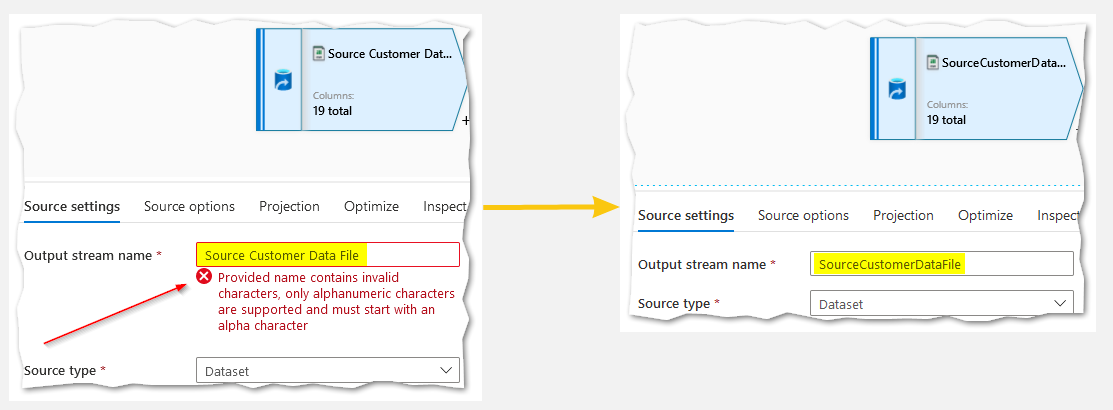
Currently, in ADF data flows you’re not allowed to have space (‘ ‘) characters in the naming of your transformation steps along with sources & sinks. And it’s not very convenient to always rely on Capitalizing Each Word and then combine them together into one construction (“CapitalizingEachWord”), not user friendly at all and it needs some improvement.
- Zooming in Data Flows
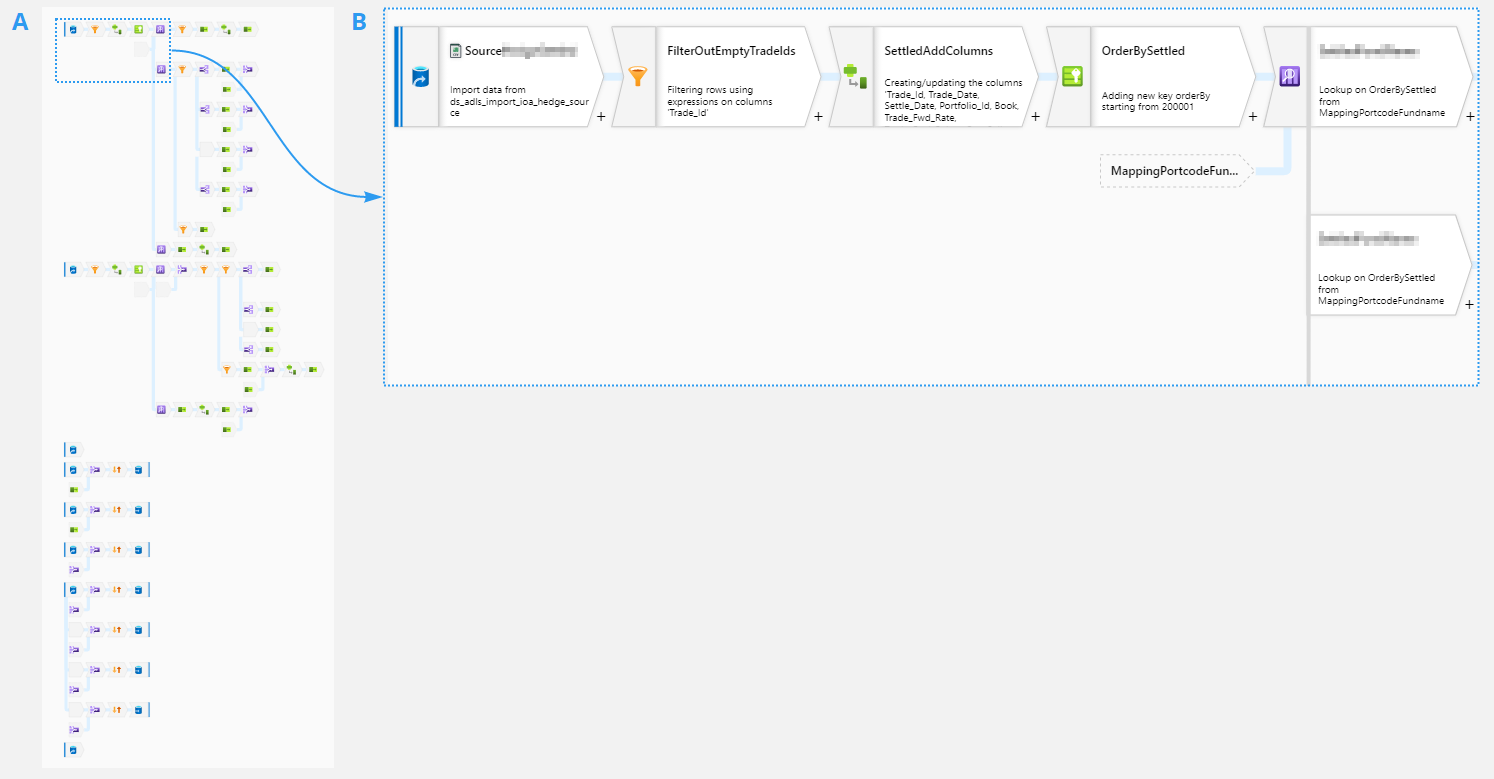
Exhibit A shows a simple data flow where two sourcing files are getting transformed into 7 output files with the help of a series of merging transformations. If I want to make further updates to this data flow and open it in my data factory, then I will always get see it in a “zoomed to fit” fashion. It then takes a few manual “zoom in” operations to get a close look at a particular region (Exhibit B). When I try to update the code or script of my data flow and save it, I get back zoomed out to the original “refreshed” look, and then I have to repeat my “zoom in” operations again. This is not very user friendly at all and it needs some improvement too. I would really like to see some enhancements in preserving a previous zoom state when I open the very same data flow again.
I don’t have any closing notes for this blog post, since a concept of little things that you may or may not like in Azure Data Factory is very subjective and it’s definitely not a universal truth, but thanks for reading 🙂