

Okay, the title of this blog post could also have been “SUMX returns unexpected results with duplicates”. The results only seem incorrect because an incorrect assumption might have been made. Let’s dive into the issue with an example.
The Problem
Suppose we have employees entering timesheet data. An employee can work on multiple projects in the same day, and each employee has a cost assigned to him. Here’s some sample data:
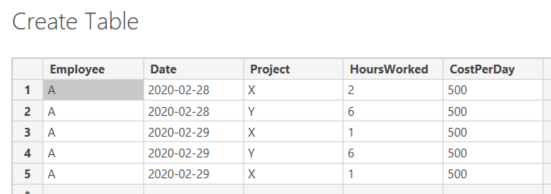
Employee A has worked for two different projects on two different days. The first day, he works 2 hours for project X and 6 hours for project A. The day after, it’s the same. This time however, the employee made a mistake entering the timesheet: he entered 1 hour instead of 2 hours for project X. Instead of correcting the line, he simply adds another one with also 1 hour. This results in “duplicate” rows in the table, although they are very legit. The CostPerDay column indicates the cost the company has for having that employee. You can compare it with a Unit Price column, for example.
All right, now we want a simple report showing us the average cost per project for the employee. We add the data into Power BI Desktop and create the following measure for the number of hours worked (because explicit measures are better than implicit measures!):
Worked Hours = SUM(Timesheet[HoursWorked])
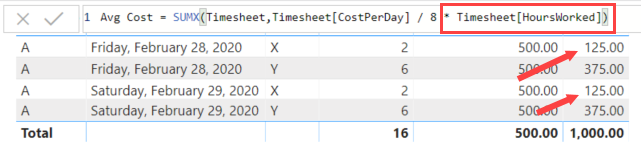
We also create a measure where we multiply the number of hours worked with the cost per day divided by 8 (the standard number of work hours in a single work day). This gives us the following formula:
Avg Cost = SUMX(Timesheet,Timesheet[CostPerDay] / 8 * [Worked Hours])
When we add this to a table, we get this:
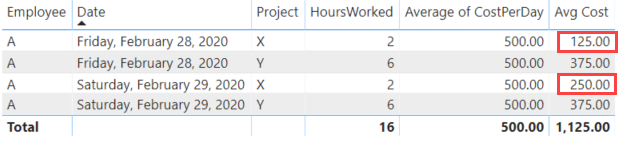
Hold on, the result is different for the 29th than the 28th? This is what the title means with incorrect (or unexpected) results. Even though the data looks exactly the same in the table, the result are not.
It is not a bug in the DAX formula language. The problem resides with the duplicates in the table. When calculating the SUMX, DAX has a context transition, where the row context is switched to a filter context. However, the filter context includes the duplicates, therefore the result is higher for the 29th. It’s a bit hard to follow, but luckily Marco Russo has an entire blog post on this, where he also warns for duplicates. You can only assume the context transition works if there is a primary key on the table, which in this case there is not. I definitely recommend you read that article.
The Solution
There are three ways to solve this issue:
- Don’t use an explicit measure inside the SUMX (so there’s no context transition bothering us). When we change the formula, we get the correct result:

However, I still prefer to use explicit measures, so I’d like to avoid this option. - Add an index column to the table in Power Query. This will force a primary key on the table, which will resolve the issue without you changing the model (except adding this column of course) or by changing the formulas. It does result in a little bit more overhead in the model.
- Do the calculation in Power Query instead. With this option, the calculation is done on the row level before it even enters the model. We can add the following M formula:
= [CostPerDay] / 8 * [HoursWorked]
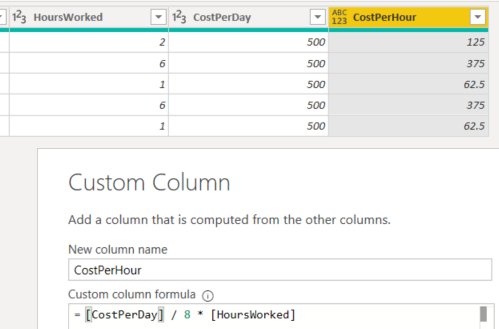
When we use this measure in the table, we can see it returns the expected results:

The last option is my preferred one, as it removes the need for a SUMX measure (which is an iterator and might have bad performance) and because it follows the best practice of doing calculations as early as possible.