
(2020-Apr-24) Using UNION SQL operator is a very common practice to combine two or more datasets together, it helps to create a single result set from many sourcing ones.
Azure Data Factory (ADF) Mapping Data Flows has a similar capability to combine two streams of data with the help of Union transformation, where both data streams can be stacked using either columns' names or columns' positions within datasets. Nothing special, it's a usual way of doing things.
Image by Free-Photos from Pixabay
Recently I had a chance to work on a special case of creating a file where the first two rows were static and contained output table metadata (columns names and column types), assuming that further reading process would be able to explicitly identify each column data type and consume new file correctly in a single run.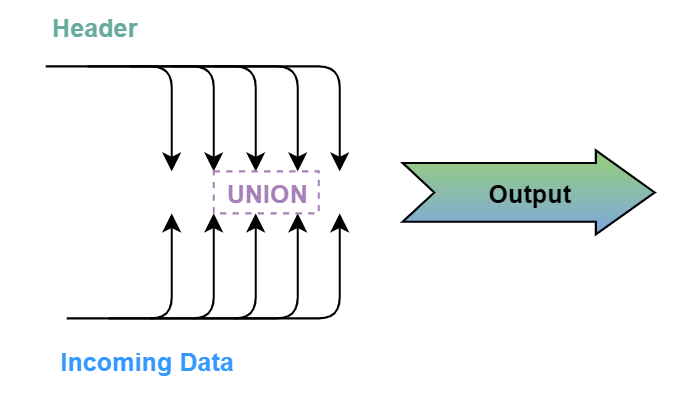
Another way to look at this case will be when a table header would provide both columns names and column data types (source: https://data.world/data-society/global-climate-change-data).
As I have mentioned earlier, it's very easy to create this data flow process in the Azure Data Factory.
Sourcing files
My header file will contain only 2 records (column names and column data types):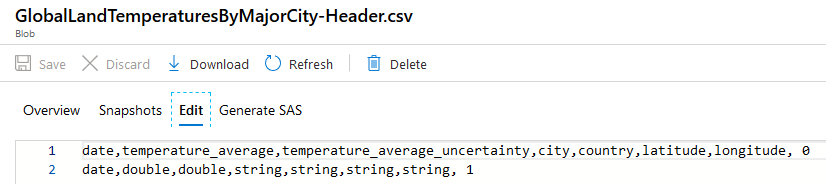
Incoming data file contained temperature records for some of the major cities around the world and I was only interested to extract Canadian cities temperature information: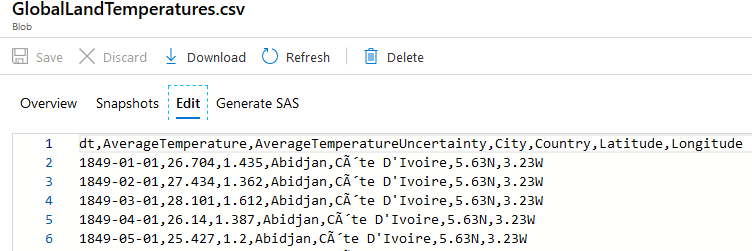
ADF data flow transformation steps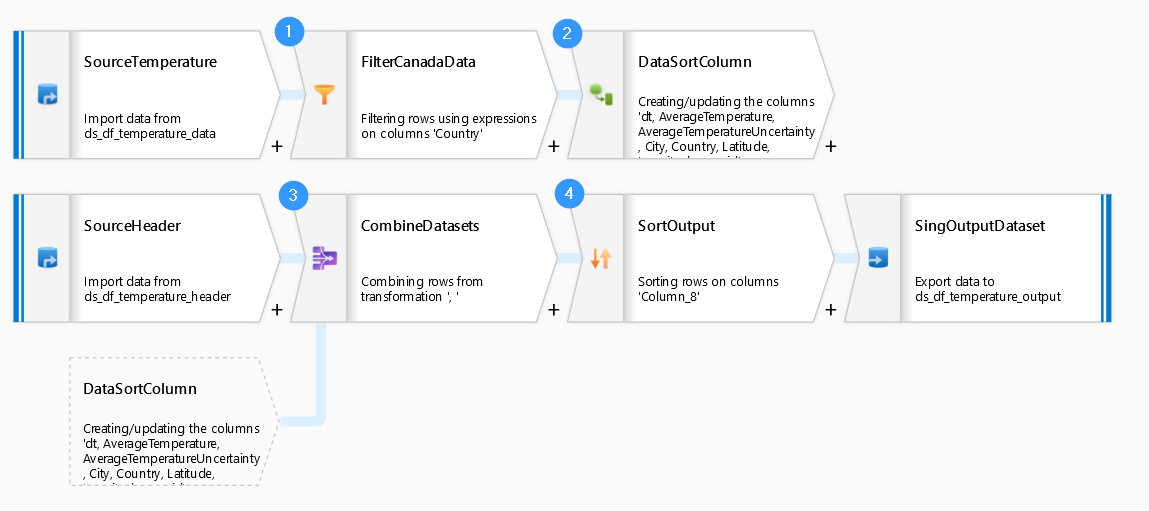
(1) Filter the incoming data sets with the following condition: Country == 'Canada'
(2) Derived Column row_id with a value equals to 2 (or something greater than 1).
(3) Union SourceHeader & updated SourceTemperature datasets: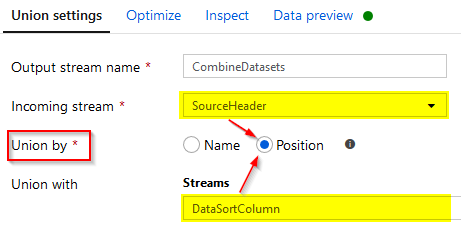
(4) Sort combined datasets by row_id column in ascending order before saving it into an output file.
Output result set
So, even this whole process to create a mapping data flow in Azure Data Factory to union two data files was very trivial, and I definitely didn't try to show off my development skills 🙂
Just an idea that we can physically segregate header metadata with column names and data types in a separate static file and then always attach it to various dynamic incoming data sets with the UNION data transformation, had simplified my process to create the output file that I needed.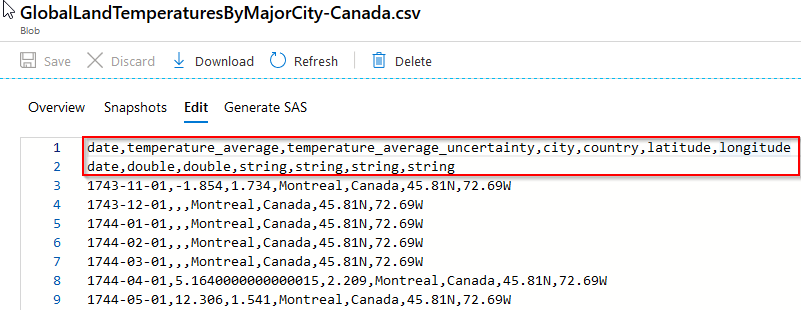
Another benefit of using Data Factory Mapping Data Flows!