

Don’t know about you, but one of my least favourite data pipeline errors is the age-old failure caused by schema changes in the data source, especially when these don’t need to be breaking changes!
In this quick post I’ll be showing you how we can use Delta Lake and Databricks to automatically evolve the Sink object schema for non-breaking changes in our source object.
But first, what do I mean by non-breaking changes. Well, these are changes where a schema change will not affect the integrity of the sink object, for example the addition of a table column. An example of a breaking change would be going from a string data type to an integer data type. Needless to say in this case we want schema enforcement. Fortunately for us, we can have the best of both worlds in Delta Lake.
Personally I like my Sink object to contain the superset of columns when compared to my Source object. That is to say that the Sink will contain every column that ever existed in the source, even if that column is no longer present in the source object. Of course you don’t have to do this, but I don’t like getting rid of historical data, unless there is a specific requirement to do so, such as GDPR regulation.
The code below assumes you already have your Source and Sink objects read into data frames named dfSource and dfSink respectively.
Next we have to read each dataframe’s schema into StructType variables, named dfSourceSchema and dfSinkSchema and then compare the schemas.

I use the schemaMatch variable below to determine whether to execute the schema merge code or not.
Simply put, the code iterates through each StructField item in the StructType variables to determine which field is not present in either the Source or Sink side. As you can see, the code works out whether the merge is required on the Source or Sink, and performs the merge accordingly.
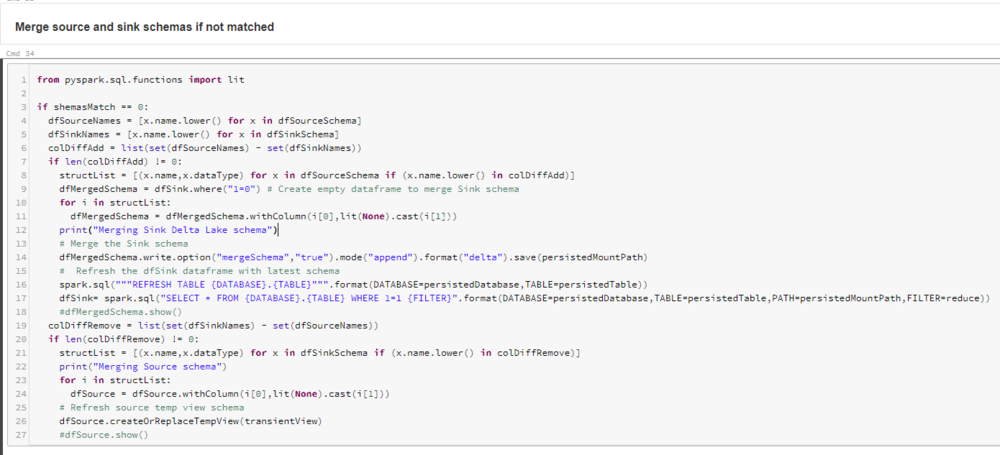
Note that I do the merge using an empty dataframe:
dfMergedSchema = dfSink.where("1=0")
From here I can use the standard MERGE INTO syntax to merge data using the INSERT/UPDATE * notation as I have all the columns present in both the Source and Sink.
As usual, you can find the source code in the Github Repo. Thanks for reading.
![]()