Scary Scalar Functions series overview
- Part One: Parallelism
- Part Two: Performance
- Part Three: The Cure
- Part Four: Your Environment
Foreword
In the previous posts, we have learned why Scalar Functions (UDFs) are bad for parallelism and performance and what the options are for their removal.
The only remaining question is where to start. You’ve probably guessed there isn’t one true way to approach this. So instead, I offer several strategies that you can combine.
Optimize your workload regardless of Scalar functions
Open your favourite monitoring tool (mine is Query Store) and find the Top CPU consuming queries in your workload. Optimize as usual, but if you run across a UDF, you probably have an easy win right there.
UDFs In table and view definitions
That means Check constraints and Computed columns.
While these might be harder to replace (sometimes you have to move the logic elsewhere), these will have a significant impact. Because Scalar UDFs are parallelism inhibitors for anything that touches those tables, there is a good chance you want that parallelism enabled.
UDFs In Triggers
Similar logic. You’ll be paying the UDF tax if your table has any activity that triggers the Triggers. I would start with the most frequently accessed tables.
Easy to rewrite UDFs
Maybe you need some quick and easy wins to get people on board with the idea of getting rid of the UDFs. Easy to rewrite can mean several things:
- Not referenced in many objects - so they are easy to replace with fewer deployments.
- Easily testable. Maybe it has only a few parameters or not many code paths.
- Easy to convert to Inline Table-valued function (ITVF). It might already only have one statement, and the only change you need is to replace
RETURNS [data_type]withRETURNS TABLE.
A code snippet later in this post helps with finding UDFs with the lowest number of references.
Top resource-consuming UDFs
A DMV sys.dm_exec_function_stats tracks the aggregated statistics of cached functions. That means a server restart or other activity clears the cache and affects it. Nonetheless, it’s where you can find the worst UDF performance offenders across the whole instance.
Snippets
Now that we’ve covered the strategies, here are a few useful snippets. This time I’m providing them in the gist format in case of future improvements.
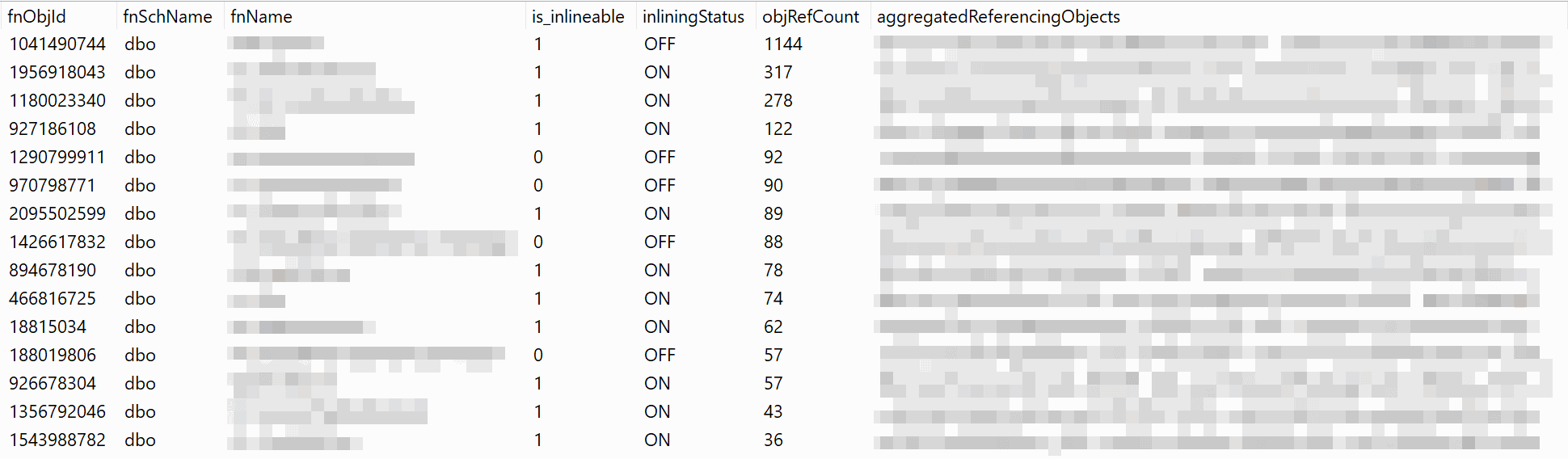
Finding the references
The first result set shows the UDFs in a Table definition, Trigger or View.

The second result set shows how many times and which objects reference the UDF (and how hard it will be to replace across the board).
Finding the performance stats of Scalar UDFs
The result could look like this. It was taken from an instance with quite a few active Scalar Functions.
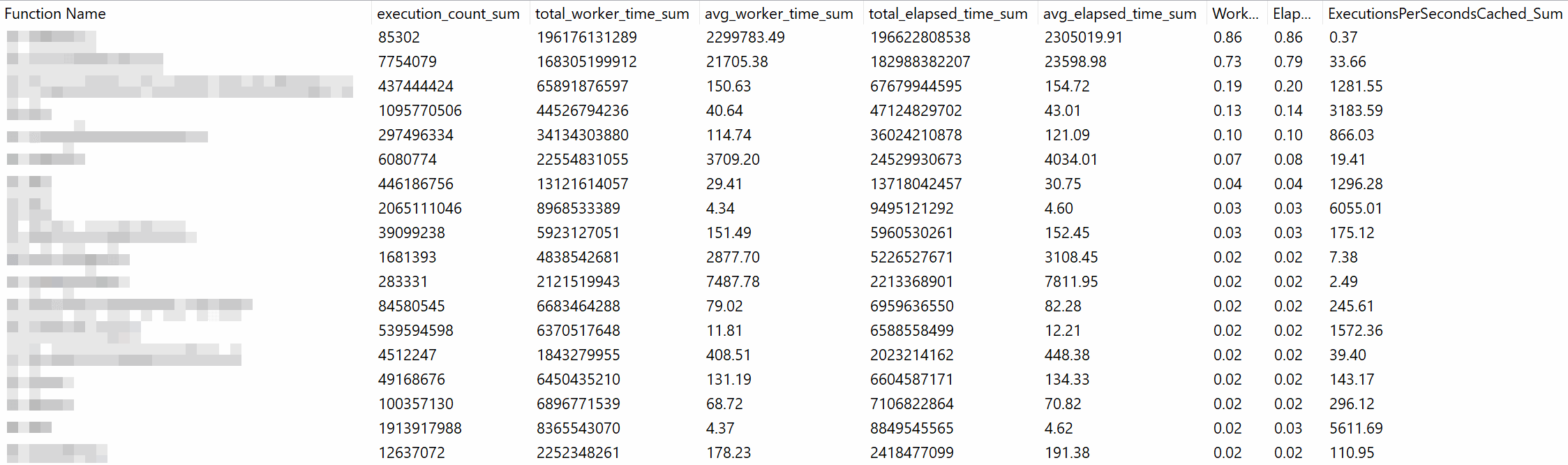
All the values are in microseconds (unless specified otherwise). Because different plans might be in cache for various periods, the default ordering is by worker time (CPU) in seconds per second cached. But it has many dimensions, so you can order it any way you want it (if that’s the way you need it).
Recap
We’ve covered several techniques to triage and pick the Scalar UDFs candidates for a rewrite.
However, the call to action from the last post still applies - provide me with an example of a Scalar UDF, and I’ll post a tutorial on how to rewrite it to ITVF.
Otherwise, this post concludes the series. I hope you found it helpful, and once again, thank you for reading.