

I recently published a post detailing the new Scalar UDF Inlining feature in SQL 2019 here. That post introduced the new feature in a way that I used to compare performance to the other function types, continuing the performance evaluation of functions that I had previously posted here and here. In the Scalar UDF Inlining post, I used a function to strip all non-numeral values from a string, and to return the result. This used the FOR XML output option.
In thinking about how scalar functions are commonly used, I’ve decided to revisit this feature with a simpler function. I will still compare it to all the other types of functions to see how Scalar UDF Inlining compares to the others.
Scalar UDF Inlining Recap
Scalar UDF Inlining takes the operations that the Scalar UDF performs, and inlines those operations into the query plan, similar to a view or an Inline Table-Valued Function. To be able to inline the function, there are some requirements (see the link in the first sentence of this paragraph) that the function must meet.
The Test Environment
As I stated before, I want to run this test with a simpler function. I decided to have the function accept a number, and to return the number multiplied by itself. As in the previous test, we’ll use two databases (one in SQL 2019 compatibility mode, and the other in SQL 2017 compatibility mode):
USE master; GO DROP DATABASE IF EXISTS FunctTest140; DROP DATABASE IF EXISTS FunctTest150; GO -- create databases CREATE DATABASE FunctTest140; ALTER DATABASE FunctTest140 SET COMPATIBILITY_LEVEL = 140; CREATE DATABASE FunctTest150; GO
Inside each database, I’ve created a tally table, and three functions (one Scalar, one Inline Table-Valued Function (iTVF) and one Multi-Statement Table-Valued Function (MSTVF)):
-- build environment in each database
USE FunctTest150; -- repeat for FunctTest140
GO
-- create a 1,000,000 row table to test against
CREATE TABLE dbo.Tally (N INTEGER CONSTRAINT PK_Tally PRIMARY KEY);
WITH Tens (N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
Hundreds(N) AS (SELECT 1 FROM Tens t1, Tens t2),
Millions(N) AS (SELECT 1 FROM Hundreds t1, Hundreds t2, Hundreds t3),
Tally (N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM Millions)
INSERT INTO dbo.Tally (N)
SELECT N FROM Tally;
GO
-- create the functions. These just multiply the number by itself.
CREATE FUNCTION dbo.ITVF_Test (@N BIGINT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT @N * @N AS ReturnValue;
GO
CREATE FUNCTION dbo.MSTVF_Test (@N BIGINT)
RETURNS @Output TABLE (ReturnValue BIGINT)
WITH SCHEMABINDING
AS
BEGIN
INSERT INTO @Output (ReturnValue) VALUES (@N * @N);
RETURN;
END;
GO
CREATE FUNCTION dbo.SF_Test (@N BIGINT)
RETURNS BIGINT
WITH SCHEMABINDING
AS
BEGIN
RETURN @N * @N;
END;
GOWith these functions created, we run a simple test to see that they work properly:
-- test the functions
SELECT TOP (10)
t.N,
dbo.SF_TEST(t.N) AS ScalarFunction
,MSTVF.ReturnValue AS MultiStatementTVF
,ITVF.ReturnValue AS InlineTVF
FROM dbo.Tally t
CROSS APPLY dbo.MSTVF_TEST(t.N) MSTVF
CROSS APPLY dbo.ITVF_TEST(t.N) ITVF;
GOThis returns the following result set:

And the following execution plan (SQL 2017):
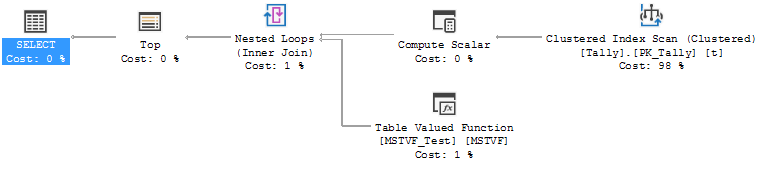
Notice that there is only one “Compute Scalar” operator that handles both the Scalar UDF and the iTVF. Inside this operator, all of the scalar operations that can be performed at this level are performed. Let’s look at this operator’s properties:
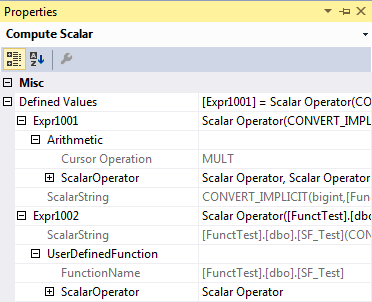
Expr1001 is:

And Expr1002 is:

Be reviewing these, we can see that Expr1001 is for the iTVF, and Expr1002 is for the Scalar function. Even though they can both be pulled into the execution plan into the same query operator, they are doing different things. We can now continue on to…
The Performance Test
Just like in the last post, we’ll run each function individually against the tally table, dumping the results into a temp table. The test against each function is run 10 times. The testing query is:
-- Create a table to store the results in.
IF OBJECT_ID('tempdb.dbo.#TestResults', 'U') IS NOT NULL DROP TABLE #TestResults;
CREATE TABLE #TestResults (
RowID INTEGER IDENTITY,
FunctionName sysname,
ActionDateTime DATETIME2(7) NOT NULL DEFAULT(SYSDATETIME()));
GO
TRUNCATE TABLE #TestResults;
IF OBJECT_ID('dbo.FunctionResults', 'U') IS NOT NULL DROP TABLE dbo.FunctionResults;
INSERT INTO #TestResults (FunctionName) VALUES ('ITVF_TEST');
SELECT t.N,
ITVF.ReturnValue
INTO dbo.FunctionResults
FROM dbo.Tally t
CROSS APPLY dbo.ITVF_TEST(t.N) ITVF;
INSERT INTO #TestResults (FunctionName) VALUES ('ITVF_TEST');
IF OBJECT_ID('dbo.FunctionResults', 'U') IS NOT NULL DROP TABLE dbo.FunctionResults;
INSERT INTO #TestResults (FunctionName) VALUES ('MSTVF_TEST');
SELECT t.N,
MSTVF.ReturnValue
INTO dbo.FunctionResults
FROM dbo.Tally t
CROSS APPLY dbo.MSTVF_TEST(t.N) MSTVF;
INSERT INTO #TestResults (FunctionName) VALUES ('MSTVF_TEST');
IF OBJECT_ID('dbo.FunctionResults', 'U') IS NOT NULL DROP TABLE dbo.FunctionResults;
INSERT INTO #TestResults (FunctionName) VALUES ('SF_TEST');
SELECT t.N,
dbo.SF_Test(t.N) AS ReturnValue
INTO dbo.FunctionResults
FROM dbo.Tally t
--CROSS APPLY dbo.ITVF_TEST(t.N) ITVF;
INSERT INTO #TestResults (FunctionName) VALUES ('SF_TEST');
---------- Show the testing results -----------
WITH cte AS
(
SELECT t.FunctionName,
DATEDIFF(MICROSECOND, MIN(t.ActionDateTime), MAX(t.ActionDateTime)) AS [Duration (microseconds)]
FROM #TestResults t
GROUP BY t.FunctionName
)
SELECT DB_NAME() AS DatabaseName,
FunctionName,
[Duration (microseconds)],
CONVERT(NUMERIC(5,2), (cte.[Duration (microseconds)] * 1.0 / SUM(cte.[Duration (microseconds)]) OVER () * 1.0) * 100.0) AS PercentOfBatch
FROM cte
ORDER BY [Duration (microseconds)];
GO 10The SQL 2017 results are:
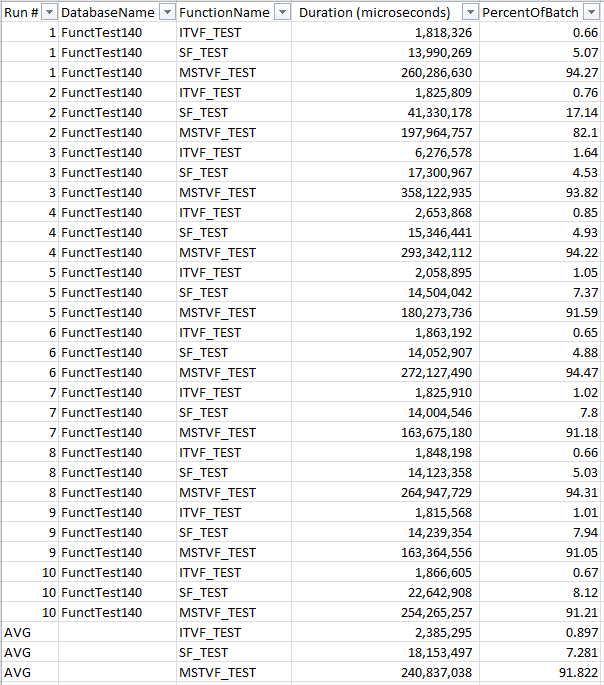
The SQL 2019 results are:
Wow, the scalar function performance has improved so well that the times are essentially a tie. The average shows just how close they are. The scalar function even beat out the iTVF several times (highlighted in yellow above).
In conclusion…
In my last post, I concluded that the iTVF was still a bit faster, and recommended still using that. With this post, my recommendation is that for simple Scalar UDFs, it be enough. For more involved functions, it requires some testing to determine which implementation would be better. This testing is to determine if the Scalar UDF can run as good as the iTVF. You can avoid this testing by just using an iTVF if possible. If you have an existing application, Scalar UDF Inlining will improve the performance just by being in the SQL 2019 compatibility level.
As all of these function tests have shown, only use Multi-Statement Table-Valued Functions if you can’t do it in another way.
Update
LondonDBA noted in the comments below that I had a copy / paste error in my test, specifically when dealing with the scalar function. That is the highlighted line in the above testing code (it was not remarked out). Since this issue could affect the performance in both databases, I’ve rerun the testing.
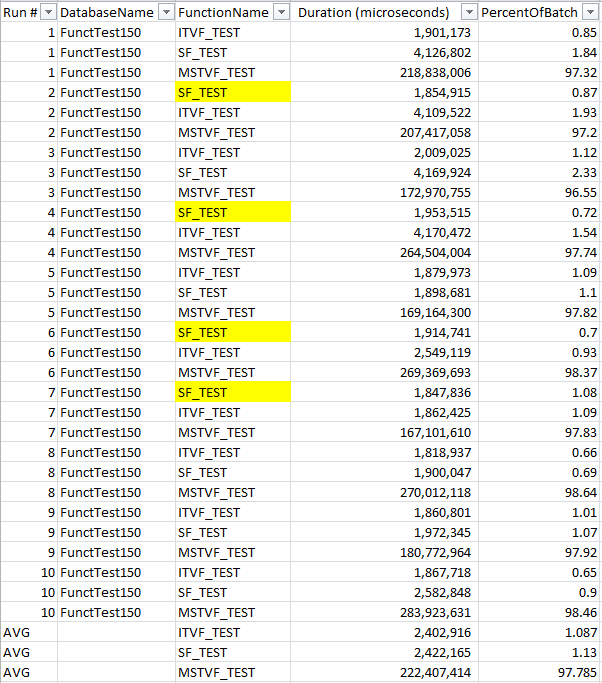
SQL 2017 results:
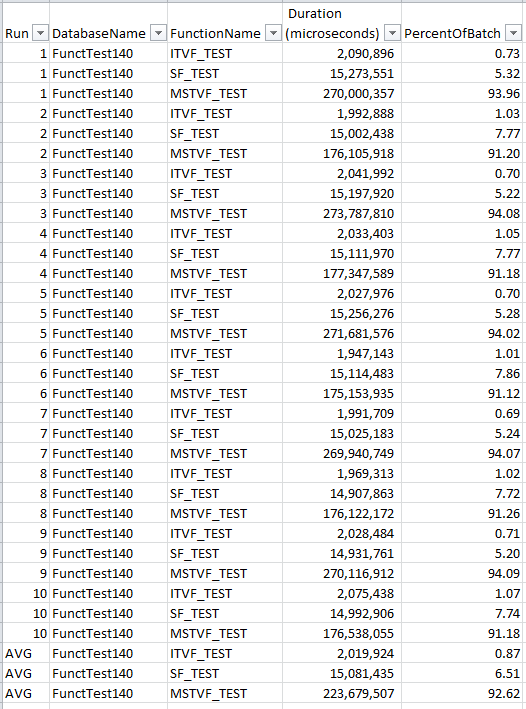
SQL 2019 results:
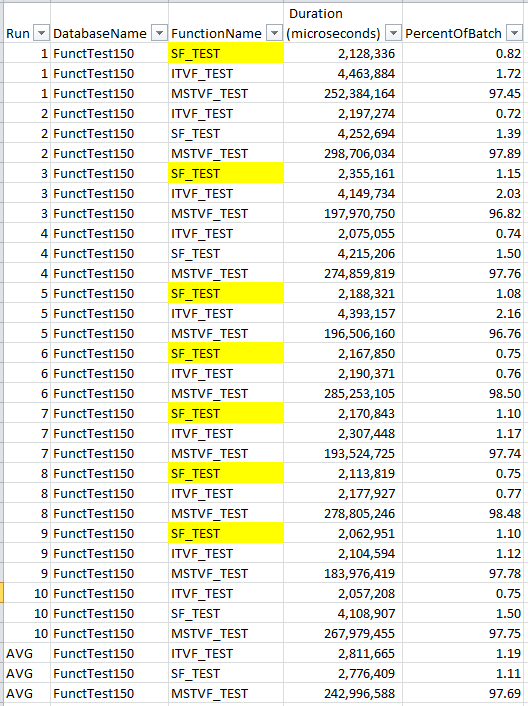
With this test, the scalar UDF is, on average, performing ever-so-slightly better than the iTVF. We can also see that in 7 of the 10 runs, it ran the fastest. Scalar UDF Inlining is definitely a game changer when considering what type of function to use. You do still need due diligence to test the functions to ensure that it performs the best for you. ![]()
The post Scalar UDF Inlining in SQL Server 2019 – Simpler functions appeared first on Wayne Sheffield.