(2021-Sep-21) There is one scene in "The Core" movie that I really like when two geophysicists were asked to explain certain anomalies that were projected on a computer screen. One of the geophysicists started to mumble in his attempt to answer the question, the other one told him, "Say it with me: I don't know". Though the scientific accuracy of this movie is more than questionable, the acting of this character reveals a very important and valuable virtue to recognize personal ignorance instead of portraying an informed unawareness.
Here is a common data scenario: you have massive incoming data that flows into your data storage. Your immediate intention is to have all pre-calculated aggregations based on this incoming data right away, but you also understand that achieving correct and accurate data aggregation is a time-consuming process: you’re facing a dilemma to balance your data latency (the time between the creation of data in a source system and the exact time at which the same data is available for end users on the business intelligence platform) and throughput (a measure of how many units of information a system can process in a given amount of time).
There are several options to balance data latency and throughput:
- You tank your intentions to get accurate results in a short period of time based on the incoming sourcing data and settle with semi-correct aggregations that can be produced in almost no time: low latency ó high throughput ó incremental processed data is almost correct.
- Opposite to the first option, you settle with a significant waiting time to produce accurate output data that will meet all of your data quality standards: high latency ó low throughput ó accurate processed data.
- Or you can tell yourself, I will be good with the almost correct data (1st option), but only for a short period, and during this time I can wait for the same sourcing data to be thoroughly and correctly processed (2nd option) to replace short-lived “almost” correct results form the 1st option. You're looking at the 1st and 2nd options combined.

Image source: Big Data on Azure with No Limits Data, Analytics and Managed Clusters
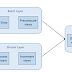
Batch layer, contrary to the speed layer takes more time to produce correct results and is used to fix or repair any incompleteness or incorrectness of data generated by the stream layer.
Serving layer provides a combined view with accurate data up to the last processed batch along with almost immediately available new data in the stream data layer, which is still almost "accurate".
This whole agility to provide output data by processing it accurately and efficiently using both Speed and Batch layers lead to maintaining two different technological solutions, which may be difficult in a long run.
But what about the meaning of the Lamda Architecture? What does Lamda mean in this term?
Initially, I thought that it was related to the Lamda Calculus that expresses computation based on function abstraction and application using variables, similarly to the Data System equation in the Marz, Nathan’s article: "How to beat the CAP theorem”, which defines a data system:
Query = Function(All Data)However, this formula is very generic and can be applied to other data system architecture as well.
Then I thought that Lamda Architecture and Lamda specifically is named this way because of the visual representation of this Greek letter (?), where two data streams (speed and batch layers) are divided and sourced from the same origin.
But what was the real origin of the Lamda Architecture term, I still don’t know, and I’m OK with this 🙂
PS. If you have endured and read my whole blog post, here is a link to a video clip from “The Core” movie where both geophysicists had exposed their ignorance (or lack of it) by admitting that there are some things they don’t understand.