

AFAS is a Dutch business software company, proving companies with ERP and HR software-as-a-service. You can extract data from the service using a REST API (there are also SOAP web services available for those who appreciate the trip down memory lane). In this blog post I’ll show you how you can get data out of AFAS using Azure Data Factory (ADF). Luckily, the process is quite straight forward, in contrast with the ExactOnline API.
To expose the data, you need to define a GetConnector. In such a GetConnector, you define a set of fields (typically related) and optional filters on top of the data model. AFAS will then create a REST endpoint for you to extract the data from the GetConnector. Creating GetConnectors is not the focus of this blog post, I assume they’re already created for your environment. After you’ve created one or more Getconnectors, you need to add them to an App Connector. In an App Connector, you need to create a token for authentication.
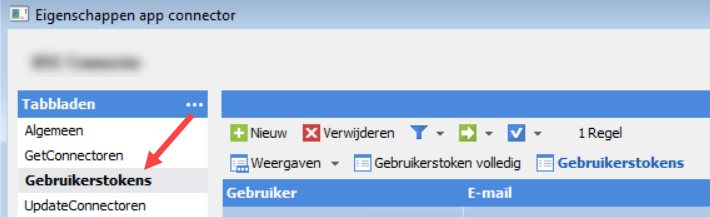
The token is used to authenticate against the REST API. You can store it a secure location, such as Azure Key Vault. It needs to be in a specific XML format (probably some backwards compatibility with the old SOAP web services). Suppose your token is “123”. Then the full token should look like this:
<token><version>1</version><data>123</data></token>
Let’s start by creating a linked service in ADF. Search for the REST linked service.

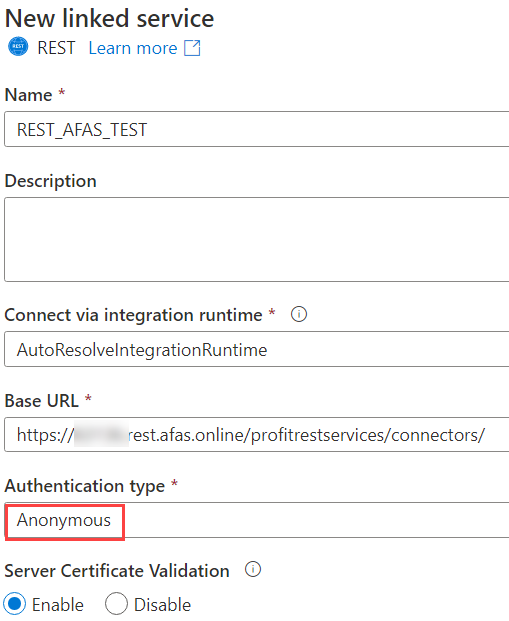
Give the new linked service a name and specify https://xxx.rest.afas.online/profitrestservices/connectors/ as the base URL, where xxx is the member ID of your company in AFAS. Set the authentication type to Anonymous.
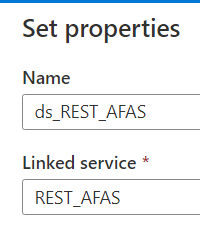
Our next step is to create a dataset. Add a REST dataset, give it a name and link it to the linked service we just created.
The BASE URL is provided by the linked service. The Relative URL will specify to which GetConnector we want to connect. You could hardcode a value, but that would mean you would need to create a new dataset for every GetConnector. We rather want to parameterize this, so we can have a metadata-driven pipeline, as explained in the blog post Dynamic Datasets in Azure Data Factory. So let’s create a parameter for the Relative URL:
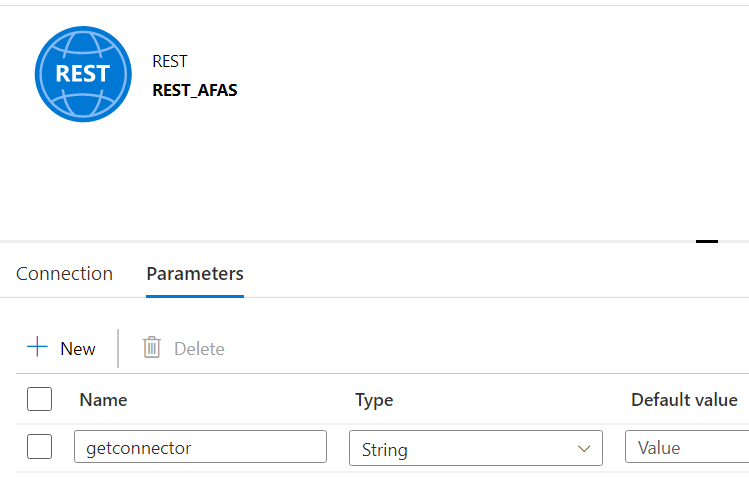
The idea is to have metadata available that will list all of the GetConnectors and their respective Relative URLs. In the final pipeline, we will loop over this metadata and use it to fetch all of the data from the GetConnectors in parallel using a ForEach activity.
For the Relative URL, we can specify an expression:
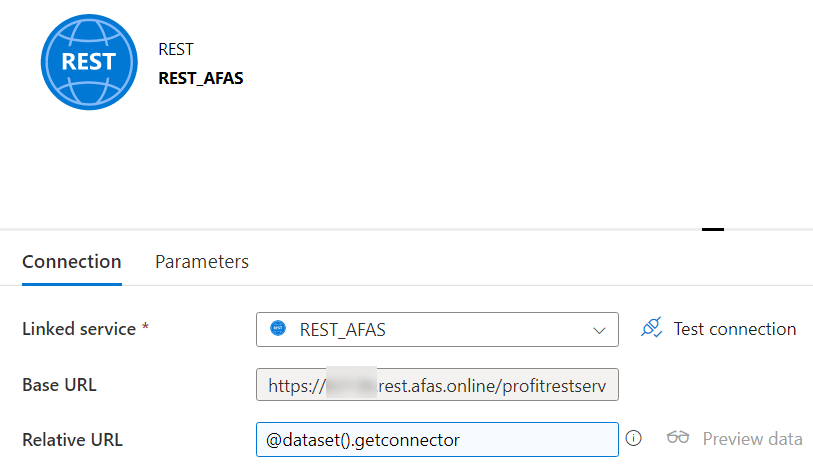
But how does such a Relative URL look like? You can construct one using the AFAS developer portal (which requires you to register). To test a Getconnector, we need to log in first by specifying the AFAS member number and the token.
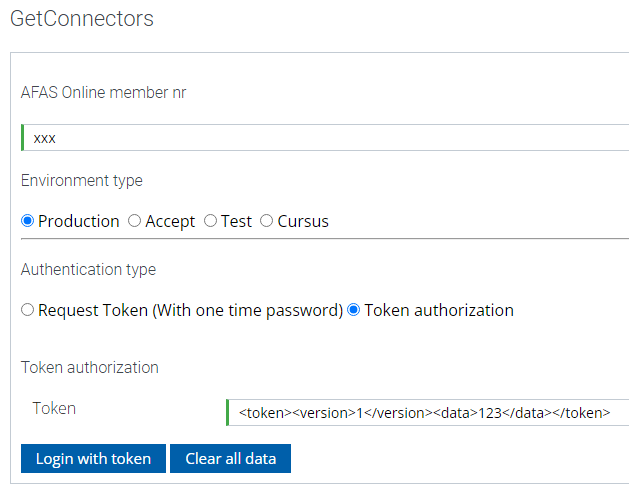
Select a GetConnector from the list to construct the URL.
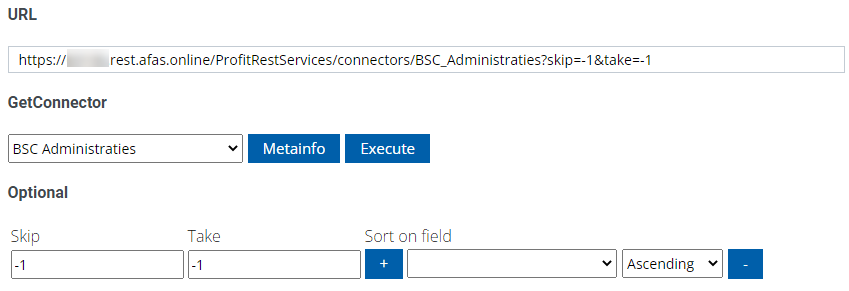
The Skip and Take URL parameters can be used to fetch only a part of the data. If you use -1 for both, you’ll get the entire data set. This is not recommended for large volumes of data, as it might lead to time-outs or other errors. For large data sets, you might want to implement your own pagination using the skip&take parameters (don’t forget to sort the data as well to get consistent results).
For smaller sets of data, our Relative URL will look like this: GetConnectorName?skip=-1&take=-1. For larger sets, you can either paginate as mentioned before, or you can filter the data. Specifying a filter is a bit special in AFAS, so it’s recommended you use the developer portal to create filter on your GetConnector to get the syntax right. Let’s illustrate with an example. Our GetConnector has a field “Datum” on which we want to filter. It’s a timestamp, and we want to filter between two dates. In SQL, we would write this in a WHERE clause:
Datum >= '2022-01-01T00:00:00' AND Datum < '2022-02-01T00:00:00'
Let’s enter this info in the dev portal:
The URL parameter part (everything after the question mark) will now look like this:
?filterfieldids=Datum%2CDatum&filtervalues=2022-01-01T00%3A00%3A00%2C2022-02-01T00%3A00%3A00&operatortypes=2%2C5&skip=-1&take=-1
Let’s break this down:
- filterfieldids is a comma-separated list of all the fields we want to filter on. Since we’re filtering twice on the field “Datum”, we need to specify it twice. The “%2C” is URL encoding for the comma.
- filtervalues is a comma-separated list of the values we want to pass to the filter. Of course, it’s crucial to have the some order as the fields we specified in the “filterfieldids”. “%3A” is URL encoding for the colon. 2022-01-01T00:00:00 becomes 2022-01-01T00%3A00%3A00.
- operatortypes is yet again a comma-separated list, but this time for the operator. Each operator has its own number.
- skip and take are already discussed. They go to the back of the URL.
Regarding the operators, here are some examples:

A full list can be found in the documentation. The final pipeline will look like this:
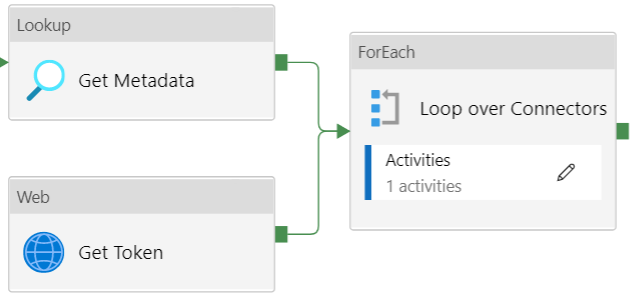
The Lookup activity will fetch the metadata from a repository (I opted for a table in Azure SQL DB). This repo contains the different GetConnectors and their respective Relative URLs. The Web Activity places an API call to Azure Key Vault to retrieve the AFAS token. The ForEach activity will loop over the GetConnectors:
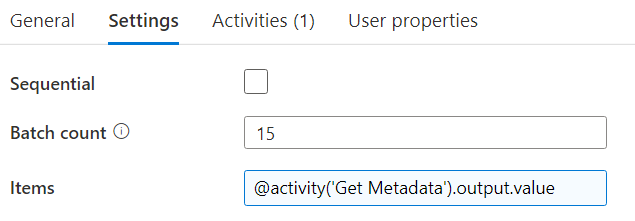
Inside the loop, there’s a Copy Data activity will fetch the data from the current GetConnector and dump it into a sink. The source config looks like this:
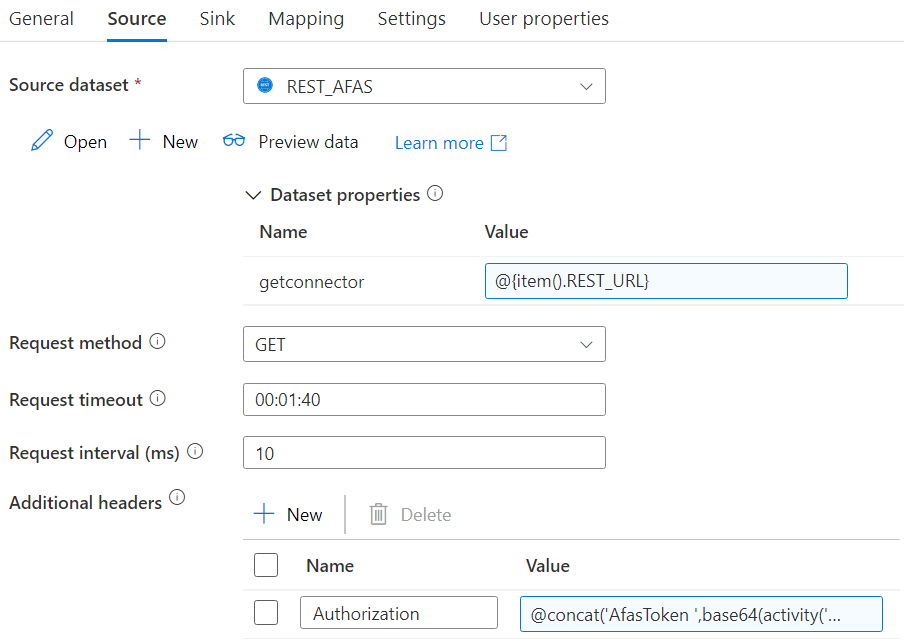
We map the Relative URL from the metadata to the dataset parameter. We also need to specify an authorization header. This is the AFAS token we retrieved from Azure Key Vault. However, AFAS expect this to be in a base64 format, prefixed with the text “AfasToken ” (don’t forget the space). The full expression:
@concat('AfasToken ',base64(activity('Get Token').output.value))In the sink you can choose whatever destination you want, as long as it’s compatible with the Json from the source. You can for example write it to a Json file in Azure Blob Storage or Azure Data Lake Storage, or you can flatten the data and write it to a table. Everything in the sink can be parameterized as well:
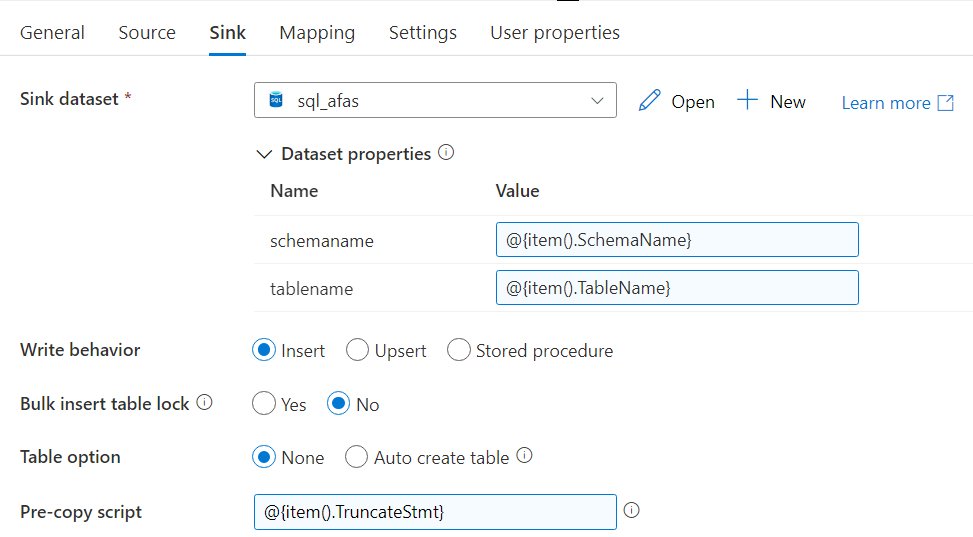
If you want to flatten the data, ADF expects a mapping of the JSON columns to the tabular columns. Since everything is metadata driven, we don’t want to specify an explicit mapping. The blog post Dynamically Map JSON to SQL in Azure Data Factory explains in detail how you can set this up.

That’s it. When you run the pipeline, ADF will load all the GetConnectors in parallel.
The post Extracting Data from the AFAS REST API with Azure Data Factory first appeared on Under the kover of business intelligence.