

When you develop data pipelines in Microsoft Fabric (the Azure Data Factory equivalent in Fabric, not to be confused with deployment pipelines), you will most likely have some activities with a connection to a warehouse, a lakehouse or a KQL database (for the remainder of the blog post I’ll talk about a warehouse, but it can be any of those three data stores). For example, in a Script, Lookup, or Copy activity. When you deploy your data pipeline to another workspace – using, you might’ve guessed it, deployment pipelines – the pipeline itself is copied to the other workspace. E.g., we deploy a pipeline from the development workspace to the test workspace.
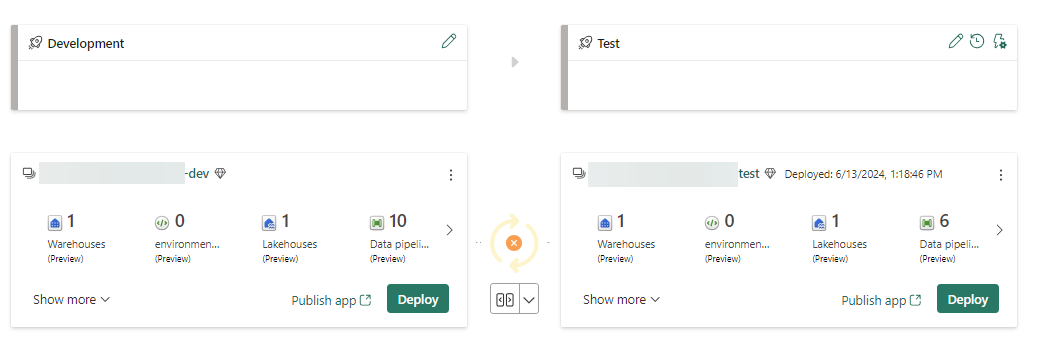
However, the connection to the warehouse remains the same, as in, it tries to find the warehouse of the development workspace. But since the context of the deployed pipeline is the test workspace, it won’t find the original connection.
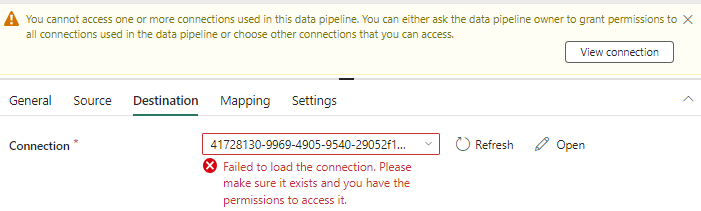
My reaction:

The issue here is that Fabric uses an “absolute” connection to the warehouse in the dev workspace, instead of a “relative” connection. It should be much better if the pipeline looked for a warehouse with the same name in the current workspace. Something like ./my_warehouse, instead of dev_workspace/my_warehouse. Connections to external objects, such as for example an Azure SQL DB or a PostGreSQL database don’t break, because their IDs can be resolved. But they keep pointing at the original source, so if you have a test and a production source database, your production workspace will keep pointing at the test source database, which is probably not what you want.

In any other, normal CI/CD pipeline we would use variables or template parameters to change the connections during deployment. In Fabric deployment pipelines, this feature is called deployment rules. At the time of writing, this is what the documentation has to say on deployment rules for data pipelines:


This basically means deployment pipelines just copy your data pipeline, but the connections remain either unchanged, or broken, so you have to update each pipeline manually to fix the connection.
Alright, that was quite a long introduction to the problem, now let’s move on the the “solution” (fancy word for work around). In this blog post, I’ll explain a pattern you can use that will keep your warehouse connection intact and it will point to the warehouse in the correct workspace. I won’t be able to fix external connections though, so I hope deployment rules for pipelines are released sooner than later.
Instead of “hard-coding” the path to the warehouse, we’re going to parameterize it. This is the original connection:

When you open the dropdown, you can select Use dynamic content.
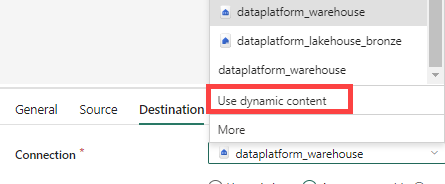
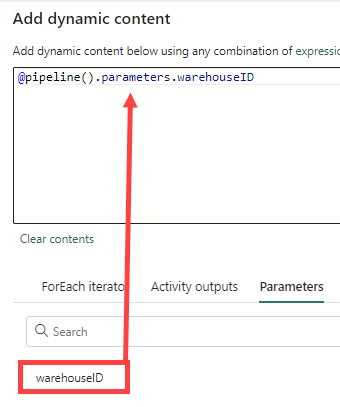
This field will expect the unique ID of the warehouse. Go to the parameters tab and add a new parameter called warehouseID.
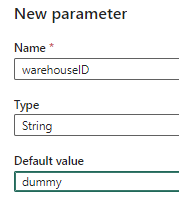
Then add it as an expression.
Click OK to go back to the editor. You will be asked to specify the connection type, which is either warehouse, lakehouse or KQL database:
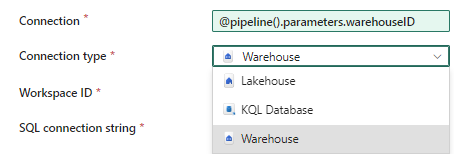
These are the only types of connections that we can currently parameterize and this is why we can’t fix external connections with this work around. For the workspace ID, you can find this under the system variables section of the dynamic content:
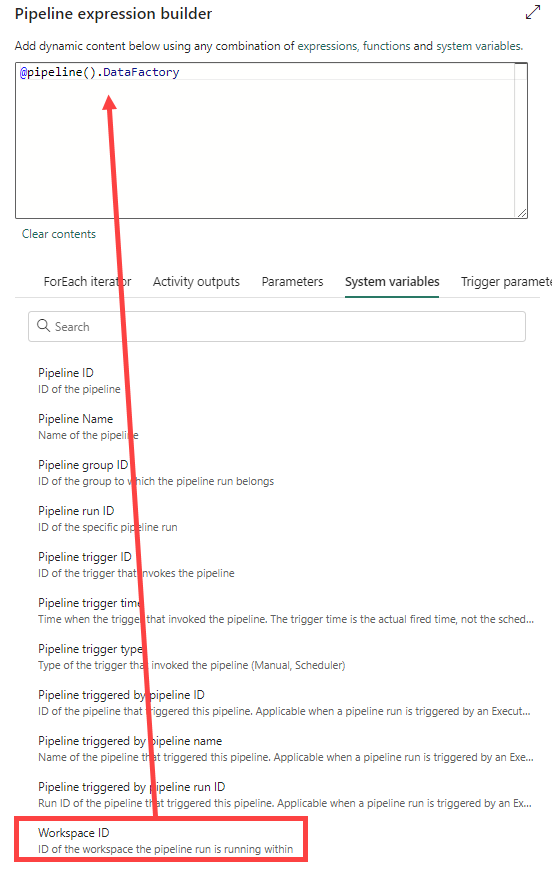
Finally, you need to specify the SQL connection string. I have no idea why. Fabric is perfectly capable of finding this on its own (I mean, if you just select the warehouse you need from the dropdown list, you don’t need to specify a SQL connection string, so why need it here?). We’re going to parameterize this just like we did with the warehouse ID:
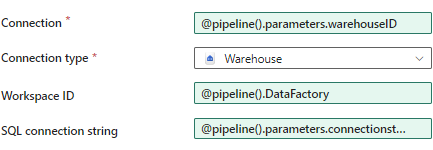
When you now run the pipeline, you will be asked to specify values for those two parameters:
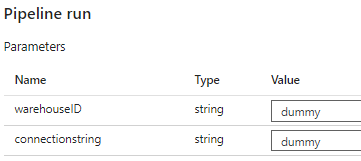
You can find the warehouse ID in the URL when you open up the warehouse in the browser:

https://app.powerbi.com/groups/groupID/datawarehouses/warehouseID/dataView?experience=power-bi
The connection string can be found by clicking the ellipsis next to the warehouse name in the browser which will give you the following context menu:
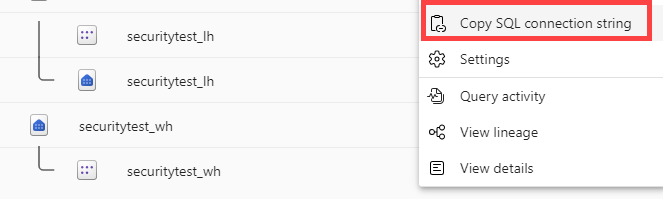
When you now deploy your data pipeline from one workspace to another, the warehouse connection won’t break, but you’ll need to specify the warehouse ID and the SQL connection string. Obviously, we’re not going to manually fill it in every time we want to execute the pipeline. Luckily, we can retrieve this info from the Fabric REST API, using the List Warehouses endpoint. So let’s add a Web activity at the start of your pipeline and create a new Web connection (thanks to the friendly people at Purple Frog for their very informative blog post How to call Microsoft Fabric Data Pipelines dynamically using APIs).
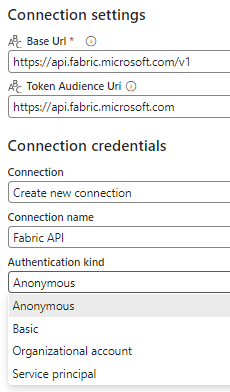
You might be tempted to select “service principal” for the authentication, but alas, the REST API endpoint doesn’t seem to support this yet.
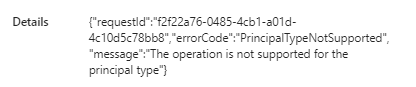
So for the moment we’re stuck with OAuth 2.0 authentication (so either use your own account or some service account), which is less than ideal. Once the connection is made, you can use the following expression for the relative URL:
@concat('/workspaces/',pipeline().DataFactory,'/warehouses')Select GET for the method.
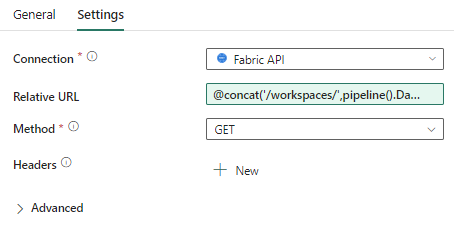
When you run the Web activity, you should get a JSON response with an array containing various properties for the warehouses in your workspace:
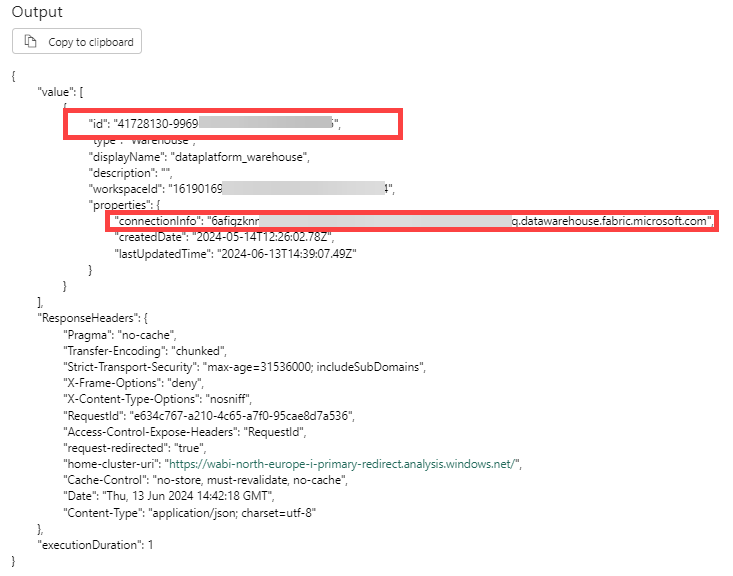
The documentation doesn’t mention it, but the properties also contain the SQL connection string, so that’s great. I have only one warehouse in my workspace, so I can just reference the first item of the array to get the info I need. If you have multiple warehouse, you’ll need to filter the JSON array to get what you need, which is, euhm … an exercise for the reader.
You can get the desired info using the following expressions:
@activity('Retrieve Warehouse Info').output.value[0].id
@activity('Retrieve Warehouse Info').output.value[0].properties.connectionInfoWith these expressions you can replace the parameters we used at the start of this blog post. You can put the Web activity in any pipeline where you need this dynamic connection to a warehouse/lakehouse/KQL database, or you can perhaps put it in a parent pipeline where you retrieve the info once and then push it down to child pipelines using parameters.
I hope this blog post is helpful to relieve some of your CI/CD pains within Fabric.
UPDATE: if you want a better solution for this, please vote on this idea.
The post Dynamic Warehouse & Lakehouse Connections in Microsoft Fabric Data Pipelines first appeared on Under the kover of business intelligence.