

This is the second post in a series about modern Data Lake Architecture where I cover how we can build high quality data lakes using Delta Lake, Databricks and ADLS Gen2. It builds on some concepts introduced in the previous post in this series, so I would recommend you give that a read.
In this post we focus on setting up the Data Lake Storage layer In preparation for data engineering and data science workloads. I.e. we’re laying the foundation for a solid and extensible data lake storage layer.
Let me be clear. I am definitely not the first to write about some of the concepts covered in this post, but my intention is show how these concepts can be applied in practice to deliver a high quality data lake in Azure.
We’ll need to cover some technology agnostic stuff first, starting with Data Lake zoning. What I have found to work really well and appears to have become pseudo best practice, is breaking your Data Lake up into four zones.
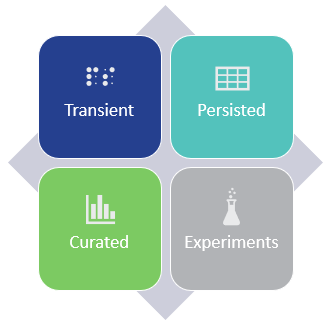
Transient – In this zone, we rest data temporarily as it moves from the source to the persisted area, think staging. Data in this zone is periodically removed, based on the file time-to-live. This zone is called transient for a reason, data does not reside here indefinitely and in some cases this zone can be skipped altogether.
Persisted – Data is kept indefinitely in its raw format and is immutable to change. This zone is often referred to as persisted staging. It provides a historical representation of raw data at any given point in time.
Curated – Data in this zone has been transformed, enriched and/or aggregated to meet specific requirements. You can think of this zone as more closely aligned to traditional Data Warehousing (more on this in a future post in this series), i.e. where a particular schema has been applied to restructure, filter, aggregate and/or join raw data sources.
Experiments – This is a dedicated zone used by analysts and data scientists for “experiments”. Think of this as a sandbox where hypotheses can be tested. Once the experiments are “productionised”, they are moved to the Curated zone. Like the Transient zone, files in this zone are given a time to live so they can be cleaned up by automated processes.
The table below summarises the zones in terms of Data Governance, Access Control and the Level of Processing applied to each zone:
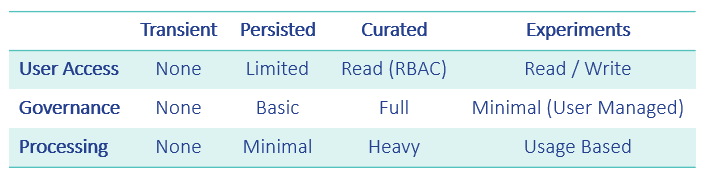
You’ll see why categorising the data into zones becomes important when we implemented on ADLS Gen2. More on this a little later.
We then further organise the zones using a folder structure with two main objectives:
Define a structure for optimal data retrieval, which as an example provides the ability to prune data “branches” during querying
To ensure the Data Lake is self-documenting, thereby making it easy to find data
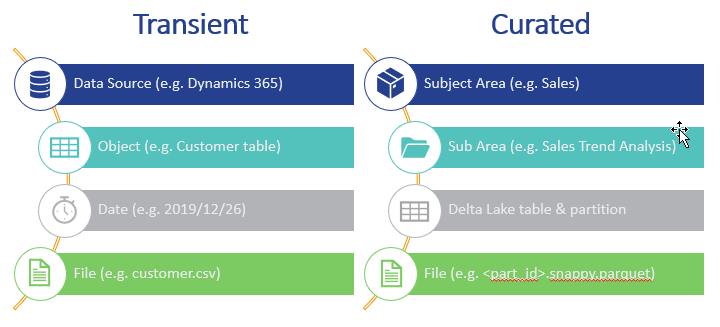
For the Transient and Persisted zones, this means that the structure is more closely aligned with the Data Source, whereas for the Curated and Experiments zones, it is aligned with the particular business Subject Area.
The examples below shows what the hierarchy in the Transient and Curated zones might look like.
We can now look at how we can apply these concepts utilising one of the rising stars in the Azure Data Platform suite of products, Azure Data Lake Store Gen2. Built on the solid foundation that is Azure Blob Storage, Microsoft has delivered a storage layer that performs just as well as traditional blob storage, but with the added benefit of Azure Active Directory (AAD) integration and a granular POSIX-style, Access Control Layer (ACL). You can read more about access control in ADLS Gen2 here. The documentation for ADLS Gen2 is pretty comprehensive, so I’ll let you work through that on your own time.
Disclaimer: I am not saying this is the only way to do things, but it is certainly a solid model which you can tweak for your particular scenario.
Firstly, we have to consider the number of storage accounts. The fewer the better in my humble opinion! Data Lakes are all about creating a central repository / hub for all organisational data, so by splitting this into multiple accounts, you could potentially create unintended silos downstream, hence I always start with a single account. Of course there are exceptions, e.g. a regulatory body that requires Personally Identifiable Information (PII) data for a certain country’s residents to be stored in that country. But generally speaking, the fewer the better!
That said, you always have to consider protecting and securing your data, so when I say one storage account, I mean one per “environment”, i.e. one for Development, Test, Production, etc. Unless you have a very specific requirement for which production data is essential, I would avoid having production data in lower environments! It may seem like a good idea, but a large chunk of data breaches come from non-production environments where security tends to be more lax.
So let’s build start building our data lake. First, we need an ADLS Gen2 account, to create this, you can follow these steps. Once you have your ADLS Gen2 account sorted, we can set up the zones. I create a separate file systems / containers for each zone.
So why not a single file system?
Well, if you look a the zone summary table, you’ll see that each zone has vastly different Governance and Access Control requirements. By defining separate file systems, I can use more granular ACL-based access control in the Curated and Experiments zone which is where the majority of end-user access is. In addition, it also reduces the risk of accidental access being granted to raw data in the Persisted and Transient zones. Separated by file system, yet kept together by a single storage account.
As you can see from the Azure Storage Explorer screenshot below, I have created four Blob Containers, which is the equivalent of an ADLS Gen2 file system.
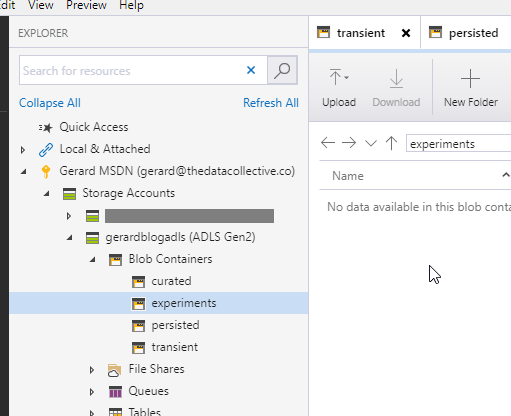
We can no proceed to create folders within these containers to represents the particular structure we need. Or, which is more often the case, we can let the ETL/ELT technology do this for us. In this series, this responsibility falls to Azure Databricks. We’ll explore exactly how this is done in the next post.
![]()