

I have read quite a bit about “the death of Big Data” recently. To be honest I’ve never liked the term Big Data. It has always skewed people’s thinking towards data volumes, and if you recall the original Big Data definition, i.e. the 3 Vs, Big Data never referred to just data Volume, but also Variety and Velocity.
Unfortunately Data Lakes have been dragged into the turmoil surrounding this topic. So with this series of posts, I’d like to eradicate any doubt you may have about the value of Data Lakes and “Big Data” Architecture. I’ll do so by looking at how we can implement Data Lake Architecture using Delta Lake, Azure Databricks and Azure Data Lake Store (ADLS) Gen2.
But first, let’s revisit the so-called “death of Big Data”. Though it is true that there are still a plethora of organisations that do not have to deal with large volumes of data, I can all but guarantee that most organisations have had to deal with one or both of other Vs. Let’s unpack this statement…
What does Variety mean?
Simply put, this just means data in different structures. This could take the form of:
Structured data typically the form of traditional relational databases behind line-of-business applications, such as CRM and ERP systems. But good old delimited text files also fits in this category.
Semi-structured data (typically machine generated) such as web logs or IoT sensors taking the form of JSON or XML files for example. Keep in mind that IoT does not always have to equate to big volume. Sometimes a sensor only provides a reading every 24 hours, that’s not volume, but it is still a different variety of data.
Unstructured data such as pdf documents, emails and/or tweets (typically human generated)
So you see, most organisations actually have Variety of data.
What does Velocity mean?
If your organisation has a “real-time” or “near real-time” requirement for data, what it’s really saying is that there is a requirement for data to be acquired and processed at a higher Velocity. Again, most organisations have near real-time requirements for at least some of its data.
So you see, Big Data is far from dead, although I would be quite happy to bury the name! That said, they say two of the hardest things to do in tech is cache management and naming things, so I will certainly not be proposing a more suitable name here. I have seen the term “All Data” being thrown around, though I’m not convinced by that either…
Now, let’s talk Data Lakes. Up until the release of Delta Lake (known as Databricks Delta prior to it being open-sourced by Databricks), Data Lakes had a number of challenges. For example:
Failed production jobs could leave data in corrupt state requiring tedious recovery
Lack of quality enforcement had the potential to create inconsistent and unusable data
Lack of transactions made it almost impossible to mix appends and reads, batch and streaming
Most of these could be overcome with some due diligence and good architecture (think Lambda for example), but the lack thereof led to bad implementations that turned many Data Lakes into Data Swamps, often rendering them useless!
To make matters worse some used technologies like Hadoop as a synonym for Big Data. Claims were made that Hadoop and other Big Data technologies will replace traditional Data Warehousing, which understandably had many up in arms.
There is also the school of thought that Data Lakes are nothing more than glorified persisted staging. This can be true when deliberately implemented that way, but it is a much more than that. More on this in subsequent posts in the series.
Let me be clear, I do not believe that Big Data was ever a replacement for Data Warehousing, but rather a compliment to Data Warehousing. I.e. the two concepts can and should happily co-exist.
Fortunately for us, technology never stops advancing and in its critical time of need, Data Lakes have been given a huge boost by combining three fantastic technologies to build truly “Reliable Data Lakes at Scale” - borrowing the Delta Lake tagline here.
The Delta Lake Marketecture (no that’s not a typo but a combo word for marketing and architecture) diagram below depicts a simplified data lifecycle through zones in the Data Lake.
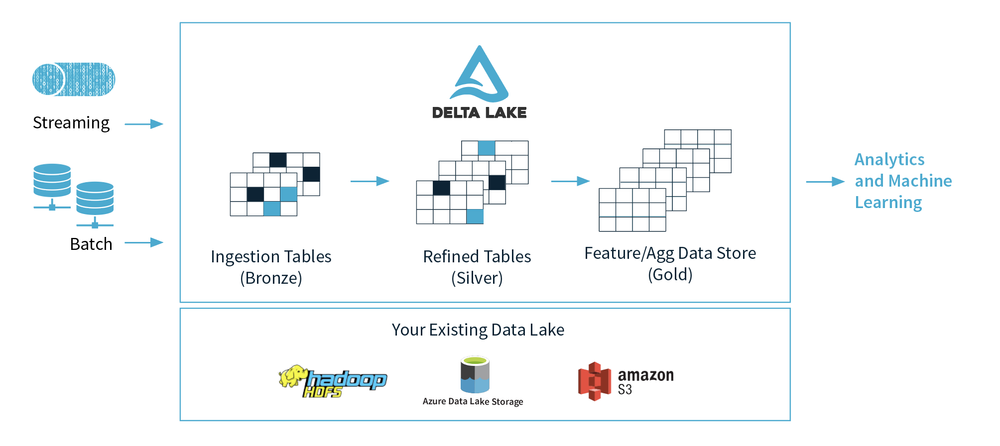
During this series, we’ll expand on this simplified diagram to bring the following to Data Lakes:
ACID transactions - Data lakes typically have multiple data pipelines reading and writing data concurrently. Delta Lake provides serializability, the strongest level of isolation.
Time travel - Data versioning to access and revert to earlier versions of data for audits, rollbacks or to reproduce experiments
Streaming and batch unification - A table in Delta Lake is a batch table as well as a streaming source and sink
Schema enforcement - Automatically handles schema variations to prevent insertion of “bad” records
Schema evolution - Changes to a table schema that can be applied automatically
Role-based access control - Security can be applied through AAD security groups or principals.
In my next post, we’ll explore the creation of quality Data Lakes using specifically Delta Lake, Databricks and ADLS Gen2. I’ll address things like single vs. multiple storage accounts, single vs. multiple file systems, as well as Data Lakes zones, their structures and how to secure them.
![]()