

This is the third and final post in a series that addresses how to use Azure Data Lake Store (ADLS) Gen2 as external storage with Azure Databricks. Unlike the previous posts in the series, this post does not build on previous posts, but I would suggest you still work through Part 1 and Part 2, so you have some context.
As we saw in previous posts in this series, there are currently four main options for connecting from Databricks to ADLS Gen2:
Using the ADLS Gen2 storage account access key directly
Using a service principal directly (OAuth 2.0)
Mounting an ADLS Gen2 filesystem to DBFS using a service principal (OAuth 2.0)
Azure Active Directory (AAD) credential passthrough
This post focuses on option 4; AAD credential passthrough
As the name suggests, using this method, the commands you run on the cluster will be able to read and write data in your ADLS Gen2 file system without the need of service principal credentials for access. It uses the credentials of the signed-in user instead, and applies the ACLs permissions assigned either directly to the user, or the group the user belongs to.
So for those of you who read Part 1 in this series, you’re probably asking why we would ever use option 2 if option 4 is available? The reason is that credential passthrough as it exists currently, has some constraints you need to be aware of:
You need a Databricks Premium Plan
It requires a High Concurrency Cluster, which only supports Python and SQL
Properly configured AAD tokens for your account such that any Azure Databricks users who read and write from ADLS Gen2 have proper permissions on the data they need access to. This is an Azure Databricks administrator task. For more details. see Enabling AAD credential passthrough to ADLS Gen2.
Because of these constraints, this may not be the optimal mechanism for data scientists as an example. Because in its current form, AAD passthrough authentication clusters would prevent them from using the Scala and R languages.
Right, so let’s get into it!
Before you continue, make sure you have granted your user account the appropriate ADLS Gen2 file system permissions. You do this the same way as for a service principal. If you’re not sure how, see Part 1 of the series for details.
N.B. AAD credential passthrough to ADLS Gen2 requires the Databricks Runtime 5.3 and above. I’m going for 5.5, which you may have noticed is now out of Beta, a week after my last post!
Given we need a high concurrency cluster with some special switches flipped, you won’t be able to re-use your cluster from Part 1 or Part 2. I used the configuration below for my cluster.
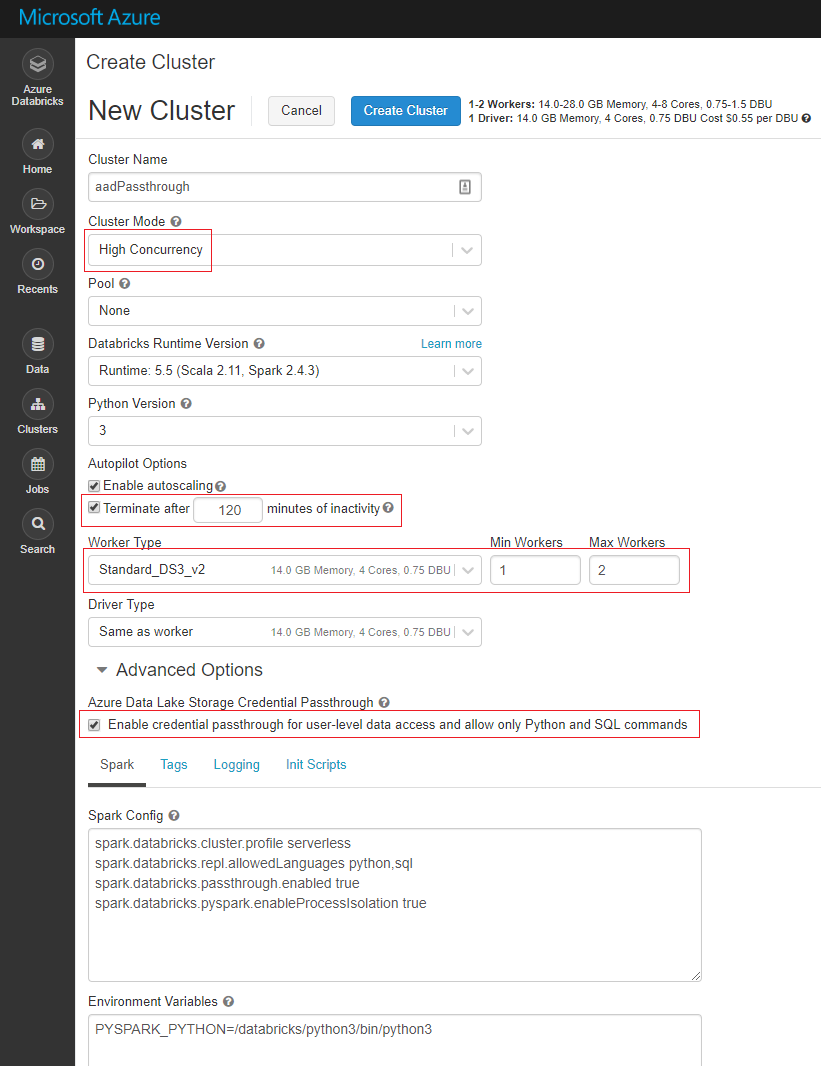
A few things to look out for here:
Make sure you flip the Cluster Mode setting to High Concurrency
High Concurrency clusters do not auto terminate like Standard clusters, so if you don’t want to get stung by costs of clusters that keep running after you’re done working, you may want to tick this Autopilot Option.
I’ve adjusted the Worker Type to a lower spec VM. The default compute nodes for high concurrency clusters are memory optimised, i.e. more pricey, which is perfect in the real world, not so good for PoCs and learning!
Make sure you tick the “Enable credential passthrough….“ box
Once your cluster is provisioned and running, create a new Python notebook and attach it to your cluster.
Once again we’ll use our trusty SampleFile.csv file, so ensure it’s uploaded to your ADLS Gen2 file system. As always, all samples are available in the blog GitHub repo.
N.B. Remember that you have to add the file after setting up the users access, or the file will not inherit the default ACLs
Now let’s set up some variables.
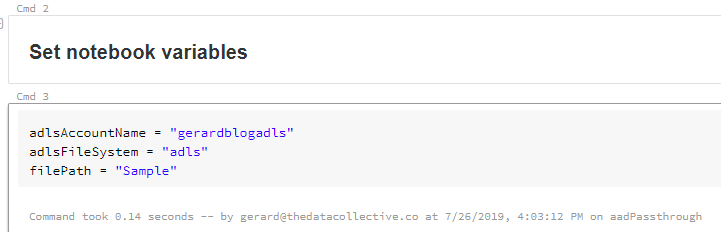
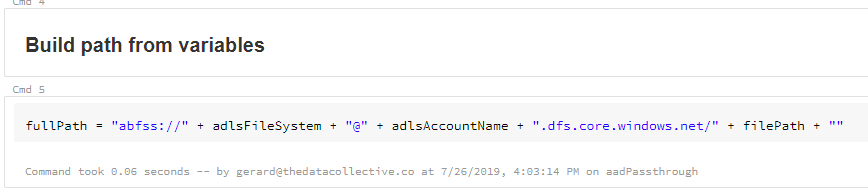
Next, we built the full path to the folder in or ADLS Gen2 file system.
All that’s left do now is read the file into a Databricks dataframe and display it.
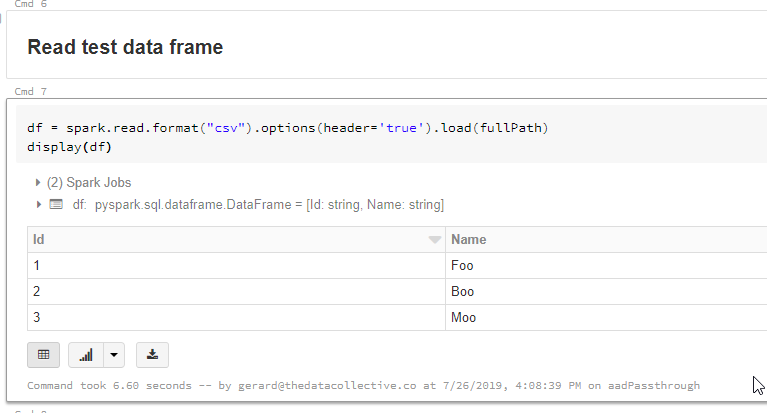
And that as they say, is that! Pretty simple really. This would be a no-brainer if it wasn’t for the constraints. That said, this is still by far the simplest and most secure solution, so definitely one to keep in mind.
This concludes the series of Connecting Azure Databricks to Azure Data Lake Store (ADLS) Gen2. In my next post, I’ll explore some good practices for building quality Data Lakes. I.e. what you need to do to avoid building Data Swamps!
Thanks for reading!
![]()