

When working in business intelligence, data engineering or data in general, there are some “mantras” that are being adopted by the larger community as “best practices”. For example, I shout “STAR SCHEMA ALL THE THINGS” anywhere I can, because a star schema is the most optimal way to design your model in Power BI. We also have Matthew Roche‘s Maxim of Data Transformation:
Data should be transformed as far upstream as possible, and as far downstream as necessary.
It basically means you should try to do a data transformation as early in the process as possible (for example in the SQL query selecting data from the source, or in the data warehouse), rather than in Power Query or in DAX. Only move it up into the chain if it’s not possible (for example a dynamic median calculation, which can only be done by a DAX measure).
In this blog post I’ll talk about another of those rules/mantras/patterns/maxims:
build once, add metadata
I’m not sure if I’m using the right words (metadata-driven framework is also a good name), I heard something similar in a session by Spark enthusiast Simon Whiteley. He said you should only write code once, but make it flexible and parameterized, so you can add functionality just by adding metadata somewhere. A good example of this pattern can be found in Azure Data Factory; by using parameterized datasets, you can build one flexible pipeline that can copy for example any flat file, doesn’t matter which columns it has. I have blogged about this:
You build your pipeline once, and if you want to add another flat file, you just enter some metadata into table.

You can do the same when loading data from a database: you just keep track of a metadata table (or you can just use INFORMATION_SCHEMA.TABLES if the source database supports it) and you loop over it to fetch the data of all those tables.
The pattern has become more popular with the “rise of data engineering”, because it typically involves more code and it’s easier to do such things when you can write code around it. But if you think about it, we’ve been implementing this pattern for quite some time. A few examples:
- In SSIS, we used the BIML language to get around the fact that a data flow could only support one source (for example one Excel file, one table, one flat file …) because the metadata was fixed. So we wrote some BIML to generates multiple SSIS packages from the same template.
- At the start of my career, I wrote a data pump, which was the combination of .NET and dynamic SQL. You enter some metadata in a table about the source you want to load, and the solution would load it into a staging table.
- A few years back, I wrote a code generator for a data vault solution. Typically, in a data vault you have a layer called the “raw vault”, which is just your source data being forced into the data vault schema. Very easy to generate since it’s always the same patterns. You enter some metadata into a table or an Excel file, and the source would be loaded into the raw vault.
- I had a whole bunch of Logic Apps transferring data from SharePoint lists to a SQL database. It grew organically over time. First you only have one Logic App because you only needed data from one list. Then another list was added, so I just cloned the Logic App, made some changes and I was done. And then another, and another, and so on. The development work didn’t cost me much time, but CI/CD pipelines were getting longer (this things deploy so slow). So I parameterized one Logic App, added a metadata table and I used ADF to inject that metadata into the body of the HTTP trigger of the Logic App. This way, I reduced my Logic Apps from over 30 different apps, to about 4.
- Loading data into a data warehouse staging area was already automated, but loading dimensions and facts was still done by hand. But why? The principle of loading a dimensions is always the same: check if a row is an insert or an update, and act accordingly (with slowly changing dimensions type 2 there are a couple of extra steps involved of course). With a fact table it’s often even easier: just truncate the table and reload. Or delete some part if it’s incremental and then reload that part. The tricky part is that in contrast with loading staging data – which is typically just a 1-to-1 copy of the source – loading a dimensions or fact involves business logic. So I encapsulated all that logic in views, and then load all my facts and dims from those views.
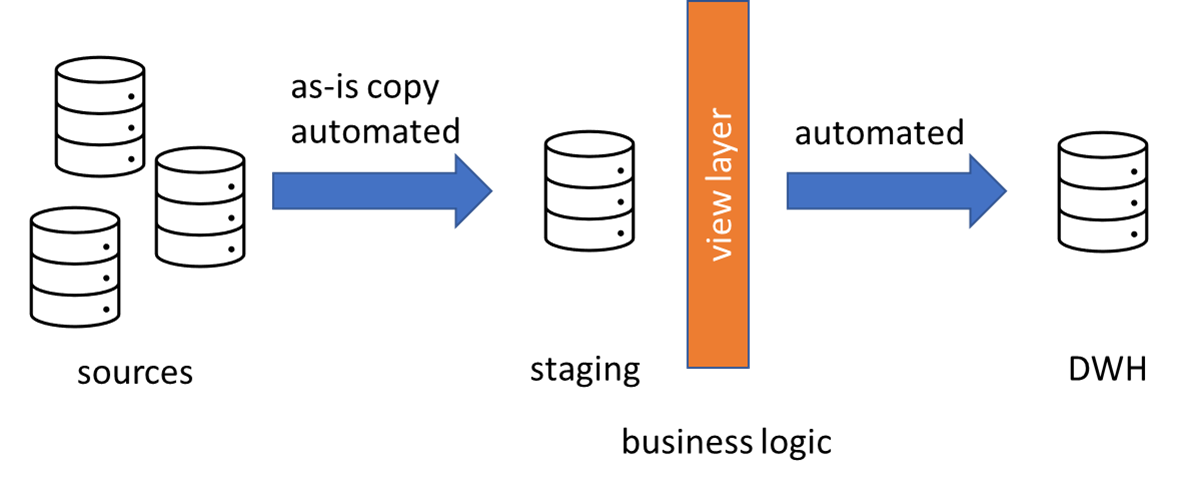
So what is the point of this blog post? First, to point out the obvious time savings you can have after you’ve wrote your solution. Want to load an extra flat file, just add a line into a table and start your pipeline. Done. Second, when you automate a pattern, you’re 100% sure data is going to be handled in always the same way. No exceptions, and thus easier to debug. Also, when you want to make a change, you can do it in one single place, instead of updating multiple packages/procedures.
Take a look at your data pipelines and your data warehouses, and ask yourself if you’re writing code that often looks the same. Maybe it’s a good opportunity to automate something. Thoughts? Let me know in the comments!
The post Build Once – Add Metadata first appeared on Under the kover of business intelligence.