

When you are analyzing data, you will want to know as much as possible about your data. Getting to know your data requires running statistical functions and measures. Such are minimum and maximum values, average values, distributions, correlations, statistical significance and many others. In reality, when looking at data in your database, you will, regardless of referential integrity, constraints and foreign keys, come to the point, where you will have to deal with unknown or missing values, outliers and any other undesired values. And all this values will have an effect on your data. This process, where you are detecting, finding and recoding these values, is known as data cleaning. And if you do not do proper data cleaning, your results might be skewed or wrong both leading to false interpretation.
Statistics in SQL Server
How do you start your data cleaning? SQL Server provides several statistical functions. You can use them in your queries when exploring the data. These are primarily built-in functions, such as mathematical (ABS, COS, SIN, EXP, LOG, PI, SQRT, etc.), aggregate (MIN, MAX, AVG, SUM, COUNT, VAR, VARP, etc.), ranking (RANK, NTILE, DENSE, etc.) and string functions (SOUNDEX, DIFFERENCE, STUFF, REVERSE, etc.). Built-in functions are very simple to use and can help construct any further statistical functions such as mean, modus, median, running frequencies, descriptive statistics or any other test such as t-test, chi-square, etc. Both, built-in and constructed functions, will help you understanding the data through cleaning the data. In addition, to support process of data cleaning, SQL Server provides very good algorithms for data profiling within SSIS and many other approaches on understanding data (fuzzy, deduplications, outlier detections, etc.).
When you are working with SQL transactional tables or fact tables and your goal is to e.g.: understand variables or values and their relations to other variables or values. For example, understanding customer business entity and number of cars owned (as shown later on AdventureWorks sample), you will need to run general statistics such as MIN and MAX to search for any outliers. In addition, you will need to run frequency table to see the distribution of values. Furthermore, calculate descriptive statistics (such as mean values), variance (VAR and VARP), and many others. Such analyzing can be time consuming when preparing long T-SQL code, and will even become longer when running statistical test, data standardization, and any bivariate or multivariate statistics.
Focus of this article will be using your SQL server data and getting simple statistics using program R.
Introducing R
R a language and software environment for statistical computing and graphics. It is an open source statistical program and free of charge. It can be downloaded from official R web site (http://cran.rstudio.com/) or any mirror site. For first time R users, good documentation is available online (http://cran.rstudio.com/manuals.html)
It is an easily adaptable program and full of useful libraries for performing different statistical analysis. Also several libraries are available for connecting to database engines, Excel or other programs. The R community is growing bigger every day and many websites are available for learning R.
The decision to use R for the purpose of data exploring is easy. My main reason is price. Also, it is very powerful program, easy to use and it is gaining popularity in community, especially among statisticians. Not to be misunderstood, R is not a database engine as SQL Server.
I have seen statisticians exporting data from SQL Server to third party programs, such as SAS, SSPS, R, STAT, Excel, etc., on daily basis in order to calculate statistics against their data. It was a time consuming and long lasting process. Therefore, I have developed a procedure called sp_getStatistics, which effectively does just that. It (1) feeds the data from your SQL Server source table and (2) performs defined statistics in R and (3) return results back to the SQL server.
Installing R and preparing your environment
Installing R is safe and straightforward. First download the executable R installation file from the official R website (http://cran.rstudio.com/). I am running R base for Windows (64 bit), version 3.0.2, available here: http://cran.rstudio.com/bin/windows/base/R-3.0.2-win.exe. The documentation for the Windows installation is available here: http://cran.rstudio.com/bin/windows/base/README.R-3.0.2.
Once installation is completed, you will have the R engine installed on your computer. The usual installation path is: C:\Program Files\R\R-3.0.2\bin, but it might vary depending on your R version and your operating system. This completes the R installation.
After that, you will need to run both enclosed SQL files (see the Resources section below). These will create a proper SQL Server configuration, data sample (available in file 01_Configuration_and_data_preparation.sql) and procedure sp_getStatistics (available in file 02_Create_Procedure.sql). In the following section everything will be explained in details, as well as the structure of procedure.
Configuring SQL Server
Before we start the procedure, let’s check if we have everything on your client. You should have the following:
- Instance of the SQL Server
- Installed Project R for statistical
- Read/Write permisson on working folder for the R files; path and name of working directory are defined by the user.
The Instance of SQL Server must have enabled:
- XP_CMDSHELL using SP_CONFIGURE
- Ole Automatic procedures using SP_CONFIGURE
The following code must be executed to enable these two settings:
EXECUTE SP_CONFIGURE 'show advanced options', 1 GO RECONFIGURE; GO EXECUTE SP_CONFIGURE 'xp_cmdshell', 1; GO RECONFIGURE; GO EXECUTE SP_CONFIGURE 'Ole Automation Procedures', 1; GO RECONFIGURE; GO
Data preparation
In this step you will query your data into new table or create a view against existing fact table. Basically, just follow your usual work on querying data. For the purpose of this article, I will create a new table using the AdwentureWorks2012 database.
This query will create a subset of the data for demonstration purposes.
USE AdventureWorks2012; GO SELECT BusinessEntityID ,ISNULL(Gender,'U') AS Gender ,ISNULL(TotalChildren,0) AS TotalChildren ,ISNULL(NumberCarsOwned,0) AS NumberCarsOwned INTO vPersonDemographics FROM Sales.vPersonDemographics; GO
I have created the table, called vPersonDemographics (for purpose of this article). Against this table, I will run different statistics to explore the data.These statistics will be descriptive statistics (descriptive statistics are describing your data using minimum, maximum values, mean values, median, modus, standard deviations, …), frequencies, cross tabulations (similar to pivot table), and chi-square test.
For now, run a simple SELECT statement to see and understand data in the table vPersonDemographics. With following query I will confirm, I got the right data in my table.
USE AdventureWorks2012; GO SELECT TOP 10 * FROM TK_vPersonDemographics; GO
And ten rows are shown as following.
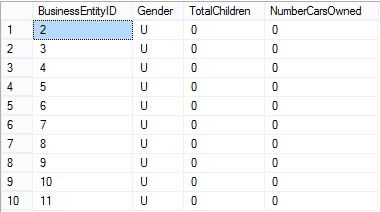
Figure 1: Sample from table vPersonDemographics showing all columns / variables for later analysis.
The results are:
- BusinessEntityID is incremental ID for each of the customers in my data set (type: integer)
- Gender is denoting customer gender; U – unknown; M – male and F – female.(type: char)
- TotalChildren is denoting number of children in customer household. (type: integer)
- NumberCarsOwned is denoting number of cars owned in customer household (type: integer).
At this stage, I still have not run any descriptive statistics using T-SQL, so I might have extreme values (e.g.: TotalChildren 999 – which we know is an error), or I might have missing values in my table. I will let the procedure sp_getStatistics explore the data for me.
Procedure parameters
Procedure accepts seven input parameters and returns statistics on desired columns / variables that are calculated in R environment and displayed in SSMS.
Input parameters
- @TargetTable – is a T-SQL table holding data for statistician will need to analysis. In previous step we have created a subset of the data that will represent our target table.
- @Variables – is/are column/s or variable/s (as seen in Figure 1) from the table defined under input parameter @TargetTable
- @Statistics – is the valueID of the statistics defined in table dbo.tableStatistics. I will later return to this table explaining the essence.
- @ServerName – is the name of the SQL Server name running on the client machine; on the same machine where the R environment is set.
- @DatabaseName – is the name of the SQL Server database on server defined under @ServerName
- @WorkingDirectory – is the name of folder (including path name) on the client machine for the SQL Server to store created R scripts and for program R to store all the exports.
- @RPath – is the path on client machine to the file R.exe; executable file to start R.
Restrictions on parameters
There are a few restrictions on the parameters, which I've listed below. First, the @TargetTable can only be one table. It cannot be multiple tables. For the demonstration purposes, I have used relatively small and narrow table with some 20000 rows. If the target table is a large table with millions of rows, execution times will be greater.
The @Variables can hold one or more column names (or simply variable names), separated with comma. Some of the statistics use only one variable, hence the order of variables in this parameter is also important and taken into consideration.
@Statistics are available in table dbo.tableStatistics which is created and generated in runtime. See Figure 2 for the contents of the table.
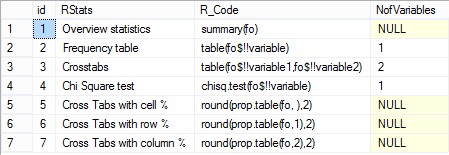
Figure 2: Content of table tableStatistics
This table holds information on statistics and actual R code. Statistics in the table can be changed by statistician or any developer familiar with R code.
The table has a simple structure:
- Column ID is auto increment number and denotes ID of each statistics
- Column RStats is description for each of the statistics
- Column R_Code is actual R code used for dbo.sp_getStatistics procedure to communicate and extract statistics from R environment. In this column you can change the R code for your needs. Or you can add additional statistics. Please note, that following nomenclature is used when single or multiple variables are used:
- !!variable in case of statistics with single input variable
- !!variable1, !!variable2, !!variable3 in case of statistics with multiple input variables. Order of the variables is applied as passed in parameter @variables.
- Column NofVariables is an integer of variables needed for each statistics to be efficiently executed. If no integer is set, statistic uses the whole dataset for statistical analysis.
@ServerName can hold only one server name. This version of procedure does not support linked server connections. Also, @DatabaseName can hold only one database name with or without schema name.
@WorkingDirectory is the full path to folder for storing working files and final output files. User executing procedure must have permission for creating folder in desired path. When entering path, one can exclude last backslash; e.g.: “C:\DataForProcedure\” should be “C:\DataForProcedure”
@RPath is full path where R.exe is stored. Path is slightly different if you are running R in 32bit version or in 64bit version. Also some problems might occur when installing additional libraries in R, that one must change setting in R environment to find the library (e.g.: library RODBC).
Procedure is executed with the following code:
USE AdventureWorks2012; GO EXECUTE AdventureWorks2012.dbo.sp_getStatistics @TargetTable = 'vPersonDemographics' ,@Variables = 'TotalChildren,NumberCarsOwned' ,@Statistics = '3' ,@ServerName = 'DevSQL2012' ,@DatabaseName = 'AdventureWorks2012' ,@WorkingDirectory = 'C:\DataTK' ,@RPath = 'C:\Program Files\R\R-3.0.2\bin\x64'; GO
Structure of the procedure
The structure of the procedure has three major parts. The first part is checking the existence and validity of the input parameters. The second part is generating the R script and last part is printing back the R results in Management Studio.
Checking validity of values in input parameters
Validating input values represents a huge chunk of T-SQL code in the procedure. Valid parameters are mandatory for correct execution. Therefore, I will go through all of them.
First, each variable must be declared. The first part of procedure is checking if the parameter was declared. This part of the procedure will check if the input parameters were declared.
-- @TargetTable IF (@TargetTable = NULL OR @TargetTable = '') BEGIN PRINT 'Please Define variable @TargetTable' RETURN -1; END; -- @Statistics IF ( NOT EXISTS (SELECT * FROM dbo.tableStatistics where ID = @Statistics) OR (@Statistics = NULL OR @Statistics = '') ) BEGIN PRINT 'Please define statistics correctly. Check table of available statistics.' RETURN -1; END; -- @WorkingDirectory IF (@WorkingDirectory = NULL OR @WorkingDirectory = '') BEGIN PRINT 'Please define your working directory in variable @WorkingDirectory' RETURN -1; END; -- @RPath IF (@RPath = NULL OR @RPath = '') BEGIN PRINT 'Please define path to R program in variable @RPath' RETURN -1; END; IF (@ServerName = NULL OR LEN(@ServerName) = 0) BEGIN PRINT 'Please define server name.' RETURN -1; END IF (@DatabaseName = NULL OR LEN(@DatabaseName) = 0) BEGIN PRINT 'Please define database name.' RETURN -1; END
Input parameters such as the R path and path to working directory use following chunk of code for validation.
-- @WorkingDirectory IF (@WorkingDirectory <> NULL OR @WorkingDirectory <> '') BEGIN DECLARE @test INT DECLARE @SQL_CMD VARCHAR(100) SET @SQL_CMD = 'EXEC xp_cmdshell '' IF NOT EXIST '+@WorkingDirectory+' MD '+@WorkingDirectory+' '' , NO_OUTPUT'; EXEC (@SQL_CMD) IF (@test = 0) BEGIN PRINT 'Directory not exist or no access' RETURN -1 END END -- @RPath IF (@RPath <> NULL OR @RPath <> '') BEGIN CREATE TABLE #temp_RPath ( Exist_File TINYINT ,Exist_Dir TINYINT ,Exist_RootDir TINYINT ) DECLARE @RPathINT VARCHAR(200) SELECT @RPathINT = REPLACE(@RPath,'"','') INSERT INTO #temp_RPath EXECUTE [master].[dbo].XP_FILEEXIST @RPathINT IF (SELECT Exist_Dir FROM #temp_RPath WHERE Exist_Dir = 1) IS NULL BEGIN PRINT 'R Path folder does not exist or folder name is wrong' RETURN -1 END DROP TABLE #temp_RPath END
Finally, the procedure will check for validity of the server and target table with column (variables) names, both as input parameters.
IF (@TargetTable IS NOT NULL AND @TargetTable <> '') BEGIN IF ( OBJECTPROPERTY ( object_id(@TargetTable),'ISTABLE') = 1 OR OBJECTPROPERTY ( object_id(@TargetTable),'ISVIEW') = 1 ) BEGIN DECLARE @varItem SMALLINT = 1 WHILE (SELECT MAX(id) FROM @Variable_list) >= @varItem BEGIN DECLARE @VariableInt VARCHAR(100) SELECT @VariableInt = item FROM @Variable_list WHERE @varItem = id IF COL_LENGTH(@TargetTable,@VariableInt) IS NULL BEGIN PRINT 'Column '+ @VariableInt +' does not exist or access denied to view the object' RETURN -1 END SET @varItem = @varItem + 1 END END END IF (@ServerName <> NULL OR LEN(@ServerName) > 0) BEGIN DECLARE @server NVARCHAR(50) SELECT @server = CONVERT(sysname, SERVERPROPERTY(N'servername')) IF @serverName <> @server BEGIN PRINT 'Bad server name or name does not exist' RETURN -1 END END
Generating R script
Generating the R script is next huge part of the procedure. In first part, the R logic is added to T-SQL. This part includes testing for existance of library, opening ODBC connection.
DECLARE @WorkingDirectoryR VARCHAR(50) = REPLACE(@WorkingDirectory, '\','/')
DECLARE @ServerNameR VARCHAR(50) = REPLACE(@ServerName,'\','\\')
DECLARE @SQL_EnvironmentR VARCHAR(1000)
DECLARE @QueryStmt VARCHAR(8000)
SET @QueryStmt = 'SELECT ' +@Variables+ ' FROM '+ @TargetTable
SET @SQL_EnvironmentR = 'setwd("'+@WorkingDirectoryR+'")
#install.packages("RODBC")
#library("RODBC")
if(!is.element("RODBC", installed.packages()))
{install.packages("RODBC")
}else{library("RODBC")}
con <- odbcDriverConnect(''driver={SQL Server};server='+@ServerNameR+';database='+@DatabaseName+';trusted_connection=true'')
fo <- sqlQuery(con, '''+@QueryStmt+''')
out<-capture.output(';The following part is defined by the user through input parameter @statistics. Based on value in parameter, different statistics will be used.
DECLARE @Stat VARCHAR(100) IF @Statistics = '1' BEGIN SELECT @Stat = R_Code FROM dbo.tableStatistics WHERE id = @statistics SET @SQL_EnvironmentR = @SQL_EnvironmentR + @Stat; END IF @Statistics = '2' BEGIN DECLARE @varItem_stat2 SMALLINT = 1 DECLARE @var_stat2 VARCHAR(100) WHILE (SELECT NofVariables FROM dbo.tableStatistics WHERE id = @Statistics) >= @varItem_stat2 BEGIN SELECT @var_stat2 = item FROM @Variable_list WHERE id = @varItem_stat2 SELECT @Stat = REPLACE(R_Code,'!!Variable',@var_stat2) FROM dbo.tableStatistics WHERE id = @statistics SET @SQL_EnvironmentR = @SQL_EnvironmentR + + @Stat; SET @varItem_stat2 = @varItem_stat2 + 1 END END
For example, input parameter @statistics is set to 1. This means, that the R statement stored in table dbo.tableStatistics will be used for this parameter (as shown in Figure 2.)
The last part of generating the R code is closing the ODBC connection.
SET @SQL_EnvironmentR = @SQL_EnvironmentR + ') cat(out,file="'+REPLACE(@workingDirectory,'\','/')+'/output.txt",sep="\n",append=TRUE) close(con) ';
When concatenated together and stored in R file, the R script looks as following:
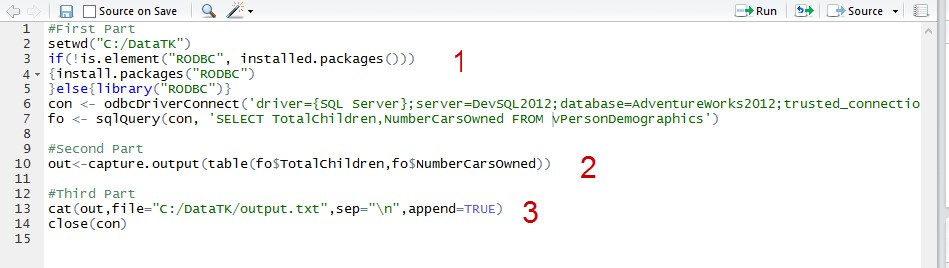
Figure 3: R script for execution of statistics against SQL Server table. Printscreen taken in R environment (RStudio – available for download at: www.rstudio.com).
The first part is header information with setting the working folder where the R files will reside. Next the script will check if RODBC library is already present on client machine; if not, it will install it. Once RODBC library is set, odbcDriverConnection can be called to pull data from MSSQL table to R environment (memory) with a direct T-SQL statement.
Second part is the only dynamic part, where R code is fed from table dbo.tableStatistics stored under R_Code. With R Code all the needed variables are also merged and passed to concatenation of R script.
The third part is mainly just telling R to store export to file and to release/close ODBC connection to SQL Server.
Printing the R results
Printing the results from R to SQL Server Management studio is done with the help of extended stored procedures. The results from R are stored in text file and simply printed in management studio for easier usage.
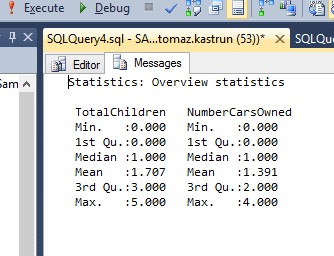
Figure 4: Printing results in SSMS
This section is showing the use of extended procedures for purposes of printing the R results (I set to store the R results in text file) in Management studio for ease and convenience. I have used already available sample on MSDN BOL and sample from Simple talk.
-- SAMPLE Available ON MSDN BOL -- SAMPLE Available: https://www.simple-talk.com/sql/t-sql-programming/reading-and-writing-files-in-sql-server-using-t-sql/ DECLARE @FS INT, @FileId INT, @hr INT, @End INT DECLARE @FileName VARCHAR(1000) = @workingDirectory + '\' + 'output.txt' DECLARE @Chunk VARCHAR(8000) DECLARE @String VARCHAR(MAX) ='' EXECUTE @hr = SP_OACreate 'Scripting.FileSystemObject', @FS OUT EXECUTE @hr = SP_OAMethod @FS, 'OpenTextFile', @FileId OUT, @FileName, 1,false,0 WHILE @hr=0 BEGIN IF @HR=0 EXECUTE @hr = sp_OAGetProperty @FileId, 'AtEndOfStream', @End OUTPUT IF @End<>0 BREAK IF @HR=0 EXECUTE @hr = sp_OAMethod @FileId, 'Read', @chunk OUTPUT,4000 SELECT @String=@string+@chunk END EXECUTE @hr = sp_OAMethod @FileId, 'Close' EXECUTE SP_OADestroy @FileId PRINT @String END
Results are part of R script and in case of any changes (captions, number precisions, etc.) one must alter R script.
Conclusion
Procedure is a simple, yet effective step towards collaboration of R and SQL Server. In this article I have demonstrated how simple statistics can be executed in R environment. Statisticians, and data analysts can both benefit using this procedure without leaving the comfort zone of Management studio (SSMS). The Usage can be heavily extended by adding more and more statistics (from simple to more complex) or by simply changing the procedure to serve any other multivariate statistical usages.
Data cleaning and data exploration processes will always be an important step when analysing data. Using this procedure, you can use the powerfull R language. But one must, prior to exploring the data, be familiar with business flow and business model.
Author: Tomaz Kastrun (tomaz.kastrun@gmail.com)
Twitter: @tomaz_tsql