

SQL Server users are accustomed to the relative ease with which they can get data from, and send data to, other databases systems. This article aims to answer the question of whether there are any problems of data interchange with MongoDB. In doing so, it discusses the different requirements for interchange, and appropriate methods.
ODBC
SQL Server has always thrived on its ability to share data with a whole range of different databases and data services. The ODBC and JDBC standards have been important in making this happen, and even now, over 25 years later, it is still an impressive way of achieving database connectivity. Basically, it allows databases to communicate with other databases and applications by providing a standard translation layer that behaves like a standard SQL ANSI SQL-92 database. ODBC also provides a standard discovery interface that enables the source to determine the capabilities and metadata of the target. A good driver can be obtained to access almost any major application, such as Google Analytics, Oracle, Jira, Paypal, Facebook, PostgreSQL or MongoDB.
Therefore, the seasoned database developer will reach naturally for ODBC, as the most obvious way of sharing data with MongoDB. You declare the MongoDB database as a linked server, and you can then access it and write to it as if it were a SQL-92 database. This will work, but you are losing something by the very fact that a collection of MongoDB documents, within a database, can have embedded objects and arrays that must somehow be normalised. The normalised form of the hierarchical data isn’t necessarily obvious, and the driver may well need help to provide the best schema. Although MongoDB supports joins, they aren’t fast, and it is asking a lot of a driver to bridge the divide between document and relational representations of data. There are good commercial ODBC products available for MongoDB, but they are generally very expensive. The free or cheap drivers consume more time and effort to get them to work.
Third-party tools
In the past, I’ve used various third-party tools for Mongo/RDBMS transfers, including RazorSQL, Talend, Kettle and SSIS. I now use Studio 3T, and must declare an interest here because I write occasional articles for them. Studio 3T is the nearest equivalent in functionality to SSMS in the MongoDB sphere, and also takes care of the conversion and mapping between relational tables and documents as part of the migration process, in either direction between SQL and MongoDB.

If you choose to migrate data from SQL to MongoDB, your selected tables will be created as import units. By default, each table is mapped to a collection with the same name and all the columns in the table are included as top-level fields in the new MongoDB collection, each with the most appropriate data type as detected from the original SQL type. A range of mapping options such as one-to-one or one-to-many relationships are customisable using the mappings editor. You can choose to migrate the whole database or just selected tables and the operations tab in the bottom left of the GUI reports on success or failure of the migration.
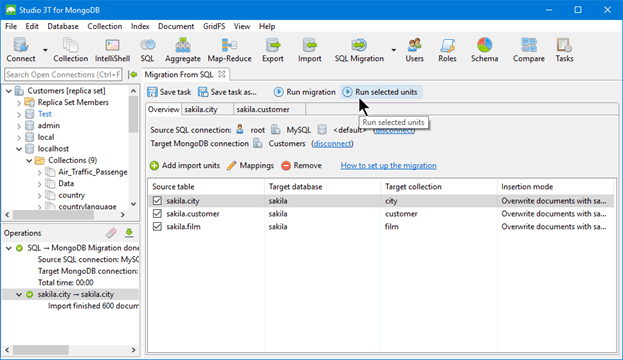
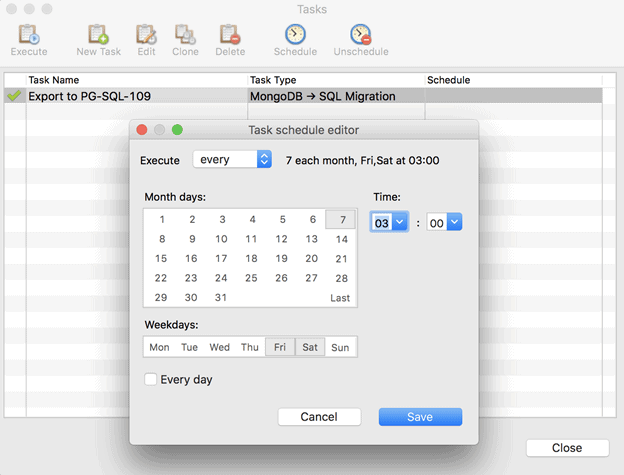
You can also save migration configurations to be executed later, either to or from MongoDB. Studio 3T also comes with its own scheduler that runs within the application, whenever the IDE is live. Long-running tasks such as large weekly or monthly data migrations can be set up to run at times when impact on server performance is non-critical.
File-based document transfer
Where the data is naturally tabular, file transfer can be via CSV. If not, it must be via JSON.
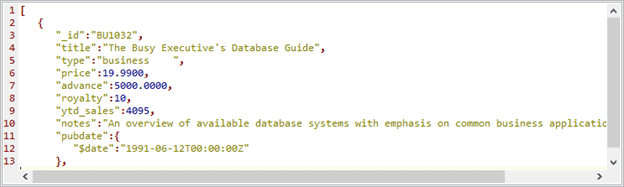
MongoDB uses a binary format of JSON called BSON as its database data storage layer. Out of necessity, it has a wider range of types than JSON, and so this data can be most successfully represented by ‘extended’ JSON, where the datatype is represented in JSON. MongoDB provides two different forms of Extended JSON for data transfer, canonical and relaxed. It also exports collections, which correspond to the BSON storage collections, as JSON. When it does so, it adds the type information as JavaScript. This ‘shell’ format is incompatible with the JSON standard.
Extended JSON defines the datatype, along with the value, when the datatype isn’t obvious. This can add another third to the size of the data, but it is thereby safe to use for relatively unstructured data. Its main advantage is that it can be read by any system that can read standard JSON, because the data type information is recorded in JSON.
It is important to be clear about datatype in JSON. If you import into MongoDB a JSON collection that includes a date then, unless it is done as Extended JSON, it is interpreted as a string because JSON has no standard way of representing a date. This is OK until you want to sort documents according to date, and then it is tricky. Also, if you want to index by date, you are lost. There are many differences between a decimal number and a floating-point number, as you would soon find out if you try using floating point for financial calculations! If you store binary information, you need to retain the encoding information with it. Datatypes really matter.
REST Interface
This can be set up for a direct import of MongoDB data from SQL Server or via scripting. It is possible to set up a rest interface for SQL Server that provides data as JSON. One can also call a REST interface from SQL Server. The drawback of both this approach, and the file-based document transfer, when compared to using ODBC, is the extra complexity of converting the JSON into a table format, for consumption in SQL Server. Where this is likely to be a problem, as when you are doing a lot of ad-hoc queries, then an ODBC driver is going to be less frustrating. However, using a REST interface has many advantages in a microservice setting, where several different databases and applications will be requesting data from SQL Server via REST, as JavaScript.
CSV with headers
CSV is feasible and practical for importing data into MongoDB where the data is basically tabular, especially since the datatypes as well as the key values can be specified, by being held in the header line. MongoDB can export information that is basically tabular, in the same CSV format, but without the type information in the header line, though you must specify the fields in the documents to export. Frustratingly, the problems with using CSV for transfer of data are more likely to be found when inserting data into SQL Server, due to SQL Server not directly supporting the CSV format. As well as being unable to import CSV, SQL Server is, unsurprisingly, also unable to export CSV with or without the special header lines.
Scripted data transfer via drivers
Where a script language has drivers for both MongoDB and SQL Server, it is relatively painless to script a transfer process. This is particularly appropriate where you require a transfer to be repeated regularly on a schedule. Python and PowerShell are popular choices for this. I use the DOS command line often to do this sort of work, because the MongoDB utilities work better with this than they do with PowerShell. The MongoDB utilities Mongo, MongoDump, MongoRestore, MongoImport, MongoExport, MongoStat, MongoTop, MongoPerf and MongoReplay are essential parts of MongoDB functionality, if you aren’t using an IDE such as Studio3T.
Issues
There are certain issues that you need to tackle before you can home in on the transfer method that meets your needs:
- Although a MongoDB collection can correspond to one or more relational tables, it doesn’t have to. It can be entirely schema-less, or even to be equivalent to two or more unrelated tables superimposed. You cannot always guarantee a translation. This is less likely with business objects, such as invoices, as they tend to have an inherently tabular structure. Creating a table in MongoDB is relatively easy if the collections used are consistent in the naming of keys. Here a schema validation can help. The only possible issue is dealing with rows that have null values in them.
- The choice of approach depends very much on whether the the transfer process is a one-off or needs to be run regularly. For the former, it is difficult to beat the third-party tool, but for a regular transfer, you are likely to need some sort of scripted approach that can be put on Chron or the Windows scheduler.
- For the data person in any organisation, data validation is a major concern. It is far better to detect and alert on any data that is wrong, before import. Any transfer process is a good place to check for data corruption, data out of sequence or data that does not conform to specification. It pays to be able to run validation. JSON provides a workable schema validation All that is required beyond the JSON file itself is a JSON schema file that has the metadata and constraints in it. Basically, it can tell you whether the file is likely to meet all the constraints of the table, though it cannot duplicate the constraints directly. It is possible to produce a basic schema validation document from the SQL Metadata using a stored procedure
- Where should the translation from the relational representation of the data to document representation take place: in SQL Server, in the transfer process or in MongoDB? All three can be used with varying difficulty. There is no ‘royal road’ here, the best place to do the transformation of the data depends on the strategy you use.
- The use of a primary key can be a complication. Generally, relational database tables have either a primary key or a unique constraint. Without them, you can’t easily retrieve a unique row. MongoDB collections are built with a clustered index. By default, this is just a random object_id. This loses a wonderful indexing opportunity, because a clustered index is usually an ideal candidate for a primary key. If you import a tabular database into MongoDB, it will work surprisingly well if you index the database properly, and by creating meaningful clustered indexes, you create a free and appropriate index for every table
Of these issues, the most difficult to give guidance for is the issue of where the translation to and from JSON to Relational should take place, and my advice would change over time. There was a time when SQL Server had no built-in way of dealing with JSON at all. Until SQL Server had its own JSON support, the production and manipulation of a JSON file tended to be an untidy wrestle with SQL Server’s recalcitrant and vengeful XML support. Now it is remarkably simple. If a query in SQL can describe the contents of a hierarchy, then a simple hierarchical JSON document can be created by adding the FOR JSON AUTO clause. You can also achieve a hierarchical document more precisely by using nested queries that provide JSON strings, using FOR JSON PATH.
Until MongoDB introduced the $lookup operator, it could not convert tabular collections into hierarchical collections. Now, it is possible to import tables into collections in MongoDB and then use the ‘$lookup’ aggregation pipeline operator in one or more stages of an aggregate function to create a hierarchical collection.
You can avoid any sort of transformation in the transfer process now by Importing SQL Server tables directly into a collection. This can be done by exporting them from SQL Server as extended JSON and importing them with MongoImport. Extended JSON is readable JSON that conforms to the JSON RFC, but which introduces extra key/value pairs to each value that defines the datatype. It can be read by any process that can consume JSON data but can be understood only by the MongoDB REST interface, MongoImport , Compass, and the mongo shell. The important common datatypes are all there, but there are also several data types that are only relevant to MongoDB and are used for transfer between MongoDB databases. You can provide a good choice for a clustered index if you check whether there is a primary key based on one column and if so, define that as the MongoDB key by using the reserved label ‘_id’. I have a stored procedure that exports extended JSON
Conclusion
It is surprisingly easy to pass data between SQL Server and MongoDB. SQL Server is well-placed to work in organisations that have a range of databases to suit diverse requirements. When planning a strategy for data interchange, it pays to look hard at precisely what is needed because there are a range of alternative strategies. A tool that is perfect for ad-hoc, or one-off requirements may be useless for scheduled ETL. A method that is strictly tabular may be inappropriate where the general ‘lingua franca’ of data exchange is JSON. Data transfer may be at a transactional level, or it could require the copying of entire databases. Every requirement seems to have its own nice solution.
The range of methods of interchange between SQL Server and MongoDB just reflects the range of different requirements and the health of the demand for using the two database systems, MongoDB and SQL Server, together.
References
- How to Create a MongoDB Collection Directly from SQL Server
- SQL Server to MongoDB Data Transfer Using Extended JSON
- MongoDB and SQL Server: Communicating via REST Service
- Setting up a simple Rest interface with SQL Server - Simple Talk
- Importing JSON Data from Web Services and Applications into SQL Server
- RazorSQL - SQL Query Tool and SQL Editor for Mac, Windows, and Linux
- Big Data - Talend Big Data Integration Products and Services
- MongoDB data loading using Kettle
- Importing MongoDB Data Using SSIS 2012
- Features of Studio 3T
- MongoDB Extended JSON specification
- mongoimport — MongoDB Manual
- mongoexport — MongoDB Manual
- Community Supported Drivers Reference — MongoDB Ecosystem
- mongo — MongoDB Manual
- mongodump — MongoDB Manual
- mongorestore — MongoDB Manual
- mongostat — MongoDB Manual
- mongotop — MongoDB Manual
- MongoDB Package Components — MongoDB Manual
- mongoreplay — MongoDB Manual
- Schema Validation — MongoDB Manual
- How to Create and Validate JSON Schema in MongoDB Collections
- Understanding JSON Schema — Understanding JSON Schema 7.0 documentation
- JSONSQLServerRoutines/CreateJSONSchemaFromTable.sql – Phil Factor
- Work with JSON data in SQL Server - SQL Server
- $lookup (aggregation) — MongoDB Manual
- JSONSQLServerRoutines/SaveExtendedJsonDataFromTable.sql – Phil Factor

