

One of the most common requests is to get SSIS to run more than process at a time. By default SSIS will do this for you, you just have to plan for it. Some processes do not lend themselves to multiple threads of execution and tend to need to be run linearly. For those that can this article is for you.
We’ll cover 6 different concurrent processing methods, the first 4 in part 1 and the remaining 2 in part 2.
Before we get into the different methods, please execute the “TempTableBuildPopulate.sql” script from the sample project, this creates the control structures and sample data for all of the examples. The sample data includes up to 55 random id values. You will need to place the sample project in C:\Temp, this is due to hard coded path references for child packages in later examples. As a design point, all of the logic is contained in the packages. In a production build I would tend to suggest moving the larger blocks of logic into sprocs and calling them from the database. This was not done in the example for clarity.
Of the first method is what I like to call the “simple” method, it is in the sample project as SimpleMethod.dtsx, it is really just two components in a control-flow:
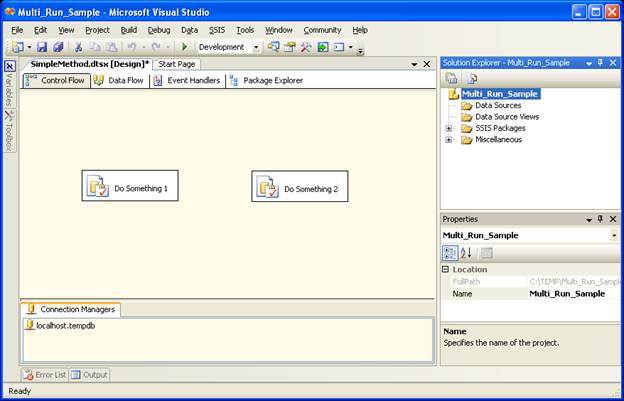
When you run this package the two components will run independent of each other, you can add a little more complexity to it by adding a third component dependent on one of the other components. This is SimpleMethod2.dtsx: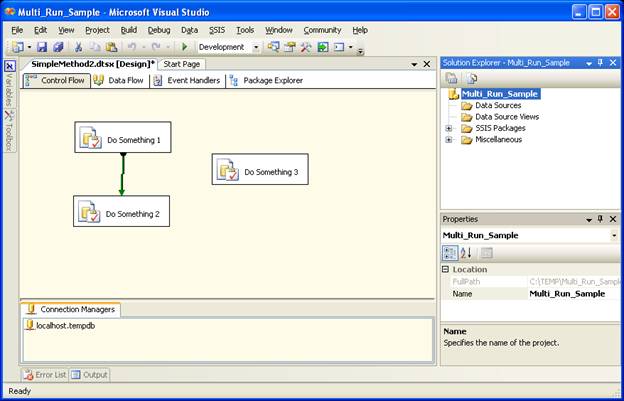
Just like the last case we have two separate paths that can be executing at the same time.
But what happens when you have bigger more complex processes that you want to run concurrently, perhaps you don’t know exactly how many processes there are at design time or perhaps you don’t want to care. You can handle this too; it is just more complex. One of the important considerations is that in most ways a package is set at design-time and cannot fundamentally change at run-time. With the use of package configurations and command-line parameters you can make many changes to a package, but you can’t add a component to the control-flow or rewire a data-flow without extensive programming knowledge. Let’s look at a package that gets a unit of work, breaks that work down to separate processes to run. It is included in the sample project as OnePackageMethod.dtsx:
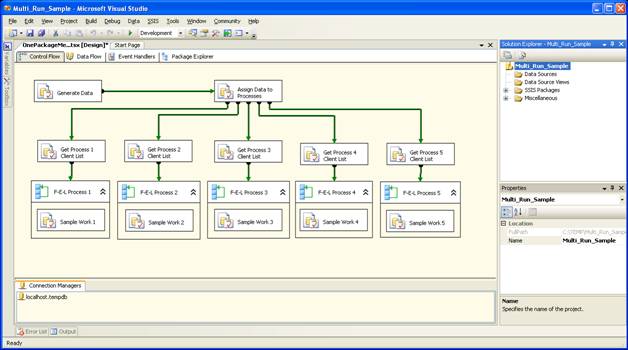
As you can see there are 5 separate processes, what this means is that this package can do is run five separate processes at a time. This package has a number of good concepts to use in your own packages. Let’s walk through all the pieces:
The “Generate Data” task in your package would create some data for the rest of the processes to work on. In this and all the other examples this step cleans a control structure used to manage the workload.
The “Assign Data to Processes” task takes the “sample data” and assigns it to one of five processes. This process is necessary in this example because the sample data does not have natural breaks that we could use to assign the work to a process.
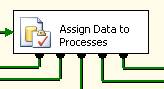
For these processes we create a number of variables, one for each process, each variable is of type object, these variables contain a record set containing rows of ids used to feed the For Each Loop. You can see all five variables are the same except for the name.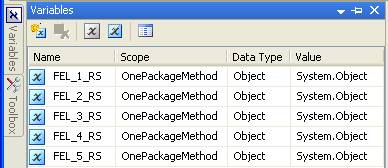
The five individual processes are all effectively the same with only minor variations between. Each process has an Execute SQL task that queries a control structure for all records that are appropriate for that process. A For Each Loop then uses the object variable returned by the Execute SQL task to call a process that does some work. Here it is represented as an Execute SQL task. This is where the real work is done; everything else to this point was setup to get the loop running with a new value for ClientId during each pass.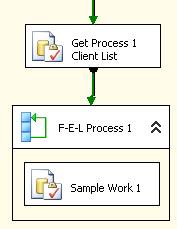
Let’s go into detail here and we’ll start by looking at the “Get Process 1 Client List” Execute SQL task. The important element here is the ResultSet which needs to be set to “Full result set”, it is highlighted in red.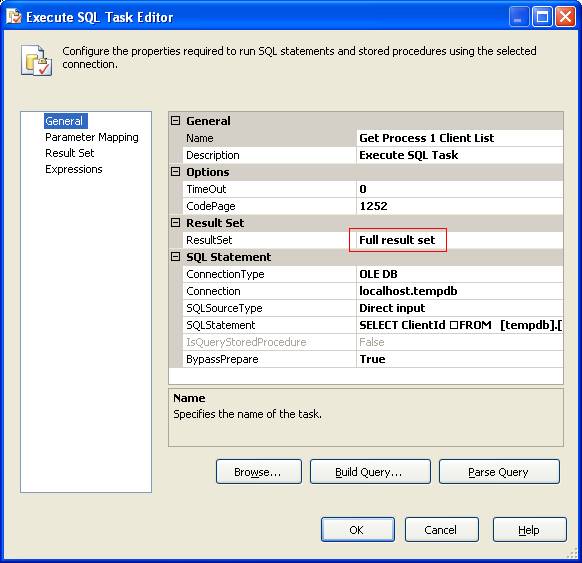
The SQLStatement is pretty straightforward:
SELECT ClientId
FROM [tempdb].[dbo].[tempWorkLoadLocalMethod]
WHERE ProcessId = 1
GO
There is nothing for us in the “Parameter Mapping” tab, so we skip to the “Result set” tab. We add an entry here where the result name is set to 0 (zero) and the variable name is set to the variable for the object variable. As you can see in this example and the image, it is “User::FEL_1_RS”. For process 2 it would be “User::FEL_2_RS” and so on for the other three processes.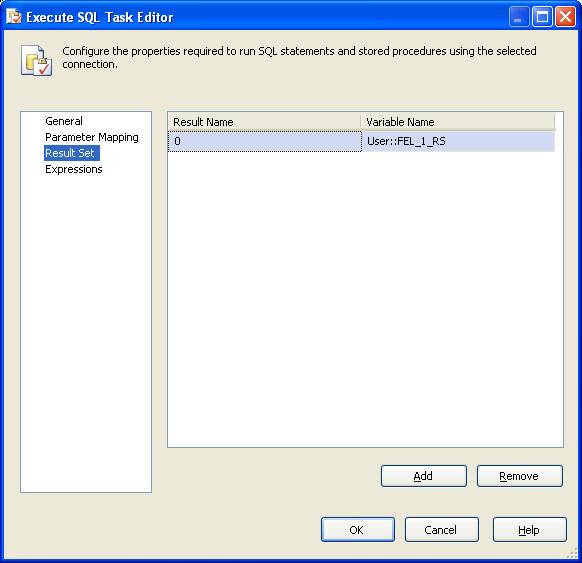 Within the For Each Loop we create a variable with the scope of that task alone. This variable will be used within the task to hold the ClientId used by the “work”.
Within the For Each Loop we create a variable with the scope of that task alone. This variable will be used within the task to hold the ClientId used by the “work”. 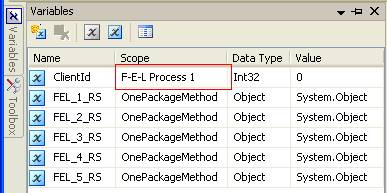 The For Each Loop requires some setup, but there is nothing important on the “General” tab, so we skip to the “Collection” tab. The important elements here are the “Enumerator”, which must be set to “Foreach ADO Enumerator”, the “ADO object source variable” must be set to the object variable that was populated by the last step, and the “Enumeration mode” must be set to “Rows in the first table”. What this means is that we want it to walk through the data in object variable that occurs in the first available table.
The For Each Loop requires some setup, but there is nothing important on the “General” tab, so we skip to the “Collection” tab. The important elements here are the “Enumerator”, which must be set to “Foreach ADO Enumerator”, the “ADO object source variable” must be set to the object variable that was populated by the last step, and the “Enumeration mode” must be set to “Rows in the first table”. What this means is that we want it to walk through the data in object variable that occurs in the first available table.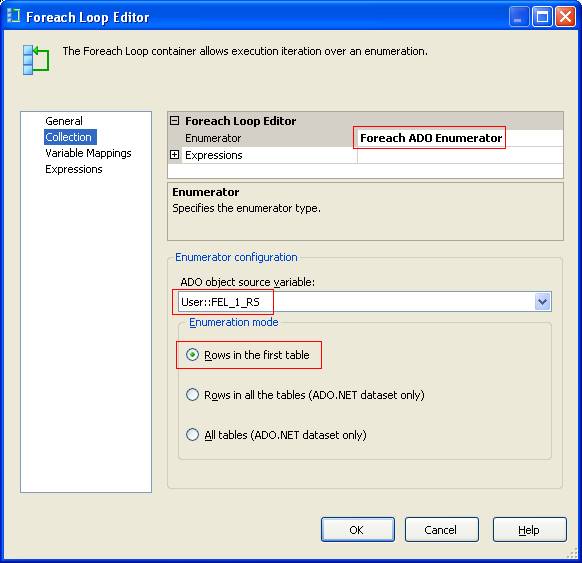
The “Variable Mapping” tab contains the next important element. Here we are mapping the locally scoped variable to the field index of zero. This indicates the first field in the result set will be mapped to the “User::ClientId” variable.
When the For Each Loop runs, the variable “User::ClientId” will contain whatever value is in that processes result set.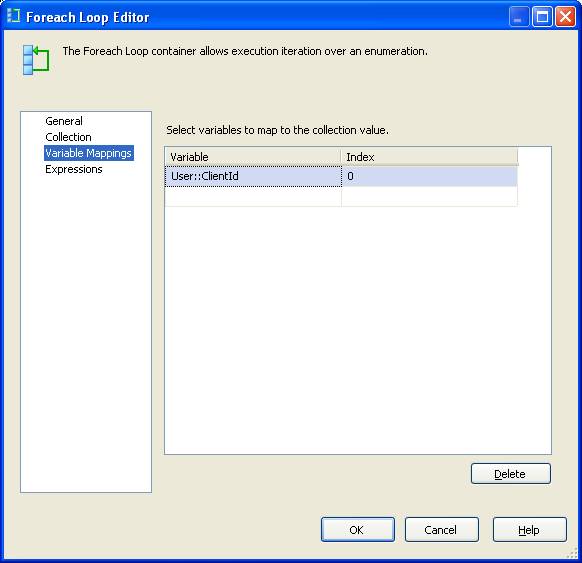
An additional setup item for the For Each Loop is to set the MaximumErrorCount above 1. in the example it is set at 5000, and this should prevent the task from failing if the sub-task fails.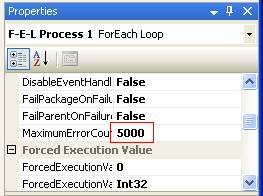
For our sample work we are using a simple Execute SQL task that sets a ProcessDt in the control structure, this provides you a nice way to tell progress of the process as it runs. It is not required for this example of this method to work correctly.
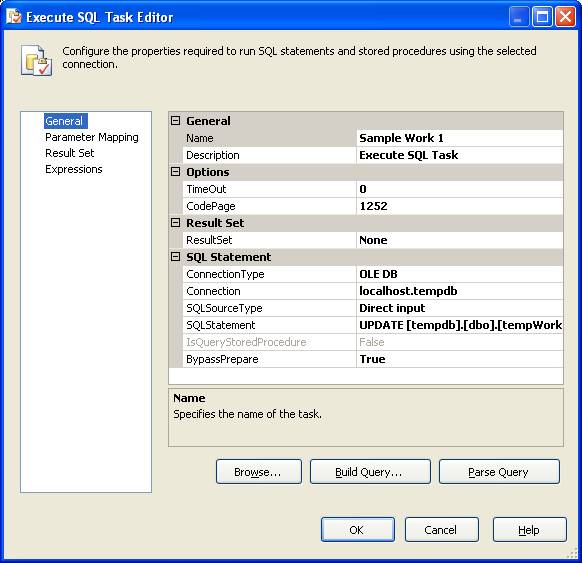
The query for this “work” is very simple, using the parameter marker “?”:
UPDATE [tempdb].[dbo].[tempWorkLoadLocalMethod]
SET ProcessDt = CURRENT_TIMESTAMP
WHERE ClientId = ?
We map the “User:ClientId” variable into the parameter in the “Parameter Mapping” tab.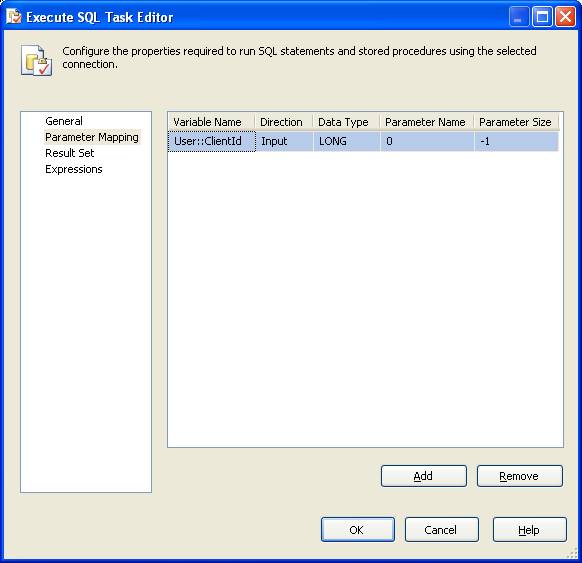
This method is nice and fairly simple but it requires ALL of the logic for each process to be contained in the same package. Given your environment this may not be a problem. However for very complex work it might make more sense to move that logic into a separate package. The example is called “ParentMultiChildMethod.dtsx”, and it replaces the Execute SQL task with an Execute Package task that calls one of five packages called “MultiChild1.dtsx”, “MultiChild2.dtsx”, “MultiChild3.dtsx”, “MultiChild4.dtsx”, and “MultiChild5.dtsx”. Each of these packages is EXACTLY the same as “MultiChild1.dtsx” with the exception that each one is only looking at the work for it.
This method is messy because you have to have a bunch of separate packages that are all really the same. It is included for completeness and will not be explained in detail.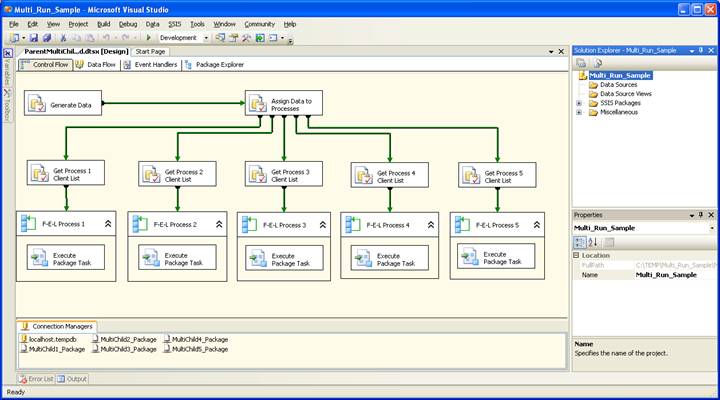
Keep in mind there are practical limits on how many processes can be running at a time. Those limits are primarily imposed by memory and processing power. For example in most cases on a small machine running SQL and the development tools with 2GB of memory I couldn’t get more than 3 concurrent child packages running at any one time except for the last example where we had complete control over the number of threads running. Also if the processing you are doing is fairly intensive on the server you may want to limit the number of processes because in this case many times more processes make EVERY process take a lot longer. While you are running five processes at a time they are taking eight times longer to run. That is not what we are trying to accomplish. In most cases empirical testing is the only way to determine what the threshold is for saturation of the machines resources.
Conclusion
This article shows the basics of running concurrent processes in SSIS with four possibilities. The next article will look at two additional ways to process data in parallel.


