Shrinking Transaction Log Files
-
Hello Everyone,
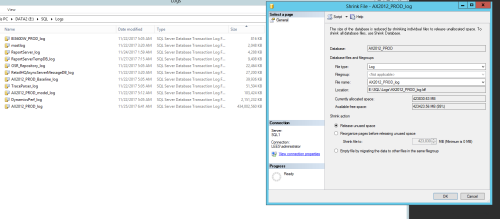
My transaction log file grew extremely large and is taking up almost of the disk space. I am new to SQL and never have performed a shrink of the log file. Based on the image below can I just execute this without causing any issues? Any help would be greatly appreciated?

Thank you,
- kaven.snyder - Monday, November 27, 2017 2:04 PM
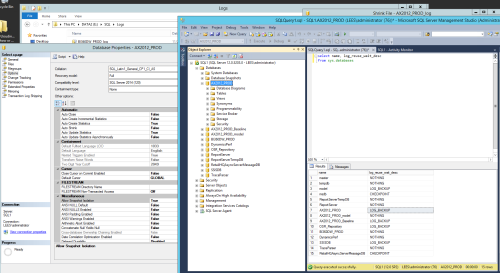
First you want to understand why the log blew up like that - shrinking is not something you should do regularly. It's more something for size issues from one off processes or something like that. You would want to check to see if the log is waiting on a backup, replication, etc. Query sys.databases with something like:
select name, log_reuse_wait_desc
from sys.databases
That can sometimes determine the direction you go but just fixing something and then walking away isn't something you want to do in this case. You'd want to understand how it got to be that size.
If it's size is waiting on log backup then you want to look at the recovery model and how often the logs are being backed up. If it's full and the logs aren't backed up, that's the problem. Index maintenance can also cause the log to grow. But you would want to work on this area/issue.
In terms of shrinking the log, I wouldn't recommend just shrinking all of that right away, especially during production hours. I would probably shrink it in a few chunks/passes at least and probably off hours.Sue
-
Also check what recovery mode your database is in, if it is Full or Bulk-Logged recovery mode you need to be performing regular backups of the transaction log or it will just keep growing.
-
Thanks for the quick replies, This is what I have gathered based upon your comments. Also I understand there is a bigger issue that needs to be resolved but just to confirm I can shrink the log file but only recommended after hours?
-
Have you ever performed a log backup on the database? You will not be able to shrink the log file and remove anything that has been written to it since the last backup so if you've never performed a log backup you won't get any space back from shrinking it.
-
it appears the last backup was performed on 11/27/2017
-
Log backup and database backup are two different things. But you do have 99% of the log file being free space. The thing that could hurt is if the active portion of the log is at the beginning. Generally all you need to do is a log backup and that usually will push the active portion of the log. If you still can't shrink or can't shrink it further, do another log backup.
And then as I mentioned, if it's in full recovery you need to make sure to have regularly scheduled log backups. How regular depends on the amount of activity but that is generally how you keep log space usage in check. Looks like you have some other database to check as well after you get this one addressed.Sue
-
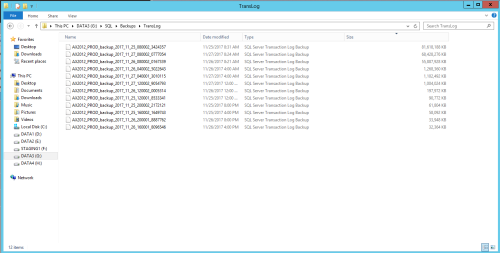
Hmm.... do you know what was causing it to spike so much? The three days worth of backups shown have a large backup every day, you can shrink it but if whatever process was doing that is still running the size will just blow up again.
-
Are those scheduled every 4 hours? You can increase that if needed.
However, look at the jump in size between 4 am and 8 am on the 26th. I'd see if I can figure out what was going on during that time.
Another thing to check is the growth size and growth increment. Usually you don't want the growth in percentages - the growth increment gets bigger and bigger and bigger. I'm kind of wondering if the percentages is what led to it growing like thatSue
-
I just looked again - it's a process between 4 and 8 am that looks to be causing the growth. Sorting that by date rather than size may help you see the pattern. Is there some index maintenance during that time or some import process or something along those lines? And could you check the growth to see if it's a percentage?
Sue
-
Of course, I agree with all the info about having both a backup and restore plan and taking regular backups to support the RTO (Recovery Time Option) and RPO (Recovery Point Option) for each database is all a part of that.
I have run into such log files that suffered such growth because of some of the other things mentioned. Having a smaller log file is really important to restores for several reasons. Unlike the data files in SQL Server, Log files don't benefit nearly as much from instant file initialization. Once the file has been created to the full size it was when the backup was taken, then it has to format the VLFs (or my understanding is). That can take a HUGE amount of time even if the log file was virtually empty when the backup was taken. It also takes the same huge amount of disk space during a restore and smaller companies just might not be able to afford a ton of extra disk space on whatever they would use as a secondary computer to do a restore.
In the following method, there is a bit more risk than the "take a backup, try to shrink, take another backup, try to shrink, wash, rinse, repeat" method but it is very effective and is quite effective. It also gives you a chance to fix "VLF Bloat" if the initial settings for the database where lacking during the original creation of the database. Here's the method and it's obviously better to do this during a maintenance period especially if that means kicking all the users out. It will work on a fairly busy server but you do put some data at risk after step 2 up to the completion of step 7.
0. Disable the backups for the database.
1. Check the settings for the log file.
1.1 Before you make any changes, please read the following two articles for why the initial size and growth patterns are so very important when it comes to (VLFs - Virtual Log Files). Both can affect performance and both can certainly and seriously affect restore times.
https://www.sqlskills.com/blogs/kimberly/transaction-log-vlfs-too-many-or-too-few/ --Pre-2014
https://www.sqlskills.com/blogs/paul/important-change-vlf-creation-algorithm-sql-server-2014/ --2014 and up
1.2. Make sure the initial size is the right size for what you need to avoid growth for normal usage.
1.3. Make sure the growth pattern is based on a fixed size rather than a percentage. If doing this during a busy time, you might want to make this the same as the right-sized initial size so that if you get a growth during step 4, it won't be too small.2. Do a DIF backup of the database to give you a good second file to restore to in case anything goes wrong.
3. Change the database to the SIMPLE recovery model. This DOES break the log file chain.
4. Shrink the log file to 0.
5. Immediately regrow it to the planned size (with respect to the fact that you might have to do the growth in spurts to get the right number of VLFs.
6. Change the database back to the FULL or BULK LOGGED Recovery Model
7. Do a DIF backup of the database to re-establish the log file chain.
8. If you made the growth in step 1.3 the same as the intial size, don't forget to change it back to what you planned.
9. Re-enable the backups for the database.
My suggestion is to write a script to do all of this to minimize the time in the SIMPLE recovery model. Make sure you test the script on a non-production box before using it in prod.
My personal experience with this is that it works quite quickly but you may have a different experience. Again, test it on a non-prod box to get an estimation of how long it could take.
If you can't afford to take even the minor risk with data, then use the "take a backup, do a shrink" thing until it gets down to size. I still recommend going all the way to zero, if possible, and then growing it according to the articles at the links I provided.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) -
I agree with Jeff, I use this to shrink and/or fix VLF -- modify it as you like
declare @org_size table (file_id int, database_id int,db_name varchar(400), type_desc varchar(5),pn nvarchar(2000),size_in_mb bigint,ln nvarchar(2000))
insert into @org_size
select file_id, database_id,db_name(database_id) as db_name, type_desc , physical_name ,
(size * 8)/1024 AS size_in_mb,name
from sys.master_files
where state=0
and is_read_only=0
and type=1--select * from @org_size
Create Table #stage( RecoverUnitID int,
FileID int
, FileSize bigint
, StartOffset bigint
, FSeqNo bigint
, [Status] bigint
, Parity bigint
, CreateLSN numeric(38)
);Create Table #results(db_id int,
Database_Name sysname
, VLF_count int
);Exec sp_msforeachdb N'Use [?];
Insert Into #stage
Exec sp_executeSQL N''DBCC LogInfo([?])'';Insert Into #results
Select db_id(),DB_Name(), Count(*)
From #stage;Truncate Table #stage;'
Select *
From #results
Order By VLF_count Desc;declare @cmd varchar(4000)
declare @ts varchar(1000)
declare @name varchar(1000),@db_id int
declare @vlf_count bigint
declare @path nvarchar(1000) = 'X:\SQLBackup\LogBackup\' -- must end with \
select @ts=replace(replace(replace(replace(cast(CURRENT_TIMESTAMP as datetime2),' ','_'),':','_'),'-','_'),'.','_')+'.trn with compression'declare c1 cursor for
select db_id,database_name , VLF_count
from #results where db_id > 4 and VLF_count >=100open c1
fetch next from c1 into @db_id, @name,@vlf_count
while @@FETCH_STATUS=0
begin
select @ts=replace(replace(replace(replace(cast(CURRENT_TIMESTAMP as datetime2),' ','_'),':','_'),'-','_'),'.','_')+'.trn'' with compression'
select @cmd='Backup Log [' + @name + '] to disk = ''' + @path + @name + '\' + @name + '_backup_' + @ts + '-- vlf count is :' + cast(@vlf_count as nvarchar)begin try
print @cmd
exec(@cmd);
end try
begin catch
print 'backup failed'
end catch
select @cmd= 'use [' + @name + ']; dbcc shrinkfile( ' + cast(file_id as nvarchar) + ',TRUNCATEONLY) -- shrink the file' from @org_size where database_id = @db_id
begin try
print @cmd
exec(@cmd);
end try
begin catch
print 'shrink to zero failed'
end catch-- UNComment this section if you want it to grow back to original size
----------------------------------------------------------
--select @cmd='use master; Alter database [' +DB_NAME + '] modify file (name=' +ln + ',size=' + cast(size_in_mb as nvarchar) +'MB) -- shrink the file to original size' from @org_size where database_id = @db_id
--begin try
--print @cmd
--exec(@cmd);
--end try
--begin catch
--print 'shrink to origianl size failed'
--end catch
-----------------------------------------------------------fetch next from c1 into @db_id,@name,@vlf_count
end
close c1
deallocate c1Drop Table #stage;
Drop Table #results; - Lj Burrows - Monday, December 4, 2017 2:54 AM
That would seem to be a dangerous link because it says nothing of how to reestablish the log file chain. Take a look at what I posted for a method that does.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally)
Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply