Identifying a grouping within a group of overlapping times?
-
I didn't even notice it dropped trip id 28754... Ok, did ore refactoring and now I get 19 results with most being overlaps of 2 except the last one which is 7 and a total of 19 rows (as we expected).
The code is a bit messy and can probably be optimized a bit, but it is a fun and interesting challenge.
How does this code look:
WITH [cte]
AS
(
SELECTDISTINCT
[t].[rn] AS [rn]
, [t].[ldate] AS [ldate]
, [t].[tripid] AS [tripid]
, [t].[clientid] AS [clientid]
, [t].[license#] AS [license#]
, [t].[AAT] AS [aat]
, [t].[ADT] AS [adt]
, [t2].[rn] AS [rn2]
, [t2].[ldate] AS [ldate2]
, [t2].[tripid] AS [tripid2]
, [t2].[clientid] AS [clientid2]
, [t2].[license#] AS [license#2]
, [t2].[AAT] AS [aat2]
, [t2].[ADT] AS [adt2]
FROM[#TestTrips] AS [t]
INNER JOIN [#TestTrips] AS [t2]
ON [t].[ldate] = [t2].[ldate]
AND [t].[license#] = [t2].[license#]
AND [t].[tripid] <> [t2].[tripid]
WHERE(
(
(
[t2].[AAT] >= [t].[AAT]
AND [t2].[AAT] < [t].[ADT]
)
OR
(
[t2].[ADT] > [t].[AAT]
AND [t2].[ADT] <= [t].[ADT]
)
)
OR
(
[t].[AAT] >= [t2].[AAT]
AND [t].[AAT] < [t2].[ADT]
)
OR
(
[t].[ADT] > [t2].[AAT]
AND [t].[ADT] <= [t2].[ADT]
)
)
)
-- Store results in temporary table
SELECT DISTINCT
[cte].[rn]
, [cte].[ldate]
, [cte].[tripid]
, [cte].[clientid]
, [cte].[license#]
, [cte].[aat]
, [cte].[adt]
, [cte].[rn2]
, [cte].[ldate2]
, [cte].[tripid2]
, [cte].[clientid2]
, [cte].[license#2]
, [cte].[aat2]
, [cte].[adt2]
INTO
[#tmpTable]
FROM[cte];
--#tmptable holds all trips with overlaps
-- prepare to loop through results and store all grouped results
DECLARE @loopCount INT = 1;
DECLARE @tripID INT;
DECLARE @tripID2 INT;
DECLARE @result TABLE
(
[rn] INT
, [ldate] INT
, [tripID] INT
, [clientID] INT
, [license#] CHAR(7)
, [aat] CHAR(5)
, [adt] CHAR(5)
, [grouping] INT
);
DECLARE [curse] CURSOR LOCAL FAST_FORWARD FOR
SELECT
[tripid]
, [tripid2]
FROM[#tmpTable]
ORDER BY[ldate]
, [license#]
, [aat]
, [adt];
OPEN [curse];
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
DECLARE @correctedLoop INT;
WHILE @@FETCH_STATUS = 0
BEGIN
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
)
BEGIN
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @loopCount
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @loopCount
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
ELSE
BEGIN
SELECT
@correctedLoop = [grouping]
FROM@result
WHERE[tripID] = @tripID2;
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
SELECT
@loopCount = @loopCount + 1;
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
END;
CLOSE [curse];
DEALLOCATE [curse];
-- end loop and print distinct result set
SELECTDISTINCT
[result].[rn]
, [result].[ldate]
, [result].[tripID]
, [result].[clientID]
, [result].[license#]
, [result].[aat]
, [result].[adt]
, [result].[grouping]
, DENSE_RANK() OVER (ORDER BY [result].[grouping]) AS sequentialGrouping
FROM@result AS [result]
ORDER BY[result].[grouping];
DROP TABLE [#tmpTable];A bit messy as I said, but I think this works better. Basically increments the counter for all cases where it is a new group and re-uses the value when it is a previously used group.
Thinking this one should be more solid. I ran it with some additional test cases that I could think up and it seems to work well. Fingers crossed it works with your real data!
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Man, I applaud your perseverance on this as it's truly impressive.
My validation looks like this is indeed the trick! Since the full dataset has over 29K records it takes about 6 minutes to complete, but I'm not complaining at all since this code is definitely saving my bacon. Thank you so much. I am always astounded at the ingenuity and generosity of fellow coders and the time and effort given so freely. It is so much appreciated.
Now that I have this dataset, I'm onto the next part...finding the first trip in each group, and identifying the cost for the first trip as opposed the rest of the trips in the group. I think I'm good to go, now that you've supplied the hard part.
Again, thank you so much for your help on this; I'll live to code another day now! ; )
~cheers
-
I am glad I could help! I found the problem to be interesting and fun to work on.
Been a while since I had a fun, challenging SQL query like that to write. I imagine some of those better at this than I will tell you not to use a cursor as they are slow (which I entirely agree with), it was just the best way I saw to go through the data and get the final result.
6 minutes on 29,000 records sounds incredibly slow, but that initial matching is probably making that a LOT larger, especially if each row matches up with at least 1 other row and matches up with more than 1 in some (all) cases. It generates a lot of duplicate data with that first bit which could probably be trimmed down a bit before the loop which would help performance. That and rewriting it to not use the cursor would help a LOT. A cursor was just the best way I could think of to handle the problem (without throwing it over to something like C#)..
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Ok Brian, I'm scratching my head here now.
I ran this same query for a different date range and I'm now getting a bunch of duplicated records for some reason. I'm trying to see why it would duplicate some trips and not others, or at least see if there's something special about the trips being duplicated but I'm not seeing it. It seems the Grouping column is making a new/different grouping number on these specific trips when it shouldn't. (?).
It also seems like when I apply the code to a larger dataset it starts duplicating, but I can't reproduce it on a smaller dataset. And I'm not able to walk through your cursor to figure out what could be causing the duplication....
Yikes! I ran it for the month of February with a total of 25078 records, and once the sequential groupings were identified, I had over 590 duplicated tripIDs within the final dataset. When I pull out 3 of those duplicated TripIDs and try to shorten the initial data to include those plus some other trips, (just to reduce the total amount of data processed and see if they duplicate again), I run your code and there's no duplication. So confused. Do you know why it would start duplicating some TripIDs?
-
I have a thought on that... I think I missed one of the "sanity" checks in the CURSOR... try this:
;WITH [cte]
AS
(
SELECTDISTINCT
[t].[rn] AS [rn]
, [t].[ldate] AS [ldate]
, [t].[tripid] AS [tripid]
, [t].[clientid] AS [clientid]
, [t].[license#] AS [license#]
, [t].[AAT] AS [aat]
, [t].[ADT] AS [adt]
, [t2].[rn] AS [rn2]
, [t2].[ldate] AS [ldate2]
, [t2].[tripid] AS [tripid2]
, [t2].[clientid] AS [clientid2]
, [t2].[license#] AS [license#2]
, [t2].[AAT] AS [aat2]
, [t2].[ADT] AS [adt2]
FROM[#TestTrips] AS [t]
INNER JOIN [#TestTrips] AS [t2]
ON [t].[ldate] = [t2].[ldate]
AND [t].[license#] = [t2].[license#]
AND [t].[tripid] <> [t2].[tripid]
WHERE(
(
(
[t2].[AAT] >= [t].[AAT]
AND [t2].[AAT] < [t].[ADT]
)
OR
(
[t2].[ADT] > [t].[AAT]
AND [t2].[ADT] <= [t].[ADT]
)
)
OR
(
[t].[AAT] >= [t2].[AAT]
AND [t].[AAT] < [t2].[ADT]
)
OR
(
[t].[ADT] > [t2].[AAT]
AND [t].[ADT] <= [t2].[ADT]
)
)
)
-- Store results in temporary table
SELECT DISTINCT
[cte].[rn]
, [cte].[ldate]
, [cte].[tripid]
, [cte].[clientid]
, [cte].[license#]
, [cte].[aat]
, [cte].[adt]
, [cte].[rn2]
, [cte].[ldate2]
, [cte].[tripid2]
, [cte].[clientid2]
, [cte].[license#2]
, [cte].[aat2]
, [cte].[adt2]
INTO
[#tmpTable]
FROM[cte];
--#tmptable holds all trips with overlaps
-- prepare to loop through results and store all grouped results
DECLARE @loopCount INT = 1;
DECLARE @tripID INT;
DECLARE @tripID2 INT;
DECLARE @result TABLE
(
[rn] INT
, [ldate] INT
, [tripID] INT
, [clientID] INT
, [license#] CHAR(7)
, [aat] CHAR(5)
, [adt] CHAR(5)
, [grouping] INT
);
DECLARE [curse] CURSOR LOCAL FAST_FORWARD FOR
SELECT
[tripid]
, [tripid2]
FROM[#tmpTable]
ORDER BY[ldate]
, [license#]
, [aat]
, [adt];
OPEN [curse];
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
DECLARE @correctedLoop INT;
WHILE @@FETCH_STATUS = 0
BEGIN
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
OR [tripid] = @tripID
)
BEGIN
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @loopCount
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @loopCount
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
ELSE
BEGIN
SELECT
@correctedLoop = [grouping]
FROM@result
WHERE[tripID] = @tripID2;
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
SELECT
@loopCount = @loopCount + 1;
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
END;
CLOSE [curse];
DEALLOCATE [curse];
-- end loop and print distinct result set
SELECTDISTINCT
[result].[rn]
, [result].[ldate]
, [result].[tripID]
, [result].[clientID]
, [result].[license#]
, [result].[aat]
, [result].[adt]
, [result].[grouping]
, DENSE_RANK() OVER (ORDER BY [result].[grouping]) AS sequentialGrouping
FROM@result AS [result]
ORDER BY[result].[grouping];
DROP TABLE [#TestTrips]
DROP TABLE [#tmpTable];The change in the code is in the IF NOT EXISTS part:
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
OR [tripid] = @tripID
)When I was doing testing with the sample data we had, I found that comparing on @tripID AND @tripID2 did not change the result, and for performance purposes (since it is a cursor and is already pretty slow, having one less thing to look at should help performance in a very minor way). adding that back in should remove the "duplicates" I think... I cannot reproduce the problem you were seeing, but that is my guess as to what is causing it... I can try to find some time tomorrow to test that more though... I can probably create some fake data that will screw it up with the original "answer".
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
So that reduced the number of duplicates down to 268, but didn't eliminate.
I'm trying to see if I can reproduce the issue with a smaller subset of data that I can post here as more sample data. (Posting 20K+ rows of data just wouldn't be prudent. hehe)
BTW The weird part to me is that the code ran beautifully for the entire month of January data. No duplicates at all. But once I opened it up to February, or even January + a few days in December, it just started duplicating trips.
EDITED: I still can't seem to find a small enough dataset to post which will return duplicates so not sure if it has something specifically with having a large number of records to process (?).
-
As a weird thought, are you sure they are duplicates? You said that it wasn't until you opened up a wider date range... I am wondering if MAYBE it is that the date is different but everything else looks the same?
although... I have a thought... slightly more complicated query but how about this one:
;WITH [cte]
AS
(
SELECTDISTINCT
[t].[rn] AS [rn]
, [t].[ldate] AS [ldate]
, [t].[tripid] AS [tripid]
, [t].[clientid] AS [clientid]
, [t].[license#] AS [license#]
, [t].[AAT] AS [aat]
, [t].[ADT] AS [adt]
, [t2].[rn] AS [rn2]
, [t2].[ldate] AS [ldate2]
, [t2].[tripid] AS [tripid2]
, [t2].[clientid] AS [clientid2]
, [t2].[license#] AS [license#2]
, [t2].[AAT] AS [aat2]
, [t2].[ADT] AS [adt2]
FROM[#TestTrips] AS [t]
INNER JOIN [#TestTrips] AS [t2]
ON [t].[ldate] = [t2].[ldate]
AND [t].[license#] = [t2].[license#]
AND [t].[tripid] <> [t2].[tripid]
WHERE(
(
(
[t2].[AAT] >= [t].[AAT]
AND [t2].[AAT] < [t].[ADT]
)
OR
(
[t2].[ADT] > [t].[AAT]
AND [t2].[ADT] <= [t].[ADT]
)
)
OR
(
[t].[AAT] >= [t2].[AAT]
AND [t].[AAT] < [t2].[ADT]
)
OR
(
[t].[ADT] > [t2].[AAT]
AND [t].[ADT] <= [t2].[ADT]
)
)
)
-- Store results in temporary table
SELECT DISTINCT
[cte].[rn]
, [cte].[ldate]
, [cte].[tripid]
, [cte].[clientid]
, [cte].[license#]
, [cte].[aat]
, [cte].[adt]
, [cte].[rn2]
, [cte].[ldate2]
, [cte].[tripid2]
, [cte].[clientid2]
, [cte].[license#2]
, [cte].[aat2]
, [cte].[adt2]
INTO
[#tmpTable]
FROM[cte];
--#tmptable holds all trips with overlaps
-- prepare to loop through results and store all grouped results
DECLARE @loopCount INT = 1;
DECLARE @tripID INT;
DECLARE @tripID2 INT;
DECLARE @result TABLE
(
[rn] INT
, [ldate] INT
, [tripID] INT
, [clientID] INT
, [license#] CHAR(7)
, [aat] CHAR(5)
, [adt] CHAR(5)
, [grouping] INT
);
DECLARE [curse] CURSOR LOCAL FAST_FORWARD FOR
SELECT
[tripid]
, [tripid2]
FROM[#tmpTable]
ORDER BY[ldate]
, [license#]
, [aat]
, [adt];
OPEN [curse];
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
DECLARE @correctedLoop INT;
WHILE @@FETCH_STATUS = 0
BEGIN
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
OR [tripid] = @tripID
)
BEGIN
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @loopCount
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @loopCount
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
ELSE
BEGIN
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
)
BEGIN
SELECT
@correctedLoop = [grouping]
FROM@result
WHERE[tripID] = @tripID2;
END
ELSE
BEGIN
SELECT @correctedLoop = [grouping]
FROM @result
WHERE [tripid] = @tripID
END
INSERT INTO @result
SELECTDISTINCT
[rn]
, [ldate]
, [tripid]
, [clientid]
, [license#]
, [aat]
, [adt]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripID] = @tripID
UNION
SELECT
[rn2]
, [ldate2]
, [tripid2]
, [clientid2]
, [license#2]
, [aat2]
, [adt2]
, @correctedLoop
FROM[#tmpTable]
WHERE[tripid] = @tripID;
END;
SELECT
@loopCount = @loopCount + 1;
FETCH NEXT FROM [curse]
INTO
@tripID
, @tripID2;
END;
CLOSE [curse];
DEALLOCATE [curse];
-- end loop and print distinct result set
SELECTDISTINCT
[result].[rn]
, [result].[ldate]
, [result].[tripID]
, [result].[clientID]
, [result].[license#]
, [result].[aat]
, [result].[adt]
, [result].[grouping]
, DENSE_RANK() OVER (ORDER BY [result].[grouping]) AS sequentialGrouping
FROM@result AS [result]
ORDER BY[result].[grouping];
DROP TABLE [#TestTrips]
DROP TABLE [#tmpTable];Just changed the middle section where it was looking for the duplicates to look at both tripID and tripID2. I am thinking that may be what was causing the duplicates...
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Thanks Brian. Yep, they're definitely duplicates.
Tried this code and I'm still seeing dups. For the February data there are 250 of them.
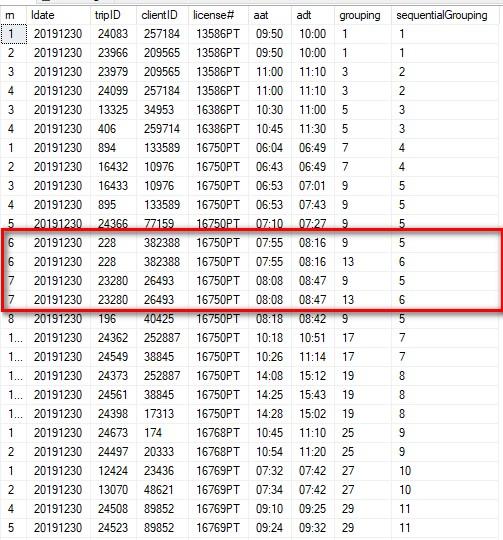
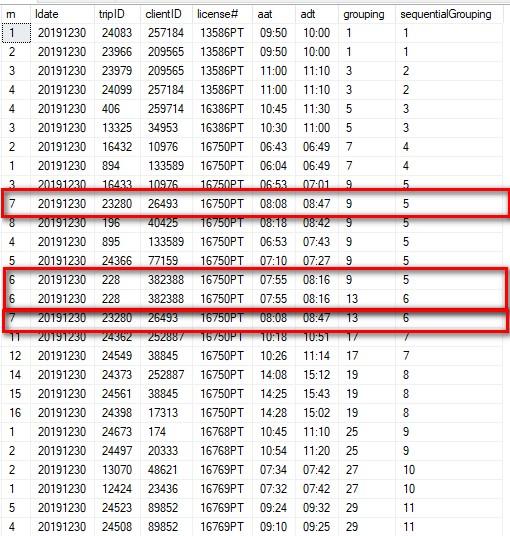
Would it help to see what the dups look like in the data? Below is an example ordered by ldate,license#,aat,adt:

Below is ordered by grouping column:
-
Think I see my typo... try changing:
BEGIN
IF NOT EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
)
BEGIN
SELECT
@correctedLoop = [grouping]
FROM@result
WHERE[tripID] = @tripID2;
END
ELSE
BEGIN
SELECT @correctedLoop = [grouping]
FROM @result
WHERE [tripid] = @tripID
ENDto:
BEGIN
IF EXISTS
(
SELECT
1
FROM@result
WHERE[tripID] = @tripID2
)
BEGIN
SELECT
@correctedLoop = [grouping]
FROM@result
WHERE[tripID] = @tripID2;
END
ELSE
BEGIN
SELECT @correctedLoop = [grouping]
FROM @result
WHERE [tripid] = @tripID
ENDThinking that the "NOT" may be causing the problem.
I am going to test this as well by taking grouping 9 and trying to replicate the problem on my end.
EDIT - I tried to replicate it on my end and was unable to... I inserted all of the data from grouping ID 9 expecting to see 2 groups with duplicates in it and surprisingly there were no duplicates... 2 groups which at first surprised me, but looking at the data, it SHOULD be 2 groups. What I don't get is why you are getting duplicates.
Everything in the code should prevent duplicate TRIPID's from getting into the @result table. It does a check in the @result table to make sure that the trip ID and the overlapping trip ID doesn't exist in the table before it does the insert. If it does exist, then it inserts things with the lower grouping ID.
I cannot think of a way to create duplicates... unless it is something with the ordering of the cursor... What about if you change the CURSOR SELECT statement to be:
SELECT
[tripid]
, [tripid2]
FROM[#tmpTable]
ORDER BY[ldate]
, [license#]
, [tripid]
, [tripid2]
, [aat]
, [adt];Just adding in sorting by TRIPID prior to aat and adt (since tripID and tripID2 combined will be unique, we could remove the aat and adt. We still want to order by ldate and license# first as we want to ensure we go through the loop in a logical order). I don't' think it'll help as I just tried this without ordering the cursor and it still gave me the results I expected. Not in the same order, group 3 turned into my "big" grouping and the rest were all smaller, whereas if I order it, my big grouping was group 9, but it still gave me expected results.
I cannot think of any reason why this won't work or why it gives you duplicates... Is it possible to post a subset of your data (in a text file attachment) that can create problems (like the first 100 rows or first 1000 rows)?
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
I think it's fixed! I just ran the code you just sent with the Not Exists change and I'm no longer seeing duplicates with any of the months I'm running. I'm going to keep running other sets of data and check for duplicates but I'm pretty optimistic that we're looking good.
Brian, you're awesome. And thanks for the detail above on the cursor as well, it helps to clarify some things too. This is great stuff.
Thank you again!
-
I am glad to help. I am glad that fixed the issue too (hopefully).
Sorry the code isn't more efficient. I'm sure there are others on the forum who could look at my code and optimize it. Remove the cursor, use fewer CTE's, possibly make it easier to read and understand (or possibly make it more difficult). I just saw your problem and thought it sounded like an interesting gaps and islands problem. What made it more challenging was you could have overlap. And just because trip A starts at 8:00, it doesn't mean that trip B didn't start before it. And trip lengths are variable. So trip A can overlap trip B and trip B can overlap trip C and trip A may or may not overlap trip C.
So it was an interesting challenge. First figure out all of the overlap, then once we have the overlap, it is just a matter of using that to figure out the grouping. Sounds easy, but it was actually a fun challenge. If SSC had an "interesting SQL challenges" section, I would be recommending this one for it!
The above is all just my opinion on what you should do.
As with all advice you find on a random internet forum - you shouldn't blindly follow it. Always test on a test server to see if there is negative side effects before making changes to live!
I recommend you NEVER run "random code" you found online on any system you care about UNLESS you understand and can verify the code OR you don't care if the code trashes your system. -
Hello Kate,
You're right, we were trying to eliminate the duplicates as that was not correct. Sample data was posted at the beginning of the post, but I was unable to generate more sample data (in a small enough amount to post here) in order to reproduce the duplications. It seemed to only happen with much larger datasets. However, Brian's last answer did fix the issue as I'm no longer seeing any duplications.
If you have any thoughts on optimization for the cursor, I'd be all ears. But other than that, his solution works exactly as needed.
#BrianRules
~Cheers!
Viewing 13 posts - 16 through 28 (of 28 total)
You must be logged in to reply to this topic. Login to reply