Handling Lookup Fields In Dimension Table During Incremental Load
-
I'm trying to build out a data warehouse using the Kimball Methodology and I'm having trouble figuring out how to handle fields that I will refer to as lookup fields because they are manually maintained through other processes. Here is the dimension table I have designed (Red = field from source, Blue = Lookup field)

The NameID and CleanName fields are populated by joining to another table on Name.
The Region field is populated by joining to another table on Zip.
The Type field is populated by joining to another table on Name.My first question would be is my design correct? I chose to do it this way because I don't feel like the lookup fields belong in a junk dimension and I didn't want to make them their own dimensions because I'm trying to avoid snowflaking. Plus I feel like it is a natural fit to include it all in one table since all of the fields describe the Name.
My second question would be does anyone have any general suggestions on handling the ETL? My initial attempt has led me to perform a lookup to see if it exists based on matching criteria and if so move on to the next lookup and if not move on to the same lookup that would be performed had it matched anyway. This essentially duplicates each lookup because I'm grabbing the matching data if it exists but need to use the source data if not.
- RonMexico - Wednesday, April 11, 2018 9:38 AM
It's unclear from your post why you cannot just fully populate the dimension before loading the associated fact data, which would (it would seem) remove all issues. Can you clarify?
-
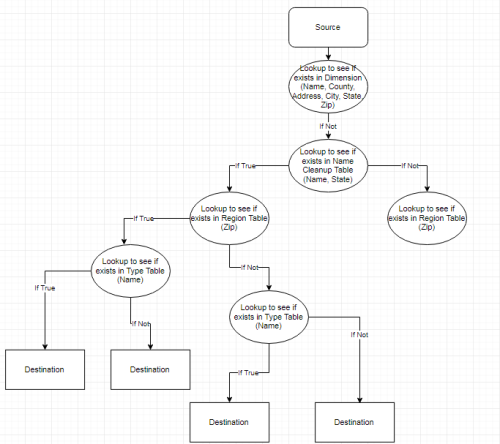
The issue I'm having is fully populating the dimension. I'm using SSIS as my ETL tool and here's the incomplete part of what I'm visualizing.
Each record would work its way down grabbing the populated lookup field if there is a match. If not, then the lookup fields (blue) would be populated with either N/A or -1 since they do not exist. I feel like this is very inefficient since I'm hitting each lookup table twice. That's why I started to question my design of the dimension table since the load of it does not seem efficient. Am I going about it the wrong way?
- RonMexico - Wednesday, April 11, 2018 12:01 PM
Maybe I'm not understanding this? How are you working your way down anything? It sounded like you were doing separate lookups from different fields that populate different fields in the target from different lookup tables. There might be ways to optimize that instead of running a consecutive updates on the same record?
-
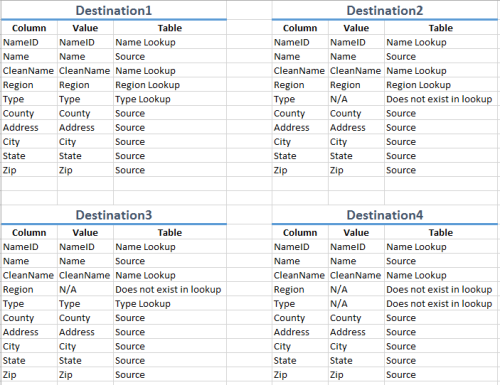
The partial example I included doesn't get into updating. It is only for new records and, therefore, requires an insert. Hopefully in an attempt to make better sense picture it having four possible outcomes. I'll refer to the leftmost destination as Destination1, the second from the left as Destination2, the second from the right as Destination3, and the rightmost as Destination4. As it performs each lookup it will grab any applicable values. Here is how each destination will be populated
You can see that Destination1 satisfies all lookup criteria, Destination2 misses on Type, Destination3 misses on Region, and Destination4 misses on both Type and Region. If I were to keep going then there would be four more destinations that do not have a NameID and CleanName as well as any combination of missing Type and/or Region. I very well could be looking at this all wrong which is adding to the confusion. I apologize if that's the case but bear with me since this is my first attempt at building out a DW.
-
...
-
No, it won't be every combination. Just trying to tie together fields that are part of three separate lookup tables. So for example if the Name in the source is Bardley and it has a match in the Name Lookup table then it will get the CleanName of Bradley and NameID of 10. No need to return anything else and the same logic applies to the Region and Type fields.
- RonMexico - Wednesday, April 11, 2018 2:05 PM
If your question is whether you should sanitize certain values on loading into the DW then sure, that's a fairly common request as is storing the original value. Whether what your specific case for what kinds of values and what kind of sanitizing that really requires more information.
-
Hi,
If possible and if it is not a performance issue, I would advise bring all the data that you need into staging tables first, and then build a VIEW, then use this VIEW to load the dimension.=======================================================================
-
Thanks for all of the pointers. It seems as though my design isn't the issue which is good. I was following along with another thread on this board about someone wanting a good beginning to end tutorial/lesson of data warehousing and I think that's where I kind of fall as well. I've read The Data Warehouse Toolkit, Third Edition: The Definitive Guide to Dimensional Modeling so I have a fairly good understanding of the principles. However, I'm lacking in the practical side of using SSIS for the ETL process. If anyone has any suggestions on material for that I would appreciate it. Also, any tips on the example I've been referencing would be great as well. A quick recap...
--I have a source file containing six fields (Name, County, Address, City, State, and Zip) that will be in the final dimension table
--I'm only concerned with inserting new records at this time
--Four fields (NameID, CleanName, Region, and Type) will be added to the dimension by using three separate lookup tables
---->Two fields will be added (NameID and CleanName) by matching Name and State with a NameLookup table
---->One field will be added (Region) by matching Zip with a RegionLookup table
---->One field will be added (Type) by matching Name with a TypeLookup Table -
I may be misunderstanding what you are doing here, but can you not build a single query from the source system that has all of these attributes/fields in the output and then load that final query to a staging table with SSIS? Then from there, build your single dimension table by reading from the staging table and doing like a INSERT WHERE NOT EXISTS or MERGE into that final dimension table to generate a new unique key to reassign back to the staging table as your dimensional foreign key? Seems like you are doing multiple lookups to do these as opposed to just doing it in one big swing, then of course having different destinations based on the results of those individual lookups.
- RonMexico - Thursday, April 12, 2018 5:50 AM
I know that you want to avoid snowflaking & that's driving you to create only a single combined dimension, but there is another option, of course, which still avoids snowflaking. That is to create separate dimensions and to link them directly to your fact table via additional key columns. It sounds like this would make your process simpler, though you may lose the ability to create hierarchies in SSAS, if that's one of your targets.
-
sevensinz and Phil - Both are good points. I think I'm trying to get too creative when there are simpler solutions that work just as well, if not better, than what I'm thinking. I'm going to rethink my strategy and I'll get back if have any additional questions. Thanks for the help!

Viewing 13 posts - 1 through 13 (of 13 total)
You must be logged in to reply to this topic. Login to reply