Ghost Process attacks again
-
Hi,
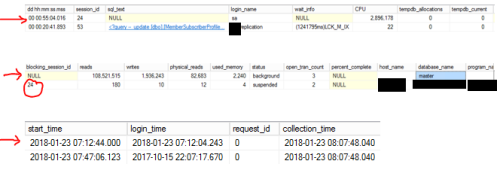
Every now and then, a process (red arrow) executed by SA in our SQL Server 2012 instance blocks our system. It lasts between 65- 80 minutes.

Image shows 2 processes only for this post's sake: session_id 24 blocking session_id 53.
We never use account SA, we don't have jobs running under those credentials. Nor backups nor anything.
Every time this happens we switch our traffic to our backup SQL Server instance (bidirectional transactional replication) and our system comes back to live immediately.
Any ideas what can be happening?Today I got to execute sp_Blitz and it detected:
https://www.brentozar.com/blitz/poison-wait-detected/#THREADPOOL
Our CPU Usage was never zero though.Regards
-
SPID <=50 are mostly system processes and usually the program_name column should show blank. What was the program name for SPID24?
-
There are a large number of things that could be in play here. I don't know that a forum is the place for them because it is an intermittent problem. If you can get a performance tuning professional on standby to RDP into your system while the event is happening it should be possible to isolate a root cause quickly - certainly before the normal event duration elapses.
Did you have any visibility at all to WHAT query(s) were running on spid 24?
Do you have HEAP tables in play?
Could your bi-directional transactional replication be a factor? I have come across that setup (at scale, anyway) precisely twice in ~25 years of consulting on SQL Server, and both were absolute nightmares.
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service -
You can use the following to query details about a session. DBCC INPUTBUFFER will return the last command executed by session, even if the last command completed and the session is not running an active request.
DBCC INPUTBUFFER ( 25 );
SELECT * FROM sys.dm_exec_connections WHERE session_id = 25;
SELECT * FROM sys.dm_exec_sessions WHERE session_id = 25;
SELECT *, qt.text FROM sys.dm_exec_requests AS er
OUTER APPLY sys.dm_exec_sql_text( er.sql_handle) AS qt
WHERE er.session_id = 25;Also, Adam Machanic maintains a stored procedure called sp_whoisactive, which does a good job of joining in additional information and filtering the result.
http://whoisactive.com/"Do not seek to follow in the footsteps of the wise. Instead, seek what they sought." - Matsuo Basho
- RandomStream - Tuesday, January 23, 2018 12:26 PM
it was the hostname of the server
- TheSQLGuru - Tuesday, January 23, 2018 12:29 PM
the results I provided were the output of sp_whoisactive
spid24's sql_text is always NULL when this happens, so we don't have a clue of what's going onHEAP tables, no, all of them have PKs
about replication, not sure if it could be a factor
when we set it up, we never use account SA
we need to have our data in 2 SQL server instances right away in order to be ready for emergencies like the one from today
it is a nightmare when both instances are active (we rarely do this) as replication crashes, that's why we keep it active/passivewe are thinking on hiring an expert for this
thanks all of you for replying
- rogelio.vidaurri - Tuesday, January 23, 2018 1:38 PM
Just a clarification, all your tables have a clustered index (this does not need to be a PK).
- Eric M Russell - Tuesday, January 23, 2018 1:04 PM
SELECT *, qt.text FROM sys.dm_exec_requests AS er OUTER APPLY sys.dm_exec_sql_text( er.sql_handle) AS qt
WHERE er.session_id = 24 got this:
I found this on google though:
"BROKER_TASK_STOP occurs when the Service Broker queue task handler tries to shut down the task. It should not be a problem and nothingbtonworry about from a performance perspective."thanks for the queries
- Lynn Pettis - Tuesday, January 23, 2018 1:41 PM
I'm confused.
I though a HEAP table was a table without a clustered index. Now I'm reading a post that says "a table with only few rows can be a heap".If HEAP tables were my issue, how could I detect them?
- rogelio.vidaurri - Tuesday, January 23, 2018 1:48 PM
A heap table does not have a clustered index. If you query sys.indexes and filter on index_id = 0 you will see if you have any tables that do not have a clustered index.
- Lynn Pettis - Tuesday, January 23, 2018 2:08 PM
no tables of our system
only these:
sysfiles1
spt_fallback_db
spt_fallback_dev
spt_fallback_usg
MSreplication_options
spt_monitorthanks
-
Definitely recommend getting a (good) consultant certified to work for you so they can be on standby to jump on as soon as the event starts occurring again. There are a number of good ones to be found on SSC.com forums.
Note if Ghost Cleanup is actually a factor, I think you actually see something like those words when you evaluate running processes.
Do you DELETE a lot of records in the database? Do tables with such have lots of indexes on them?
Best,
Kevin G. Boles
SQL Server Consultant
SQL MVP 2007-2012
TheSQLGuru on googles mail service - TheSQLGuru - Wednesday, January 24, 2018 10:17 AM
thanks for the forum tip
hadn't seen ghost cleanup as a factor, or as a running process ever
we do delete lots of records in a few datatables, not more than 3 indexes
-
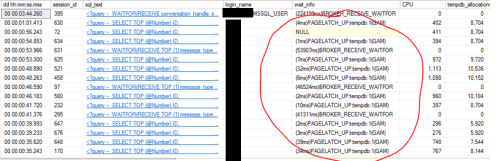
Definitely something is wrong with our SQL instance. We switch traffic back, and after a few hours it got really slow.
Even sp_whoisactive was taking more than a minute some times.I was able to see this (issues with tempdb)?
it is a different issue, not the Ghost Process striking again.Looks like we need a DBA expert.
login_name waiting for PAGELATCH was our DB user for our main database
-
Looks like tempdb contention. How is your tempdb database configured?


Viewing 15 posts - 1 through 15 (of 21 total)
You must be logged in to reply to this topic. Login to reply