fill factor with clustered PK on identity PLUS another column
-
I'm looking for the problem. Changing the 3 declared variables from smallint to int didn't help. It succeeded on a small test database but having this error on a large copy of production.
Started @ 2017-03-29 10:07:11
Index Usage Stats @ 2017-03-29 10:07:11
Msg 220, Level 16, State 1, Line 252
Arithmetic overflow error for data type smallint, value = 65628.
The statement has been terminated.
Ended @ 2017-03-29 10:07:12 - Indianrock - Wednesday, March 29, 2017 11:12 AM
Ouch, sorry! Did you try a global replace on "smallint" to "int"? Maybe that will do it?
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
On the copy of prod I can run it on one table at a time, generally. Same error with certain tables. Everything smallint changed to int. Looking at the temp tables only fill factor was winding up smaller than Integer, so I cast it as Integer, but didn't help.
Seems to be the insert into the missing index temp table that causes the problem.
INTO #index_missing
I've attached the results for one of our problematic tables. - ScottPletcher - Wednesday, March 29, 2017 11:40 AM
The error is raised by this statement
FILEGROUP_NAME(i.data_space_id)The reason for the eror, is that FILEGROUP_NAME expects a SMALLINT as an input.
However, sys.indexes.data_space_id is an INT value - DesNorton - Wednesday, March 29, 2017 1:36 PM
Nice catch/find! @Indianrock, just comment that line out, it's not really need it anyway (I do more with FILEGROUP in my in-house code, but it's not required for general use):
...
--FILEGROUP_NAME(i.data_space_id) AS main_fg_name, --comment this line out
...SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
With some more digging, on my system, this error is caused by a partition scheme
SELECT
Indexname = i.name
, IndexType = i.type_desc
, DataspaceType = ds.type_desc
FROM sys.indexes AS i
INNER JOIN sys.data_spaces AS ds
ON i.data_space_id = ds.data_space_id
WHERE i.data_space_id > 32767; -- MAX value for SMALLINT
Indexname IndexType DataspaceType
------------- ---------- -----------------
CLX_DataPart CLUSTERED PARTITION_SCHEME -
This change didn't remove the error I see there are two indexes that have data_space_id greater than 60,000
FILEGROUP_NAME(cast(i.data_space_id as smallint) ) AS main_fg_name,
tablename object_id name index_id type type_desc is_unique data_space_id ifts_comp_fragment_2009058193_33698738 1588919214 clust 1 1 CLUSTERED 1 66865 ACCOUNT_OWNERSHIP_DOC_SUMMARY 2009058193 ACCOUNT_OWNERSHIP_DOC_SUMMARY_UC1 2 2 NONCLUSTERED 1 65628 - Indianrock - Wednesday, March 29, 2017 1:59 PM
Hmm, I recommended you comment out the reference to FILEGROUP_NAME completely ... I don't see how it can cause an error if it doesn't run :D, like so:
/*FILEGROUP_NAME(cast(i.data_space_id as smallint) ) AS main_fg_name,*/
The filegroup name is not really need for the index usage analysis anyway.SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
This seems to fix it
FILEGROUP_NAME(iif(i.data_space_id>32000,1,i.data_space_id)) AS main_fg_name,Now does anybody really want to see a spreadsheet of the whole database, from this query, or maybe a table a week? 😀
By the way, this forum software is SO much better than what we used to have !
-
A few critical tables would be a good start, particularly large child tables that are currently clustered on an identity column.
Edit: Be sure to include any "missing index" (query 1) and "index stats" (query 2) results for all tables. Note that there may not be any results from query 1 for some tables.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
ok, can some of this be commented out?
MAX(ds.ItemNumber) AS Equality#
FROM #index_missing
CROSS APPLY DBA.dbo.DelimitedSplit8K (equality_columns, ',') ds
WHERE equality_columns IS NOT NULL - Indianrock - Wednesday, March 29, 2017 5:33 PM
Yes, sorry, forgot to remove that part. You can remove anything to do with "@list_missing_indexes_summary", it's very, very helpful but it's not absolutely critical. This script is a subset of a script I use myself at work (2-3 generations old, but the same basic script). I have to adjust it for external use.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
I've attached the results.
-
I've taken a preliminary look. Impressive table size, 3+TB! I'll definitely have some suggestions for possible mods to indexes. I don't know if you be able to / want to implement any/all of them, but that's of course up to you.
At first glance, it even appears there's a better clustering index, ( ACCOUNT_ID, CLIENT_ID ) [the PK could stay the same, it just wouldn't be clustered]. But I'll need more analysis to be sure, and of course that would be a huge change to make, even if you gained you a good amount of performance.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
-
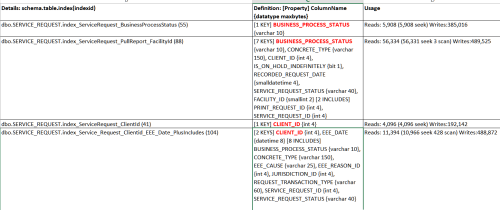
Index analysis is complicated! So, just to get a place to start, I'm looking at "borderline duplicate indexes."
In the cases where there is a single-column index AND another non-clustered multi-column index
that has that column as it's first key, this should be the clearest opportunity to test and possibly remove
the single-column index. When that column is not the first key in the multi-column index, or is down in the includes,
it's a whole different issue. I can find queries that are using the single-column index, and see what happens
with those queries when that index is disabled ( in QA )
Viewing 15 posts - 16 through 30 (of 30 total)
You must be logged in to reply to this topic. Login to reply