amy26 - Friday, September 7, 2018 4:17 PM
Just to pile on about how bad this is (and I know this was not your idea) starting with this sample data:IF OBJECT_ID('dbo.table1','U') IS NOT NULL DROP TABLE dbo.table1;
IF OBJECT_ID('dbo.table2','U') IS NOT NULL DROP TABLE dbo.table2;
CREATE TABLE dbo.table1 (nameId INT IDENTITY, phoneNbr VARCHAR(20), email VARCHAR(100));
CREATE TABLE dbo.table2 (nameId INT IDENTITY, ContactInfo XML);
INSERT dbo.table1(phoneNbr,email) VALUES ('555-444-3333','JoeBlow@gmail.com');
INSERT dbo.table2(ContactInfo) VALUES
('<contactInfo>
<phone>555-444-333</phone>
<email>JoeBlow@gmail.com</email>
</contactInfo>');
Note these queries:-- relational
SELECT t.nameId, t.phoneNbr, t.email
FROM dbo.table1 AS t
WHERE t.email IS NOT NULL
-- XML:
SELECT
t.nameId,
phoneNbr = t.ContactInfo.value('(contactInfo/phone/text())[1]', 'VARCHAR(20)'),
email = t.ContactInfo.value('(contactInfo/email/text())[1]', 'VARCHAR(100)')
FROM dbo.table2 AS t
WHERE t.ContactInfo.value('(contactInfo/email/text())[1]', 'VARCHAR(100)') IS NOT NULL;
Before considering performance, just consider how much more complicated the XML-based solution is. Which is easier to understand? Which appears easier to troubleshoot? Which structure seems easier to maintain?
Now look at the execution plans: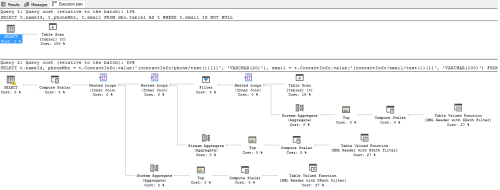
... and this is just one record. Imagine trying to join some other tables, adding a GROUP BY or other basic SQL. The queries will be miserably slow and impossible to tune because the execution plan becomes insanely verbose. Just more food for thought.
-- Itzik Ben-Gan 2001