that works very well. Thought it would be a more complicated code!
and correct on the new column, i needed that too!
Expanding the code, looking at the new column [OrdersInGroup], a max of 5 orders can only fit on a shelf space, and there are a max of 6 locations. If the current result is PickGroup 1:
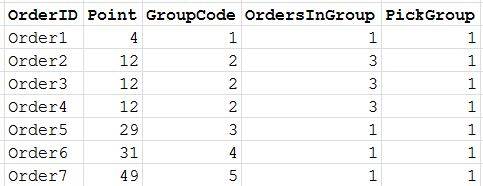
a new wave of orders come through and have similar Points:
SELECT *
INTO #TestTable
FROM (VALUES
('Order8', 4)
,('Order9',4)
,('Order10', 8)
,('Order11',12)
,('Order12',12)
,('Order13',19)
,('Order14',24)
,('Order15',4)
,('Order16',4)
,('Order17',10)
)v(OrderID,Point);
i need to check if there is "free space" on the shelf, order8 would go into groupCode 1 as there now 2 orders therefore can be in PickGroup 1, order10 is a new Point therefore will go into next open shelf location groupCode 6, order11 and 12 drop in and go into groupCode 2, but now reached max 5. therefore that location is now free, the next order13 can now occupy it, therefore it will now wait for other orders for Point 19.
there are no shelf locations (groupCode) open as all are occupied. order14 must therefore be missed, PickGroup 0, orders 15 and 16 go into groupCode 1 and is now full therefore 1 becomes free for next order to be part of PickGroup 2....and so on.
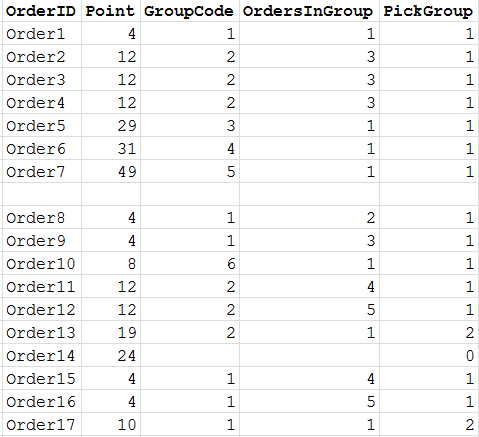
missed orders (pickGroup = 0) will get allocated when no new sets of orders drop in using same method above.
maybe first x orders sets the Points until all 6 GroupCodes have been allocated, then from there iterate through each incoming order?
OrdersInGroup could be a incrementing value, rather than a count?
i'm applying this method on a small dataset of 50 orders, but a typical dataset could hold 10k orders, therefore i would benefit from fast processing...
Many thanks for your help