Problem with Tuning of Delete Statement
-
Hi all,
This is my query.
Delete FROM AliTest2.DBO.SDE_GEOMETRY9
WHERE NOT EXISTS (SELECT objectid,0 FROM AliTest2.DBO.NETWORK_V3
WHERE AliTest2.DBO.NETWORK_V3.OBJECTID = AliTest2.DBO.SDE_GEOMETRY9.GEOMETRY_ID
AND SDE_STATE_ID = 0
UNION ALL
SELECT OBJECTID,SDE_STATE_ID
FROM AliTest2.DBO.a14
WHERE AliTest2.DBO.a14.OBJECTID = AliTest2.DBO.SDE_GEOMETRY9.GEOMETRY_ID
AND AliTest2.DBO.a14.SDE_STATE_ID = AliTest2.DBO.SDE_GEOMETRY9.SDE_STATE_ID)Actual execution plan is attached and this is IO and time statistics.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
Table 'Worktable'. Scan count 186880, logical reads 4740139, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'NETWORK_V3'. Scan count 1, logical reads 1857, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SDE_GEOMETRY9'. Scan count 9, logical reads 1672, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.(0 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 6033 ms, elapsed time = 4604 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.I don't know how to tune this query. I cannot change the query because this is send from ARCGIS application.
How can I remove Index spool?Thanks in advance.
-
DELETE g9
FROM AliTest2.DBO.SDE_GEOMETRY9 g9
WHERE NOT EXISTS (
SELECT v3.objectid, 0
FROM AliTest2.DBO.NETWORK_V3 v3
WHERE v3.OBJECTID = g9.GEOMETRY_ID
AND v3.SDE_STATE_ID = 0
UNION ALL
SELECT a14.OBJECTID, a14.SDE_STATE_ID
FROM AliTest2.DBO.a14 a14
WHERE a14.OBJECTID = g9.GEOMETRY_ID
AND a14.SDE_STATE_ID = g9.SDE_STATE_ID
)
OPTION(RECOMPILE)-- Tables AliTest2.DBO.NETWORK_V3 and AliTest2.DBO.a14 would both benefit from an index on SDE_STATE_ID and GEOMETRY_ID
-- like this CREATE INDEX ix_Whatever ON AliTest2.DBO.NETWORK_V3 (SDE_STATE_ID, GEOMETRY_ID)
-- If GEOMETRY_ID is sufficiently specific and there's only a few possible values for SDE_STATE_ID then this might be better:
-- CREATE INDEX ix_Whatever ON AliTest2.DBO.NETWORK_V3 (GEOMETRY_ID) INCLUDE (SDE_STATE_ID)“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
Thank you.
But in Network_V3 fields (SDE_State_ID,Geometry_ID) does not exist and this field is in the SDE_Geometry4 table.
I Create this indexcreate index IXTEST4 on sde_geometry9 (Geometry_ID,sde_State_id)
with(drop_Existing=on)
But nothing change.this is IO and time statistics
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
Table 'Worktable'. Scan count 186880, logical reads 4740139, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'NETWORK_V3'. Scan count 1, logical reads 1857, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SDE_GEOMETRY9'. Scan count 9, logical reads 1672, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.(0 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 5842 ms, elapsed time = 4280 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.and plan is attached.
Thanks
- Hamid-Sadeghian - Thursday, January 4, 2018 5:33 AM
Sorry my mistake. It will make little difference to performance, putting this index on the geometry9 table. This is the important one:
CREATE INDEX ix_Whatever ON AliTest2.DBO.NETWORK_V3 (OBJECTID)
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
thank you,
This index already exist on this table. but I think has a problem with statistics of this index.
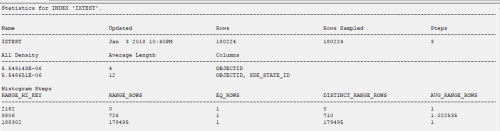
at network_v3 table, field objectID has a 1493760 distinct values but histogram for this column is :
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
1 0 1 0 1
1493760 1493758 1 1493758 1
Is this statistics correct? - Hamid-Sadeghian - Thursday, January 4, 2018 5:50 AM
If you think there's a problem with the statistics, then rebuild this index or update the statistic with FULLSCAN.
If column [objectID] is unique in the table by design, then script the index as unique.
It's possible that SQL Server is screwed by the semantics of the query - a WHERE NOT EXISTS unioning two result sets.“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
You have 1.4 million rows of distinct data and the statistics histogram shows a single row?
Actually, believe it or not, that may be right. If, the average range rows is equal to 1. Formatting there is wonky. If I'm seeing what I think I'm seeing, then you're ok. Any given value is going to return as 1. What does the header say about creation date and rows sampled?
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
I change the index to unique and update statistics with full scan.
on table a14 the statistics is wrong.
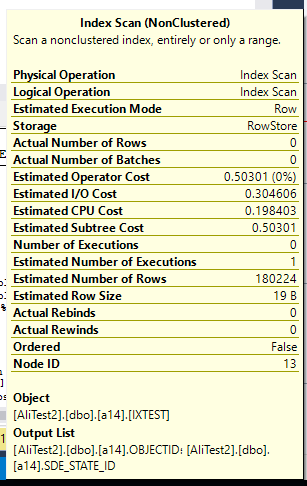
look at this picture
Actual number of row is 0 but estimated is 180224 while Statistics is update with full scan.
This is statistics for IXTest on a14 table. -
The statistics are fine. Look at the equivalent rows and the average range rows. Any value that uses the histogram is going to come back as one row. It has to. The problems are elsewhere. Instead of the EXISTS, what about doing a proper JOIN against the tables and see what that plan looks like. Currently you're getting zero filtering until after that LEFT ANTI SEMI JOIN, which is killing performance when combined with the table scans. Using regular join criteria instead of the exists might make a difference.
"The credit belongs to the man who is actually in the arena, whose face is marred by dust and sweat and blood"
- Theodore RooseveltAuthor of:
SQL Server Execution Plans
SQL Server Query Performance Tuning -
Thank you for your help, but unfortunately I cannot change the query, because this query is adhoc and send from ARCGIS application .
In my production environment , about 20 users work on this database concurrently and sometimes this query cause deadlock on server because take about 12 seconds.
If I remove union all and execute each select with outer delete statement, that execute on 1 second. but when execute with union all, take more than 10 seconds.
this plan is from my test environment that has records lower than production.
My server specification is :
HP ML-380
16 core CPU with 4 MB cache.
4 *450 GB SATA and 32 GB ram.
data file is on one HDD and ldf file is another one.
Tempdb is another HDD and has 8 data files.
SQL Server version is 2016 SP1 Enterprise and database compatibility level is 130.
trace flag 4199 is enabled. -
It's easy enough to model your query. This is sufficient:
SELECT c1.City, c1.Postcode
FROM Customer c1
WHERE NOT EXISTS (
SELECT FanID
FROM Customer c2
WHERE c2.Lastname = c1.Lastname
UNION ALL
SELECT FanID
FROM Customer c3
WHERE c3.Postcode = c1.PostCode
)So long as the table doesn't an index on Lastname and an index on PostCode, the execution plan is almost identical to the one you've posted, including the two table spools storing data from c2 and c3.
Create an index on Lastname and the spool for c2 goes away. Create an index on PostCode and the second spool goes away. The timings with and without indexes are like this:32s without indexes (table spools in plan), 1s with indexes (no table spools in the plan)
CREATE INDEX ix_Lastname ON Customer (Lastname)
CREATE INDEX ix_Postcode ON Customer (Postcode)Note that the PK is FanID and it's clustered.
If you change the query to test the subqueries separately instead of UNIONing them together, everything changes.
SELECT c1.City, c1.Postcode
FROM Customer c1
WHERE NOT EXISTS (
SELECT FanID
FROM Customer c2
WHERE c2.Lastname = c1.Lastname)
AND NOT EXISTS (
SELECT FanID
FROM Customer c3
WHERE c3.Postcode = c1.PostCode)No table spools. 2 seconds without indexes, subsecond with indexes.
Conclusion - if you cannot change the query, then create indexes which will support it.
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden -
In this index:
create index IXTEST4 on sde_geometry9 (Geometry_ID,sde_State_id)
with(drop_Existing=on)
sde_State_id must be the leading column:
(sde_State_id , Geometry_ID)
_____________
Code for TallyGenerator - Hamid-Sadeghian - Thursday, January 4, 2018 5:50 AM
Can you please post the CREATE INDEX statement?
“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Thursday, January 4, 2018 7:33 AM
These are indexes that I create on all tables in query.
Create unique index IXTEST on a14(objectid,SDE_State_id)
Create Index IXTEST2 on SDE_Geometry9 (Geometry_ID,sde_State_ID)
Create Index IXTEST3 on SDE_Geometry9 (Geometry_ID)
Create unique Index IXTEST4 on network_v3 (objectid)
Delete gm
FROM AliTest2.DBO.SDE_GEOMETRY9 as gm
WHERE NOT EXISTS ( SELECT objectid,0
FROM AliTest2.DBO.NETWORK_V3 as v3
WHERE v3.OBJECTID = gm.GEOMETRY_ID
AND gm.SDE_STATE_ID = 0
UNION ALL
SELECT a.OBJECTID,a.SDE_STATE_ID
FROM AliTest2.DBO.a14 as a
WHERE a.OBJECTID = gm.GEOMETRY_ID
AND a.SDE_STATE_ID = gm.SDE_STATE_ID)
I think this query is different from your sample because more than one table is used and two fields of tables used in where clause. -
When I change Indexes like below
Create unique index IXTEST on a14(SDE_State_id,objectid)
with(drop_existing=on)Create Index IXTEST2 on SDE_Geometry9 (sde_State_ID)
with(drop_existing=on)Create Index IXTEST3 on SDE_Geometry9 (Geometry_ID)
Create unique Index IXTEST4 on network_v3 (objectid)
with(drop_Existing=on)The plan is create on single thread but subtree cost is more than 5 but I don't know why the plan is not parallel?
Viewing 15 posts - 1 through 15 (of 34 total)
You must be logged in to reply to this topic. Login to reply