Long running insert
-
Hi Guys
I have the following query which was taking a long time to complete 30 minutes or so. After creating some indexes I have reduced it down to 7 minutes. However, I think this is still slow:
create table #tmpSolutionList (query_feasibility_location_solution_id bigint)
INSERT INTO #tmpSolutionList (query_feasibility_location_solution_id)
SELECT TOP 150000 query_feasibility_location_solution_id
FROM tbQuery_Feasibility_Location_Solution
WHERE query_feasibility_location_id IN (
SELECT query_feasibility_location_id
FROM tbQuery_Feasibility_Location
WHERE query_feasibility_id IN (
SELECT query_feasibility_id
FROM tbQuery_Feasibility
WHERE created_session_id IN (
SELECT session_id
FROM tbSession
WHERE [user_id] IN (1022, 1019)
)
)
)
AND created_dttm < '2017-06-01'
ORDER BY query_feasibility_location_solution_id
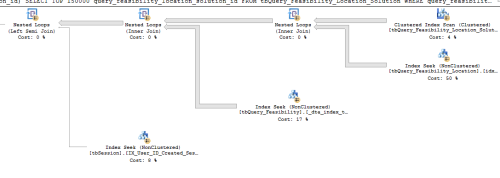
Also, I am struggling to understand why it is still doing a clustered index scan when i have already created this non clustered index: please see attached execution plan
CREATE NONCLUSTERED INDEX [Ix_tbQuery_Feasibility_Location_Solution_created_dttm_incl]
ON [dbo].[tbQuery_Feasibility_Location_Solution] ([created_dttm])
INCLUDE ([query_feasibility_location_solution_id],[query_feasibility_location_id])
Could you please help?
Many thanks in advance.
-
Using the nested subqueries is creating nested loops in the execution plan. Rewrite your query and ditch the nested subqueries.
- .
Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass -
Row estimations are off by a large factor.
Can you try doing a stats update WITH FULLSCAN on the tables involved in that query?Gail Shaw
Microsoft Certified Master: SQL Server, MVP, M.Sc (Comp Sci)
SQL In The Wild: Discussions on DB performance with occasional diversions into recoverabilityWe walk in the dark places no others will enter
We stand on the bridge and no one may pass -
ok since you are inserting into a table, you do not need the ORDER BY in the end.
You could fiddle with changing it to use EXISTS instead of IN,, but I don't know if it will help much; I was going to convert it, but i'd like to see how much removing the SORT operation will help first.
Lowell
--help us help you! If you post a question, make sure you include a CREATE TABLE... statement and INSERT INTO... statement into that table to give the volunteers here representative data. with your description of the problem, we can provide a tested, verifiable solution to your question! asking the question the right way gets you a tested answer the fastest way possible! -
Thanks Joe. Already tried the inner joins. There was not much difference.
Thanks Gail- Running the update stats with full scan now. I'll try the query again after the scans are completed. - OK, It's not that they are sub-queries, it's that they are nested like that.

SELECT TOP 150000
query_feasibility_location_solution_id
FROM
tbQuery_Feasibility_Location_Solution qfls
JOIN tbQuery_Feasibility_Location qfl
ON qfls.query_feasibility_location_id = qfl.query_feasibility_location_id
JOIN tbQuery_Feasibility gf
ON qfi.query_feasibility_id = gf.query_feasibility_id
JOIN tbSession s
ON gf.created_session_id = s.session_id
WHERE
s.user_id IN ( 1022, 1019 ) AND
created_dttm < '20170601';
/* if needed */
-- GROUP BY query_feasibility_location_solution_id -
It's a row-goal query which the optimiser hasn't quite figured out. Try this:
SELECT TOP(150000)
fls.query_feasibility_location_solution_id
FROM tbQuery_Feasibility_Location_Solution fls
WHERE fls.created_dttm < '2017-06-01'
AND EXISTS (
SELECT 1
FROM tbSession s
INNER LOOP JOIN tbQuery_Feasibility f
ON f.created_session_id = s.session_id
INNER JOIN tbQuery_Feasibility_Location fl
ON fl.query_feasibility_id = f.query_feasibility_id
WHERE s.[user_id] IN (1022, 1019)
AND fl.query_feasibility_location_id = fls.query_feasibility_location_id
)
ORDER BY fls.query_feasibility_location_solution_id“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - GilaMonster - Tuesday, July 11, 2017 2:53 PM
Updated the stats with full scan for all table except tbQuery_Feasibility_Location_Solution. This one has more than 53 million rows. It would have taken a while. Just ran it with the last sample which was 50%. Ran the query again. But do not see any difference.
Thanks Joe - The inner joins didn't make a huge difference. I still see the nested loops
Thanks Lowell - This does make sense, I was being stupid 🙂 Removed the 'order by' and used the query suggested by ChrisM ( Thanks Chris M) above without the inner loop join, it returns in 35 secs now. 🙂
Thanks Guys for all your help. I have attached the execution plan. - ss-457805 - Wednesday, July 12, 2017 9:31 AM
That's a reasonable improvement, but I think there may well be an even better improvement hiding in there.
Row-goal plans can be a bit weird, and it often helps when tuning to compare an execution plan without the row count restriction.
Can you provide one? just remove the TOP function.
Cheers“Write the query the simplest way. If through testing it becomes clear that the performance is inadequate, consider alternative query forms.” - Gail ShawFor fast, accurate and documented assistance in answering your questions, please read this article.
Understanding and using APPLY, (I) and (II) Paul White
Hidden RBAR: Triangular Joins / The "Numbers" or "Tally" Table: What it is and how it replaces a loop Jeff Moden - ChrisM@Work - Wednesday, July 12, 2017 9:56 AM
Thanks Chris. Please find the execution plan without the TOP. There's less data now as there has been a big delete that has been performed.
Viewing 11 posts - 1 through 10 (of 10 total)
You must be logged in to reply to this topic. Login to reply