Dataset - Aggregate data contained in different groups.
-
Hi,
I've create a data source which returns the data I need.
within the data source I have 3 groups - which are prefixed with "Mover_"
a simplified structure is show below:person id | starting point | ending point
00000001 |A |B
00000002 |C | F
00000003 |B | CFrom the above I've created 2 separate Tablix (matrix) to show the movement,firstly to show where the count(person) has moved to
so for starting point A we can see that 1 person has moved to B
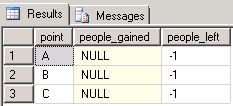
Starting Point (Left hand side)
Ending Point (Top)
__________ B _________ C _________ F
A| 1
B| 1
C | 1So B, C and F have gained people
I then have to reverse the table (swapping Ending point with Starting Point) soI can obtain a number as shown below,
whilst the first table shows which group has received individuals, the tablebelow is intended to show which group has lost individualsending point(left hand side)
Starting point (Top)
So A, B and C have lost individuals
___________A____________B___________C
B| -1
C| -1
F | -1these tables then get simplified into the 2 separate tablix below.
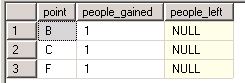
Gained Lost
A |1
B |1 B| -1
C |1 C| -1
F | -1I can display the data I need in SSRS upuntil this point.
However - I need to create a 3rd table (union) of the 2 which is based on theabove 2 (simplified tables) and I don’t know how to do it.A | 1 (only A above has 1)
B | 0 (1 in the first table - 1 in the 2nd table)
C | 0 (1 in the first table - 1 in the 2nd table)
F | -1 (nothing in the first time but -1 in the second table)I’ve tried to use lookup, but as the 2ndtable has a calculated field
“Count(person)”
and SSRS won’t allow me to do so.
I hope this is easy to understand and I thankyou for your time.
any questions, please ask
-
You're going to have to be more specific. I'm not sure what your definition really means as to what the 3rd group is calculating. Please provide CREATE TABLE and INSERT statements with sample data, and the results expected given the sample data.
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) - sgmunson - Friday, June 30, 2017 11:15 AMHi Steve,Thanks for taking the time to replybelow are the CREATE TABLE and INSERT statements with sample data
Create table #Temp
(
person_id varchar(8),
starting_point Varchar(1),
ending_point varchar(1)
)insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000001','A','B')
insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000002','C','F')
insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000003','B','C')TablixA
These is the starting_point (i.e. these have lost an individual)
select starting_point as 'point',NULL as 'people_gained',count(person_id)*-1 'people_left'
from #Temp
group by starting_point
this is the ending point, (i.e. those who have gained an individual)
select ending_point as 'point',count(person_id) 'people_gained',NULL as 'people_left'
from #Temp
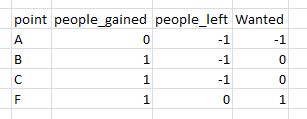
group by ending_pointresults expected - a union of the 2 previous tables with an additional column "wanted" which is a sum of people_gained and people_left
I hope this helps clarify? any questions - please let me knowThanks
Andy -
Here's one way:
SELECT x.point,
people_gained=SUM(CASE WHEN x.point_type='End' THEN 1 ELSE 0 END),
people_left =SUM(CASE WHEN x.point_type='Start' THEN -1 ELSE 0 END),
wanted =SUM(CASE WHEN x.point_type='End' THEN 1 ELSE 0 END)
+
SUM(CASE WHEN x.point_type='Start' THEN -1 ELSE 0 END)
FROM #temp
CROSS APPLY
(SELECT point_type='Start', point=starting_point
UNION ALL
SELECT point_type='End', point=ending_point
)x
GROUP BY x.point;One thing to note is that these queries (yours and mine) assume that there are no rows where the starting point and ending point are the same. That can be handled pretty easily, but it's important to note.
Cheers!
-
Create table #Temp (
person_id varchar(8),
starting_point Varchar(1),
ending_point varchar(1)
);
insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000001','A','B')
insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000002','C','F')
insert into #Temp (person_id,starting_point,ending_point) VALUES ('00000003','B','C');WITH STARTS AS (
SELECT T.starting_point, 0 - COUNT(DISTINCT person_id) AS NumLost
FROM #Temp AS T
GROUP BY T.starting_point
),
ENDS AS (SELECT T.ending_point, COUNT(DISTINCT person_id) AS NumGained
FROM #Temp AS T
GROUP BY T.ending_point
)
SELECT COALESCE(S.starting_point, E.ending_point) AS point,
ISNULL(E.NumGained, 0) AS people_gained,
ISNULL(S.NumLost, 0) AS people_left,
ISNULL(E.NumGained, 0) + ISNULL(S.NumLost, 0) AS Wanted
FROM STARTS AS S
FULL OUTER JOIN ENDS AS E
ON S.starting_point = E.ending_point
ORDER BY COALESCE(S.starting_point, E.ending_point);DROP TABLE #Temp;
Steve (aka sgmunson) 🙂 🙂 🙂
Rent Servers for Income (picks and shovels strategy) -
Steve's response reminds me of the other caveat for the query forms you used and I suggested, which is that they count multiple starts or ends for the same person each time they occur.
In other words, if person 1 has a row for starting at A, and ending at B, and then later starts at C and ends at B again, that's counted as two additions to B.
Steve's handles it the other way, only counting distinct people per start and end point. This may or may not be desired.
For example, if person 1 starts at A and ends at B, then starts at B and ends at C, and finally starts at C and ends at B again, how should that be handled?
If you only count distinct people per endpoint of B, then there's been the same number of lost and gained at B. That seems a bit odd, but it all depends on what you're trying to measure.
At any rate, if you want to change that behavior, it's as easy as removing the DISTINCT from the COUNTs.
Also, a potential simplification and performance improvement is to use GROUPING SETS instead of hitting the base table again for each aggregate and joining the results.
Something like this:
SELECT point =COALESCE(starting_point, ending_point),
people_gained=SUM(CASE WHEN starting_point IS NULL THEN x ELSE 0 END),
people_lost =0-SUM(CASE WHEN ending_point IS NULL THEN x ELSE 0 END),
wanted =SUM(CASE WHEN starting_point IS NULL THEN x ELSE 0 END)
-
SUM(CASE WHEN ending_point IS NULL THEN x ELSE 0 END)
FROM
(
SELECT starting_point,
ending_point,
x=COUNT(DISTINCT person_id)
FROM #temp
GROUP BY GROUPING SETS (starting_point,ending_point)
)x
GROUP BY COALESCE(starting_point, ending_point);As it stands, this behaves the same as Steve's. Like his, if the behavior described above is not desired, just remove the DISTINCT from the COUNT.
Cheers!
-
Hi Steve and Jacob
Thank you so much for taking the time to read my question and for your solutions
some questions had been asked by Jacob
One thing to note is that these queries (yours and mine) assume that there are no rows where the starting point and ending point are the same. That can be handled pretty easily, but it's important to note.
The source dataset will not have any records where the starting and ending points are the same.
Steve's response reminds me of the other caveat for the query forms you used and I suggested, which is that they count multiple starts or ends for the same person each time they occur.
In other words, if person 1 has a row for starting at A, and ending at B, and then later starts at C and ends at B again, that's counted as two additions to B.
Steve's handles it the other way, only counting distinct people per start and end point. This may or may not be desired.
For example, if person 1 starts at A and ends at B, then starts at B and ends at C, and finally starts at C and ends at B again, how should that be handled?
The table valued function I've created (which provides the data to SSRS) deals with this scenario when it processes the data, the result will vary based upon the date parameters, based on your example : I'll explain
if person 1 starts at A on 1st January 2017 and ends at B on 24 August 2017,
then starts at B on 25 August 2017 and ends at C on 26th September,
and finally starts at C 27 September 2017 and then expires at 31st December 2017.so if the time period is:
Jan 17 to 31st Jan then person 1 starts at A and finishes at A and so wont appear in the dataset
Jan 17 to 31st Aug then person 1 starts at A and finishes as B - so this will be returned in the dataset
Jan 17 to 30th Sep then person 1 starts at A and finishes as C - so this will be returned in the datasetIf you only count distinct people per endpoint of B, then there's been the same number of lost and gained at B. That seems a bit odd, but it all depends on what you're trying to measure.
Absolutely, I need to count everyone.
At any rate, if you want to change that behaviour, it's as easy as removing the DISTINCT from the COUNTs.Also, a potential simplification and performance improvement is to use GROUPING SETS instead of hitting the base table again for each aggregate and joining the results.
perfect - thanks for the grouping sets advice
I hope this question helps over people in the future
I've an additional question (loosely related to this) - but I will place that in a new thread
Thanks again Steve and Jacob for everything you've done so far, its very appreciated! 🙂
Viewing 7 posts - 1 through 7 (of 7 total)
You must be logged in to reply to this topic. Login to reply