Costly HASH MATCH (Aggregate)
-
I have a view,which is slow when i query a simple select statement with a `where` clause.The where clause column is indexed(`Non-clustered` index)
Here is the viewCREATE VIEW [dbo].[CurrentIncidentStatus]
AS
SELECT [incidentDetails].[IncidentStatus], [incidentDetails].[IncidentStatus_FieldValue], [incidentDetails].[IncidentStatus_Description], Report.Id ReportId, Form.Id FormId
FROM
[dbo].[IncidentDe http:// tailsPage_Incident] incidentDetails WITH (NOLOCK)
INNER JOIN [dbo].[IncidentDetailsPages] detailsPage WITH (NOLOCK)
ON incidentDetails.PageId = detailsPage.Id
INNER JOIN Form WITH (NOLOCK)
ON detailsPage.FormId = Form.Id
INNER JOIN Report WITH (NOLOCK)
ON Form.ReportId = Report.Id
LEFT OUTER JOIN dbo.IncidentDetailsPage_Supplements supplement WITH (NOLOCK)
ON detailsPage.Id = supplement.PageId
INNER JOIN
(
SELECT ReportId, Max(FormNumber) RecentFormNumber FROM
(
SELECT Report.Id ReportId, FormId, COALESCE(SupplementNumber, '0000') formNumber
FROM dbo.IncidentDetailsPages detailPage WITH (NOLOCK)
INNER JOIN Form WITH (NOLOCK)
ON detailPage.FormId = Form.Id
INNER JOIN Report WITH (NOLOCK)
ON Form.ReportId = Report.Id
INNER JOIN dbo.IncidentDetailsPage_Incident incident WITH (NOLOCK)
ON detailPage.Id = incident.PageId
LEFT OUTER JOIN dbo.IncidentDetailsPage_Supplements supplement WITH (NOLOCK)
ON detailPage.Id = supplement.PageId) FormNumbers
GROUP By ReportId) RecentForm
ON Report.Id = RecentForm.ReportId AND
RecentForm.RecentFormNumber = COALESCE(supplement.SupplementNumber, '0000')
GO
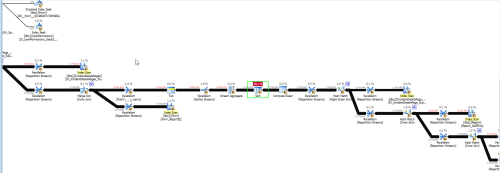
Here is the execution plan
PlanI analyzed the plan and learned that the `HASH MATCH Aggregate` is the costly operation in the plan.
I am trying to avoid/remove that HASH MATCH(Aggregate) someway.?
If any of you have experienced similar situation please give some suggestion.Additional Info:
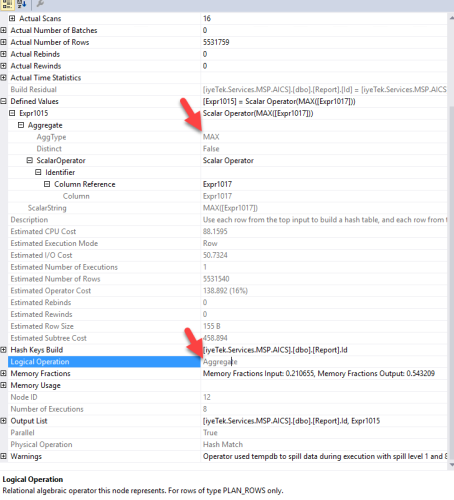
The plan says Hash key is built on Table `Report` and column `Id`.
In-fact the `Id`column is the `primary key` in the `Report` table ,so a `clustered index` is present also a `Non-clustered` index is created for Id column.
Still why Hashing is required for Report.Id?Here is the screenshot of the HASH MATCH Aggregate operation.

Info:
When i select TOP 100 or 1000 it doesn't show HASH MATCH (Aggregate).Thanks
-
Hi All,
I have used GROUP By ReportId order by ReportId OFFSET 0 ROWS to remove the HASH MATCH (Aggregate).
This removed HASH MATCH (Aggregate) and Stream Aggregate is in place now.But now in the exeuciton plan,the cost of SORT before Stream Aggregate is higher and causing trouble.Ughh.
Viewing 2 posts - 1 through 2 (of 2 total)
You must be logged in to reply to this topic. Login to reply