

Former American president Ronald Reagan loved to say “Trust, but verify”, a translation of the Russian proverb “doveryai no proveryai”. And while that may be a good attitude towards treaty negotiations between countries, it is not a good attitude towards database optimization. In the world of SQL Server, and especially when constraints are involved, the motto is: trust or verify. That is, if SQL Server knows it can trust a constraint, it may be able to reduce the work required by eliminating steps from an execution plan that would otherwise be needed as a verification.
Let’s first set up a quick test to show how this work reduction works. After that we will look at the differences between trusted and untrusted constraints, and then I will show a more realistic example of how this could affect the systems you are managing.
Setting up the example
To demonstrate the effect of foreign key constraints, let’s first set up a really simple demo database, with just two tables: Departments and Projects. Every project is owned by a single department, so there is a foreign key relationship between the two tables. Below is the script to set up these tables and populate them with a few rows of sample data.
CREATE TABLE dbo.Departments
(DeptCode char(3) NOT NULL,
DeptName varchar(35) NOT NULL,
-- Other columns,
CONSTRAINT PK_Departments
PRIMARY KEY (DeptCode)
);
CREATE TABLE dbo.Projects
(ProjectNumber int NOT NULL,
ProjectName varchar(50) NOT NULL,
DeptCode char(3) NOT NULL,
-- Other columns,
CONSTRAINT PK_Projects
PRIMARY KEY (ProjectNumber),
CONSTRAINT FK_Projects_Departments
FOREIGN KEY (DeptCode)
REFERENCES dbo.Departments(DeptCode)
);
INSERT INTO dbo.Departments
(DeptCode, DeptName)
VALUES ('ADM', 'Administration'),
('ICT', 'Information Technology') ,
('MAN', 'Management');
INSERT INTO dbo.Projects
(ProjectNumber, ProjectName, DeptCode)
VALUES (1, 'Upgrade databases', 'ICT'),
(2, 'Virtualize servers', 'ICT'),
(3, 'Scan incoming invoices', 'ADM');Based on this schema, I need to create a report that lists all project and the department in charge of it. Here is the query, and the execution plan SQL Server uses to execute it:
SELECT p.ProjectName, p.DeptCode, d.DeptName
FROM dbo.Projects AS p
INNER JOIN dbo.Departments AS d
ON d.DeptCode = p.DeptCode; 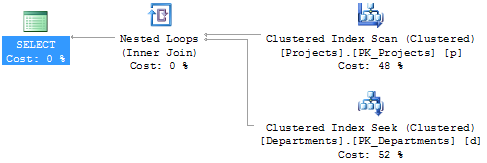
So far so good, all pretty standard. With more test data in the table the join operator will probably change to a Hash Match or a Merge Join, unless a WHERE clause in the query restricts the output. No surprises so far.
Since the people in this organization are very used to the three-letter mnemonic department codes, it is actually not necessary to include the full department name. So when requested to remove that column, because I am short on time I just do a very quick (and dirty) fix, making a note to return to the query later and see if I now still actually need the join or if I can remove it. For now, the code looks like this:
SELECT p.ProjectName, p.DeptCode--, d.DeptName
FROM dbo.Projects AS p
INNER JOIN dbo.Departments AS d
ON d.DeptCode = p.DeptCode;To my surprise, the report now suddenly runs a lot quicker. As soon as I find time I open the execution plan to see if I can see why. Here is the plan:

The query definitely specifies that two tables need to be joined, and yet the optimizer creates a plan that accesses only the Projects table. The Nested Loops and the Clustered Index Seek operators are both gone. Of course, I should have removed the join to the Departments table in the query to get the same plan, but even so – despite my limited time, the query optimizer made this optimization for me. It could do this because of the foreign key constraint.
To understand this, you have to know what possible effects a join can have. The first, and most obvious, is that data from both tables can now be used. That happened in my original query: columns from both the Projects table and the Departments table are listed side by side in the result. A second effect of a join is that a row from one table will be repeated for each matching row in the other table. In my original query, that happened for rows in the Departments table: the ICT department is in charge of two project, so the row for that department was included twice in the end result. It did not happen for the Projects table, every project is included once. The third and final effect of the join is that rows from one table that have no match in the other table are (for inner joins) removed from the result. Again, something we can see in the first query: the management department is not included in the results because no project has been assigned to them. And again, we also see that this is not the case for the projects: all projects from the Projects table are included in the results.
In the second version of the query, the only reference to a column from the Departments table is commented out, so the first effect of a join no longer applies. When the query optimizer sees this, it will check to see if the two other effects are still possible. The second effect, repeating rows from the Projects table that have multiple matches in the Departments table, can only occur when the same DeptCode exists multiple times in the Departments table, but because of the primary key on that column, this is impossible. The third effect, removing projects that have no match in the Departments table, is equally impossible: because of the foreign key constraint, SQL Server simply knows that every project references an existing department. So since none of the three possible effects of a join can apply in this version of the query, the query optimizer decides that it can safely remove the join and the associated access to the Departments table for this query.
Tampering with the Constraint
Since the query looks fast enough, I decide not to spend any extra time on it and move on to more pressing matters. The nightly data load is taking more and more time and we are close to overflowing the maintenance window, so something needs to be done here. I realize that I have a lot of foreign key constraints in my database, and checking integrity during the load incurs a lot of overhead. In order to speed up all my data load jobs, I decide to disable all foreign key constraints before the load starts. This reduces overhead, and it gives me more freedom to load the tables in any order, or even in parallel. It is safe to do this because the data comes from sources in our own systems that I know to have similar constraints, so I do not have to worry about relational integrity. Of course, I will re-enable the constraints before I allow users back into the system.
Here is how the relevant code looks for me. (As you see, I do not do any actual data load in this demo. Just disabling and re-enabling the foreign key constraint suffices to demonstrate the point of this article).
-- Disable the foreign key ALTER TABLE dbo.Projects NOCHECK CONSTRAINT FK_Projects_Departments; -- Data load happens -- Re-enable the foreign key ALTER TABLE dbo.Projects CHECK CONSTRAINT FK_Projects_Departments;
With this, the data load now runs fast enough. But I immediately start getting complaints that the project-report has slowed down, which is strange because I have not changed anything there. But when I check the execution plan for the report, I see that the original plan, that accesses both tables and joins them, is being used once more. I double check the code to see if someone removed the comment marks, but they are still there. What happened?
Losing and Gaining Trust
The answer to this can be found by querying the object view sys.foreign_keys, as follows:
SELECT name, is_disabled, is_not_trusted FROM sys.foreign_keys WHERE name = 'FK_Projects_Departments';
As you can see from the results above, the foreign key constraint is not disabled (don’t you just love those double negations?), which makes sense because I re-enabled it after the data load. That means that SQL Server will verify the constraint whenever a modification is made that could result in a violation. But the column is_not_trusted shows a 1, which implies that SQL Server does not trust the constraint anymore.
When I re-enabled the foreign key constraint, I told SQL Server to resume its process of validating new changes. But the constraint has been disabled before that, and SQL Server has no idea what I have done to the data in the tables. I already wrote above that I am 100% sure that the source of the data load is safe. But SQL Server does not know that, and SQL Server trust no one except itself.
So, since we forced SQL Server to allow us to tamper with the data without having SQL Server check it, SQL Server made a note that it is at least theoretically possible that the data that now exists in the tables violates the foreign key constraint. So it can no longer trust the constraint for existing data – which means that as far as SQL Server is concerned, it is now possible that the third effect of the join now applies. Because SQL Server can no longer trust the constraint, it now has to verify the Departments table to make sure that the department actually exists.
Luckily, there is a very simple way to remedy this. After the data load, when re-enabling the constraint, I merely have to add the WITH CHECK option, which tells SQL Server to do a full validation on the existing data. SQL Server now still does not know what I did while the constraint was disabled, but it did a full check afterwards and knows that the end result does not violate the constraint. It can safely flip the is_not_trusted bit back to 0, and now the report will once again access only the Projects table.
-- Disable the foreign key ALTER TABLE dbo.Projects NOCHECK CONSTRAINT FK_Projects_Departments; -- Data load happens -- Re-enable the foreign key ALTER TABLE dbo.Projects WITH CHECK CHECK CONSTRAINT FK_Projects_Departments;
Note that checking the full population of the table will take extra time, and I need to verify if that extra time does not exceed the time saved during the data load. Also note that if SQL Server finds any data that violates the constraint, it will raise an error and the entire active transaction will be rolled back. If there are no explicit transactions, then only the ALTER TABLE statement itself rolls back. Either way, I better make sure to have error handling in place for such a situation.
A More Realistic Example
The example above is of course a simplification to help you understand how an untrusted foreign key constraint can hurt performance. In reality, in a query as simple as the one shown, everyone would always immediately see that the Departments table is unused, and remove the unneeded join. And even in much more complex queries, the odds of not noticing that a table is no longer needed when you remove a column are not very high.
But there is one scenario, and in fact a very common scenario, where you will still run into this. That happens when working through views. Almost every database I have ever worked with uses views, and those views are then often used as the basis for queries by information workers, report builders, and other staff. In my example database, it would not at all be surprising to see a view such as this one:
CREATE VIEW dbo.AllProjects AS SELECT p.ProjectNumber, p.ProjectName, p.DeptCode, d.DeptName FROM dbo.Projects AS p INNER JOIN dbo.Departments AS d ON d.DeptCode = p.DeptCode;
And now when the BI workers create their reports, they will not write the queries as I had them above. Instead, the query will look like this:
SELECT ProjectName, DeptCode--, DeptName FROM dbo.AllProjects;
If you run this query while the foreign key constraint is trusted, you will get the execution plan that access only the Projects table. Disable the foreign key, re-enable it without adding the WITH CHECK clause and run it again – and you will get the more expensive execution plan that joins both tables. Because now SQL Server no longer trusts the constraint, it has to check if the referenced department actually exists. And in this case, if the company standard prescribes that the report has to be built on top of the view (for instance because the BI users do not get access to the base tables), there is no way to prevent that by changing the query.
The only thing you can do to make those reports fast is to ensure that the foreign key constraint is trusted.
Conclusion
Foreign keys is important for maintaining referential integrity and preventing bad data. But they can also be used by the optimizer to remove unneeded joins from execution plans.
There are sometimes good reasons to (temporarily) disable constraints. When you re-enable them, always make sure to add the WITH CHECK option, so that the optimizer can once more rely on the foreign key constraint to improve the performance of your queries.
