

Introduction
If one were to take a poll regarding the most common issues raised by the clients of marriage counselors,
my guess is that sex and money would show up pretty close to the top, if not 1-2. This data would not make
headlines in even the smallest periodical because this has been true for a long time. It is also pretty
basic. But just because it is simple and has been this way for a long time, does not mean it is
no longer true.
So it is with referential integrity. This topic is one of the cornerstones
of reliable database applications, or at least those based on relational
database management systems (RDBMS). Any quality data modeling curriculum will
cover the basics of referential integrity. Furthermore, the functionality to
enforce referential integrity was one of the key features requested by
customers for the release of Microsoft SQL Server 2000. Enforcing referential
integrity is one of the most powerful tools a DBA can use to ensure the quality
of data and long uptime of systems. The theory has been around for a long time
and the technology to enforce it keeps getting better. This is all basic 101
stuff, yet in my experience, most of the software projects that have problems
or need to be redesigned, suffer from poor database design and little or no
enforcement of referential integrity in the database.
Through out this article several terms will be used that all dance around
the topic of referential integrity and mean basically the same thing:
- Relationships (a more generic term)
- Foreign key constraints
- Referential integrity (implemented by the first two)
Some Background
First, some background for those new to this topic.
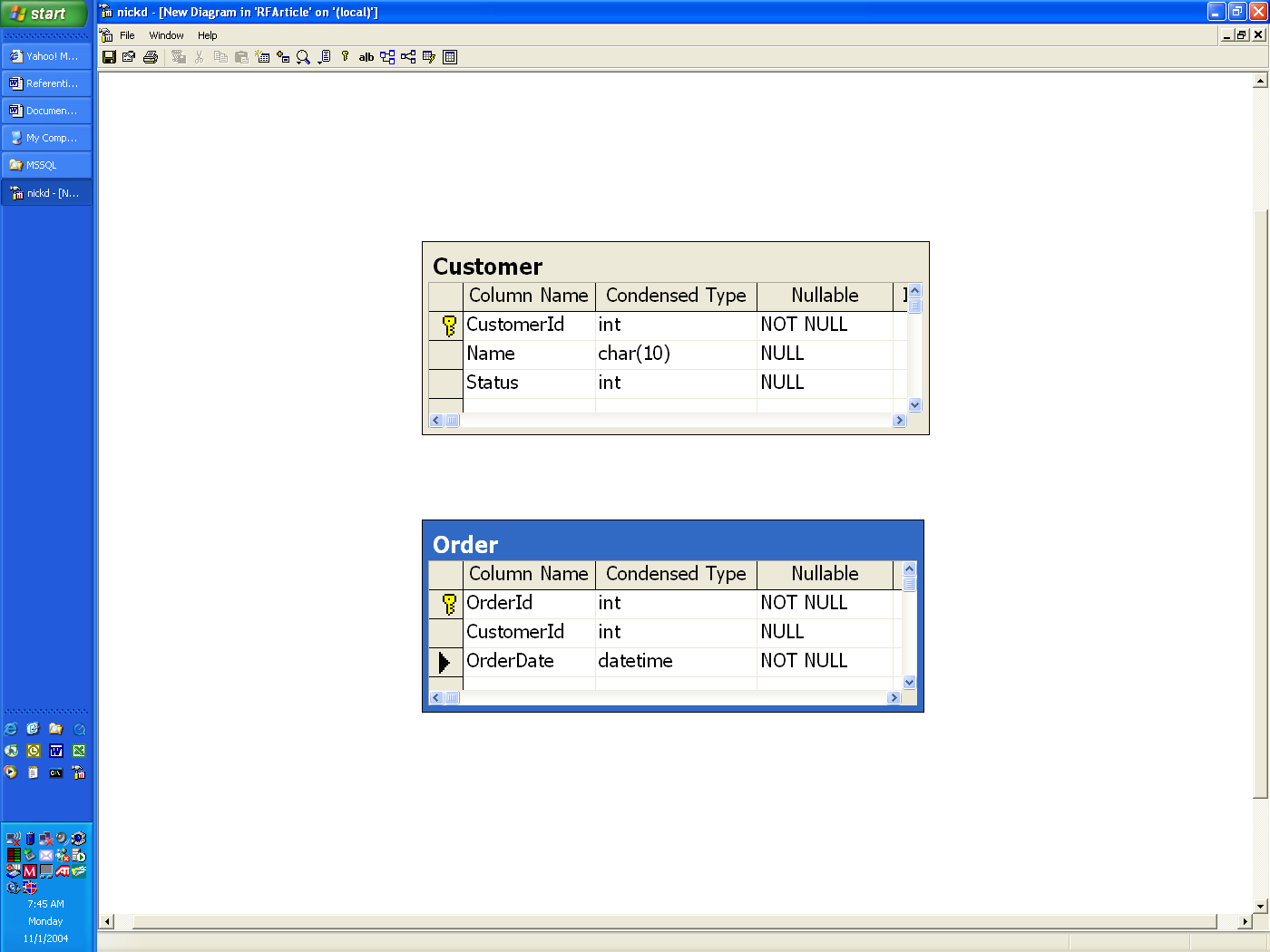
Figure 1. Customer and Order tables with no foreign key constraints.
There are two tables in Figure 1, Customer and Order. Notice there is a CustomerId column in both the Customer and Order table. In the Customer table CustomerId is the Primary Key. This means CustomerId is required and must be unique for every record in the table.
In this example, let us assume the following business requirement: orders can only be taken for valid customers. That will be interpreted to mean two things about the CustomerId in the Order table:
- It is required
- It already exists as a value in the Customer table.
As it stands, neither one of these conditions are being enforced by the database schema in Figure 1 and would need to be enforced in application code.
Some Basics
Many problem applications for which DBAs (Database Administrators) get called in to either finish or fix are in this state regarding enforcement of referential integrity in the database. As a first step in these situations it is useful to attempt to create those relationships in as many places as possible. Investigating what relationships need to be created in a database is a great way to get a good understanding of the underlying database schema. It will also help determine what is needed before any solutions can be devised. Two things will invariably happen at this point:
- Developers will insist that this step is unnecessary because their applications are already handling referential integrity in the application.
- The foreign key constraints cannot be created because underlying data violate the constraints trying to be applied. In other words there is bad data in the database. Developers are shocked at this.
Humbling as it is to admit, I have experienced both of these scenarios in applications that I have designed and or written.
Enforcing referential integrity in SQL Server is really very simple. It is a matter of creating foreign key constraints. If you are using Microsoft SQL Server, the diagram tool makes it even easier, but there is not the space in this article to explain the use of that tool. An explanation of that tool also requires a deeper understanding of relational modeling theory than what can be provided here. This is not a data modeling or architecture tutorial and only makes a case for one aspect of those domains that are very important.
In this article I will script it out the code necessary to create the constraints. It is my experience that seeing the underlying code is what allows one to “own” the skill.
Data Tables
This step makes the Order.CustomerId field required, which in this case implements part of the business rule that all orders are assigned to valid customers. If Order.CustomerId is not required, it would allow and order to be created with NO customer.
ALTER TABLE Order ALTER COLUMN CustomerId integer NOT NULL GO ALTER TABLE dbo.[Order] ADD CONSTRAINT FK_Order_Customer FOREIGN KEY ( CustomerId ) REFERENCES dbo.Customer ( CustomerId )
The code for adding a foreign key constraint is straightforward. It can be paraphrased as follows:
“Modify the Order table to ensure and all records have a CustomerId that already exists in the Customer table.”
Creating a foreign key constraint requires that the field being referenced be a Primary Key. In this case that is already true, i.e. the Customer.CustomerId is a primary key (indicated by the yellow key next to the field in the diagram). The code to create a primary key is as follows:
ALTER TABLE dbo].[Customer] ADD CONSTRAINT [PK_Customer] PRIMARY KEY ( [CustomerId] ) ON [PRIMARY]
The foreign key constraint will cause an error if there is bad data in the form of records where Order.CustomerId either does not exist in or are NULL in the Order table. Order records that fall into one of these two categories either must be deleted or updated with valid Customer.CustomerId.
There is one way to circumvent the data cleanup process and still implement the constraints. Note that I am not recommending its use. The ADD CONSTRAINT statement can be issued so that it does not check existing data but does enforce the constraint on future updates and inserts. If at all possible, avoid using this feature and fix the data now. My experience with the cleanup process (i.e. doing things right) is push back from management, users, programmers, and anyone else that does not understand the value of data integrity. The problem with using this flag is that cleanup usually does not happen later (I have a “Later is now” stamp if you want to borrow it) because of a more pressing fire that needs to be put out. The other fires are often from other applications without foreign key constraints – it does not take a brainiac to figure out this spiral of meaningless, expensive, and never ending work in these kinds of environments. In any case, if you want to play with fire, here is the code (notice the WITH NOCHECK clause in red):
ALTER TABLE dbo.[Order] WITH NOCHECK ADD CONSTRAINT FK_Order_Customer FOREIGN KEY ( CustomerId ) REFERENCES dbo.Customer ( CustomerId )
Another flavor of using the NOCHECK option is to actually delete the constraints because a particular piece of code violates the constraint. I worked on a project where a “data conversion” expert used the following logic in a data conversion effort:
- Remove a constraint that was causing a problem.
- Run the data conversion script in question.
- Add the constraint back into the database with the NOCHECK option.
Straight out of the gate the application had bad data that had to be cleaned
up. When asked why the data conversion script had been written in this manner,
the reply was “there was not time to clean the data up during
development.” The sad fact is there is not usually time to clean it up in
production, but it has to be done and costs a lot more to do it on a production
database because one has to work around users, deal with uptime, etc.
Lookup or Reference Tables
With large databases foreign key constraints can and do become numerous. Part of this happens due to the number of “reference” constraints. In Figure 2 the CustomerStatus, OrderStatus, and OrderType are all tables that have a list of valid values in them. Foreign key constraints to these tables guarantee that the Customer.CustomerStatusId, Order.OrderStatusId, and Order.OrderTypeId all contain valid values as defined by the records in these reference tables.
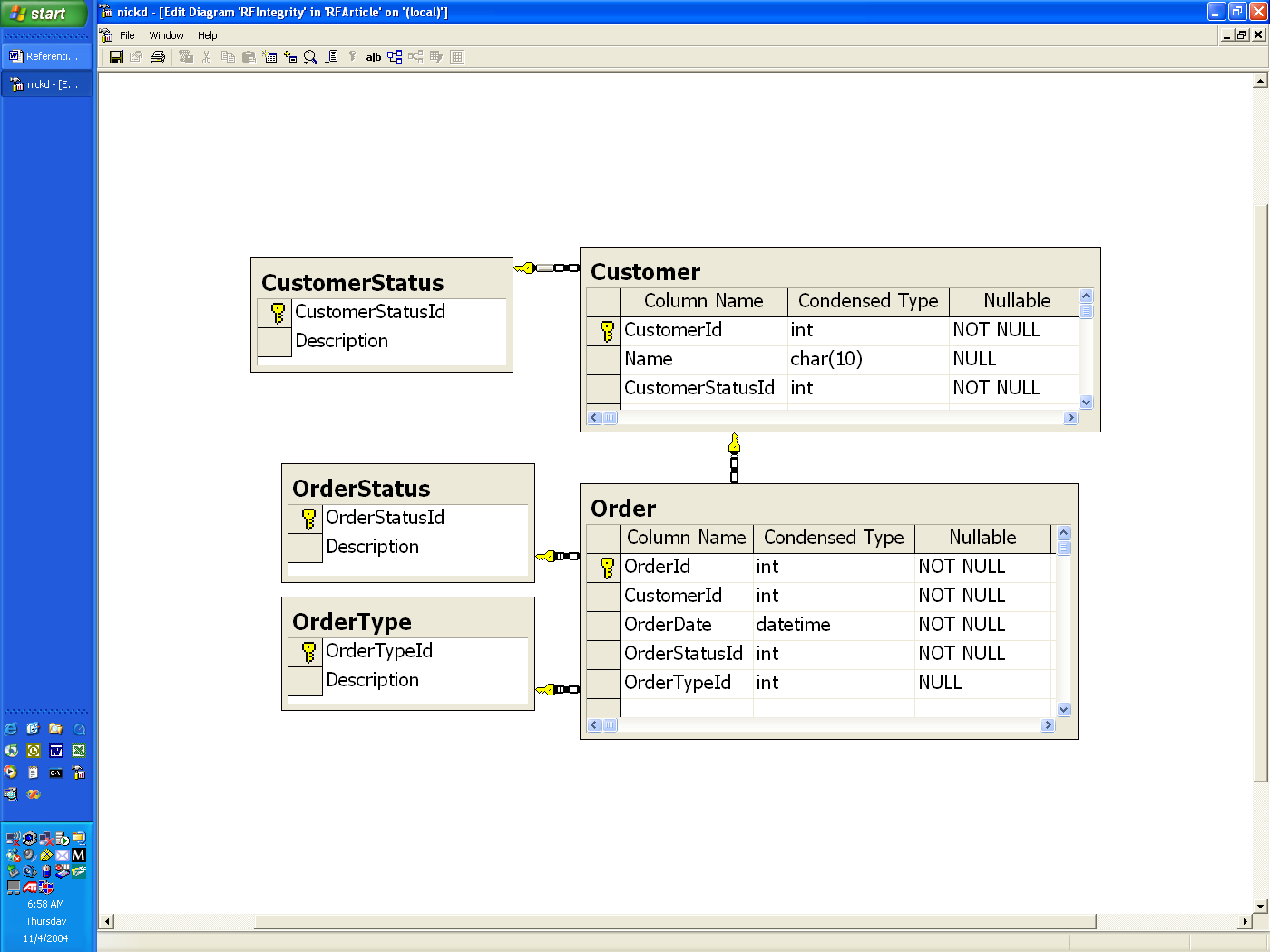
Figure 2 Multiple Reference tables
Play this scenario forward to a large enterprise application and the database schema will be littered with numerous reference tables each with a small number of rows indicating the valid values for that reference. The number of rows in each of these tables ranges from 2-10 records. If a reference table has more than 10 rows I usually look back at the design and question whether or not the database is properly normalized. Nevertheless, this methodology does guarantee data integrity at the database, which is far better than not having the constraints and jeopardizing data integrity.
However, there are two issues with this scenario:
- Any time a new status or reference fields needs to be added, it requires a new reference table.
- The proliferation of reference tables make database schema complex and cumbersome.
Starting with SQL Server 2000, there is an easier and better way. Over time you can judge for yourself and tell me what you think. Consider the schema in Figure 3.
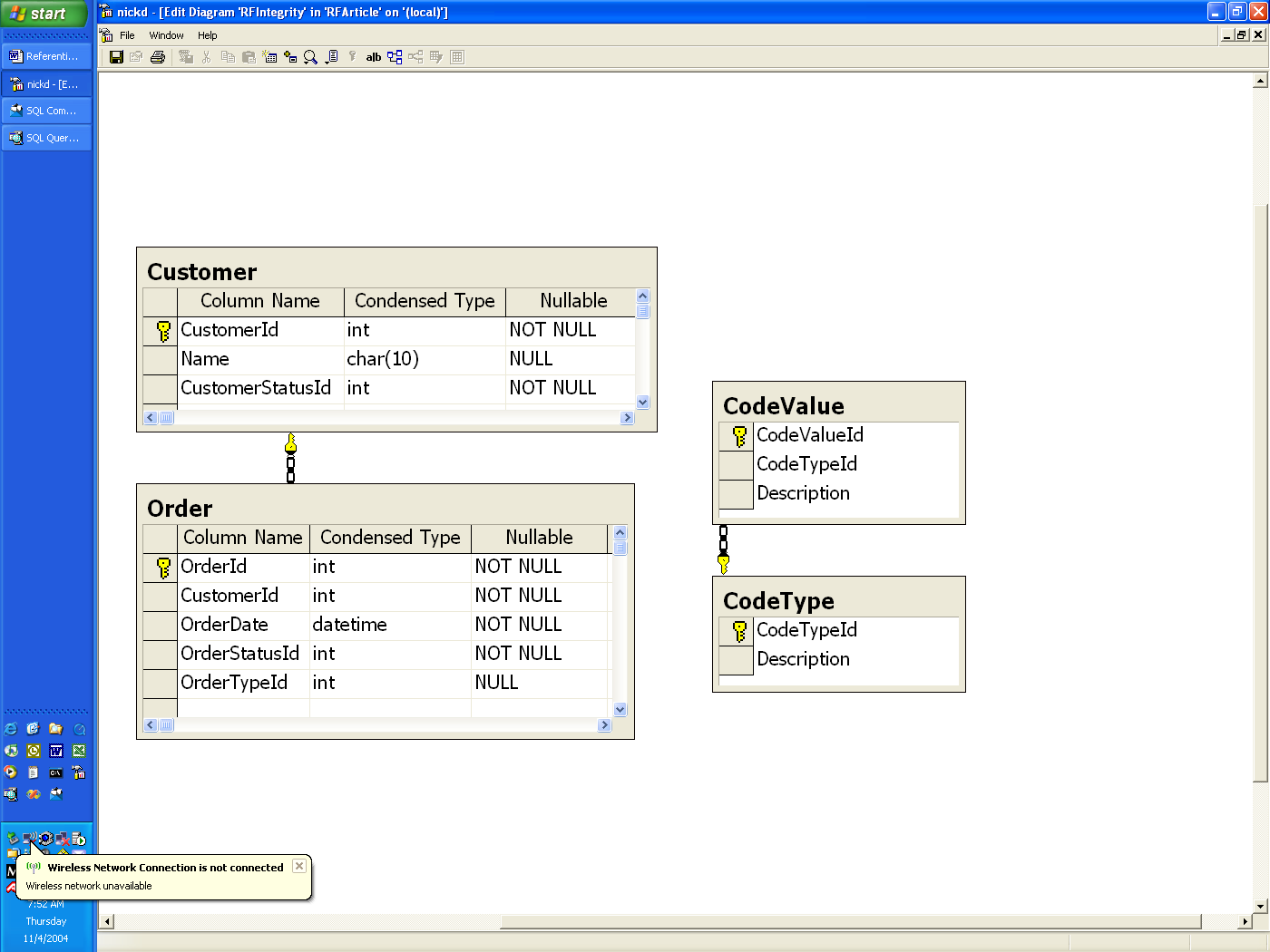
Figure 3 CodeType and CodeValue Tables
With this schema there is one record in the CodeType table for each type of reference data. In this example there are three records in this table, one each for CustomerStatusId, OrderStatusId, and OrderTypeId. The valid values for each of these reference types are stored in the CodeValue table. The CodeValue table has foreign key constraint back to the CodeType table to ensure that each record maps to a valid code type.
In SQL 7.x referential integrity for this kind of schema had to be implemented via custom triggers for every table. In SQL 2000 the use of user-defined functions makes this much cleaner. There are several steps to implementing referential integrity using this approach.
First a generic user-defined function must be created.
CREATE FUNCTION dbo.fncCodeValidate ( @CodeTypeId INTEGER, @CodeValueId INTEGER ) RETURNS INTEGER AS BEGIN DECLARE @RowCount INTEGER SELECT @RowCount = COUNT(*) FROM CodeValue WHERE CodeTypeId = @CodeTypeId AND CodeValueId = @CodeValueId RETURN ( @RowCount ) END
This function takes as arguments both the CodeTypeId and CodeValueId and returns the row count for a query against the CodeValue table.
The second step is to create the reference data in the CodeType and CodeValue tables.
----------------------------------
--Begin Insert CodeType and CodeValues
----------------------------------
declare @Identity integer
----------------------------------
--Begin Insert Customer Status Code Values
----------------------------------
insert into CodeType (Description) values ('Customer Status')
set @Identity = @@identity
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Active')
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Inactive')
----------------------------------
--End Insert Customer Status Code Values
----------------------------------
----------------------------------
--Begin Insert Order Status Code Values
----------------------------------
insert into CodeType (Description) values ('Order Status')
set @Identity = @@identity
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Open')
insert into CodeValue (CodeTypeId, Description) values (@Identity,Backordered')
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Shipped')
----------------------------------
--End Insert Order Status Code Values
----------------------------------
----------------------------------
--Begin Insert Order Type Code Values
----------------------------------
insert into CodeType (Description) values ('Order Type')
set @Identity = @@identity
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Prepaid')
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Credit Card')
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Cash')
insert into CodeValue (CodeTypeId, Description) values (@Identity, 'Account')
----------------------------------
--End Insert Order Type Code Values
----------------------------------
----------------------------------
--End Insert CodeType and CodeValues
----------------------------------
The last step is to create CHECK constraints on the tables as follows:
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [CK_Customer_CustomerStatus] CHECK ([dbo].[fncCodeValidate](1, [CustomerStatusId]) = 1) ALTER TABLE [dbo].[Order] ADD CONSTRAINT [CK_Order_OrderStatus] CHECK ([dbo].[fncCodeValidate](2,[OrderStatusId]) = 1) ALTER TABLE [dbo].[Order] ADD CONSTRAINT [CK_Order_OrderType] CHECK ([dbo].[fncCodeValidate](3, [OrderTypeId]) = 1)
Examining the syntax for the CK_Order_OrderType constraint, in plain English it says “the constraint is valid if the call to fncCodeValidate returns a value of 1.” The values passed into the function were 3 and Order.OrderTypeId. A quick look the CodeType and CodeValue table where CodeTypeId
= 3 reveals the following:
/*----------------------------- select * from CodeType where CodeTypeId = 3 -----------------------------*/CodeTypeId Description ----------- -------------------------------------------------- 3 Order Type /*----------------------------- select * from CodeValue where CodeTypeId = 3 -----------------------------*/CodeValueId CodeTypeId Description ----------- ----------- ----------------------------------------------- 6 3 Prepaid 7 3 Credit Card 8 3 Cash 9 3 Account
CodeTypeId=3 is the CodeType record for Order Type and the records in CodeValue where CodeTypeId=3 pertain to the valid values for Order Type. So a query with a particular CodeTypeId and a CodeValueId for that CodeTypeId should always return 1 and that is exactly what the function checks. If it returns anything other than 1, the function fails.
An example of inserting a record into the customer table will demonstrate how this works. Below is the data for the valid values of Customer.CustomerStatus.
/*----------------------------- select * from CodeType where CodeTypeId = 1 -----------------------------*/CodeTypeId Description ----------- -------------------------------------------------- 1 Customer Status /*----------------------------- select * from CodeValue where CodeTypeId = 1 -----------------------------*/CodeValueId CodeTypeId Description ----------- ----------- ---------------------------------------------- 1 1 Active 2 1 Inactive
This statement works fine because ‘1’ is a valid CustomerStatusId.
/*-----------------------------
insert into Customer (Name, CustomerStatusId) Values ('Jill',1)
-----------------------------*/(1 row(s) affected)
However this statement creates an error because ‘3’ is not a valid CustomerStatusId.
/*-----------------------------
insert into Customer (Name, CustomerStatusId) Values ('Tom',3)
-----------------------------*/Server: Msg 547, Level 16, State 1, Line 1
INSERT statement conflicted with COLUMN CHECK constraint 'CK_Customer_CustomerStatus'.
The conflict occurred in database 'RFArticle',table 'Customer',column 'CustomerStatusId'.
The statement has been terminated.
The beauty of this model is twofold:
- Reference tables will not clutter your database schema.
- Adding new reference data only entails adding new data the CodeType and CodeValue tables (a couple insert statements) and putting a new check constraint on the table with the foreign key reference data.
Excuses
There are a couple common themes that I have seen about why referential integrity does not get implemented in database level. In my mind, none of them are valid where data integrity is important. They are listed below along with my retort about whey they are not valid.
Error messages are not user friendly
True. Enforcing referential integrity at the database is not about being user friendly or ensuring usability. It is about database integrity. Applications should catch all these errors with user friendly messages. Where they do not, the database will catch them, hopefully in testing. If you use users in production as your test bed, then they will find these errors. The bottom line is that your data will still have integrity and that is our job as database administrators. I am not saying that usability is not important because it is. It is just outside the domain of database design and administration.
Duplication of effort
True. Enforcing referential integrity in the database is a duplication of effort if you are also going to catch these errors in application code – which you should. However, compared with the overall time spent in development effort, enforcing referential integrity at the database will prove to be a fraction of the project time. Furthermore, if these efforts prevent even one situation of corrupted data integrity, your efforts will have paid off ten fold. Cleaning up data is never fun, usually time consuming (and therefore expensive), and sometimes impossible. Depending on who encounters this “feature” (i.e. a VIP or big customer) it might take a lot of face saving on your (or worse yet, your manager’s) behalf.
Lack of knowledge and skill in designing relational databases
There are a lot of options here:
- Get some help from somebody that has the skills.
- Get some training or take the time to train yourself.
- Get a different job. You will not do yourself or your organization any favors by creating an application that does not have data integrity. You risk a lot for both your career and your organization by staying in a position where you do not have the resources to do the job either in terms of skills, training, or budget for hiring qualified help.
Unfortunately most database applications are designed by staff not trained
and or skilled at designing databases. Often this responsibility defaults to
the programmer(s) responsible for coding the application who do not have the
time, training, or skills for database design. In small shops I find that
programmers are often times the network and web administrators as well.
Essentially the database design does not get done because everything appears to
be working in development. Database design and referential integrity problems
do not show up in development. They should show up in testing but formal QA is
often not budgeted for. The problems show up when:
- Customers complain about a missed order, overcharge, or being shipped the wrong product.
- After six months of heavy use, users are constantly timing out because the application performs so poorly. This is a result of having more than just a few test records in the database.
- Management cannot use the system for any kind of decision making because data cannot be aggregated.
Any of these scenarios sound familiar?
Relational theory and technologies have been around long enough where this should not be the case. Having a programmer without the skills to design, implement, and maintain databases makes about as much sense as having an electrician plumb a construction project.
The bottom line is that only 40% of the costs for a software project are incurred during development. The other 60% occur over the life of the product after it launches. Proper relational design and implementation of referential integrity are keys to keeping the maintenance costs in this range. Without good design, the maintenance costs sky rocket –only true if the application survives launch and or a second release, More frequently, the application never gets that far and the software has to be rewritten from scratch. Now that takes time and money.
Nick Duckstein is an independent database architect and administrator in Bellingham, WA. He can be reached at nickd192@yahoo.com.
